开源大模型的使用扫盲
目录
说明
这是一篇特别浅的文章,和把大象放入冰箱分为三步一样浅。如果你已经在实际使用开源大模型了,不需要浪费时间阅读。
开源大模型开源的是什么?
DeepSeek 让开源大模型在国内彻底出圈,达到了各行各业都在关注讨论的程度。第一个有影响力的开源大模型应当是 facebook 的 Llama,后续陆续出现了更多开源大模型。DeepSeek 是第一个逼近乃至超越当时的顶尖闭源模型的开源大模型。
大模型的开源和软件代码开源不是一回事。软件代码开源是直接放出代码,任何人都可以通过公开的代码编译出一模一样的软件。大模型开源的是模型文件,也就是一个神经网络的保存文件,其中记录着神经网络的结构以及所有的参数。拥有了模型文件后,任何人都可以在带有 GPU 的机器上运行相同的神经网络,从而拥有了一个私有的本地大模型。
如果和开源软件做对照,开源大模型对照的是闭源免费软件。闭源免费软件的代码是不公开的,编译出来二进制文件免费分发,软件运行过程中也免费。开源大模型的训练过程以及训练使用的语料等是不公开的,训练的结果也就是模型文件是免费分发的。
开源大模型的文件在哪里?
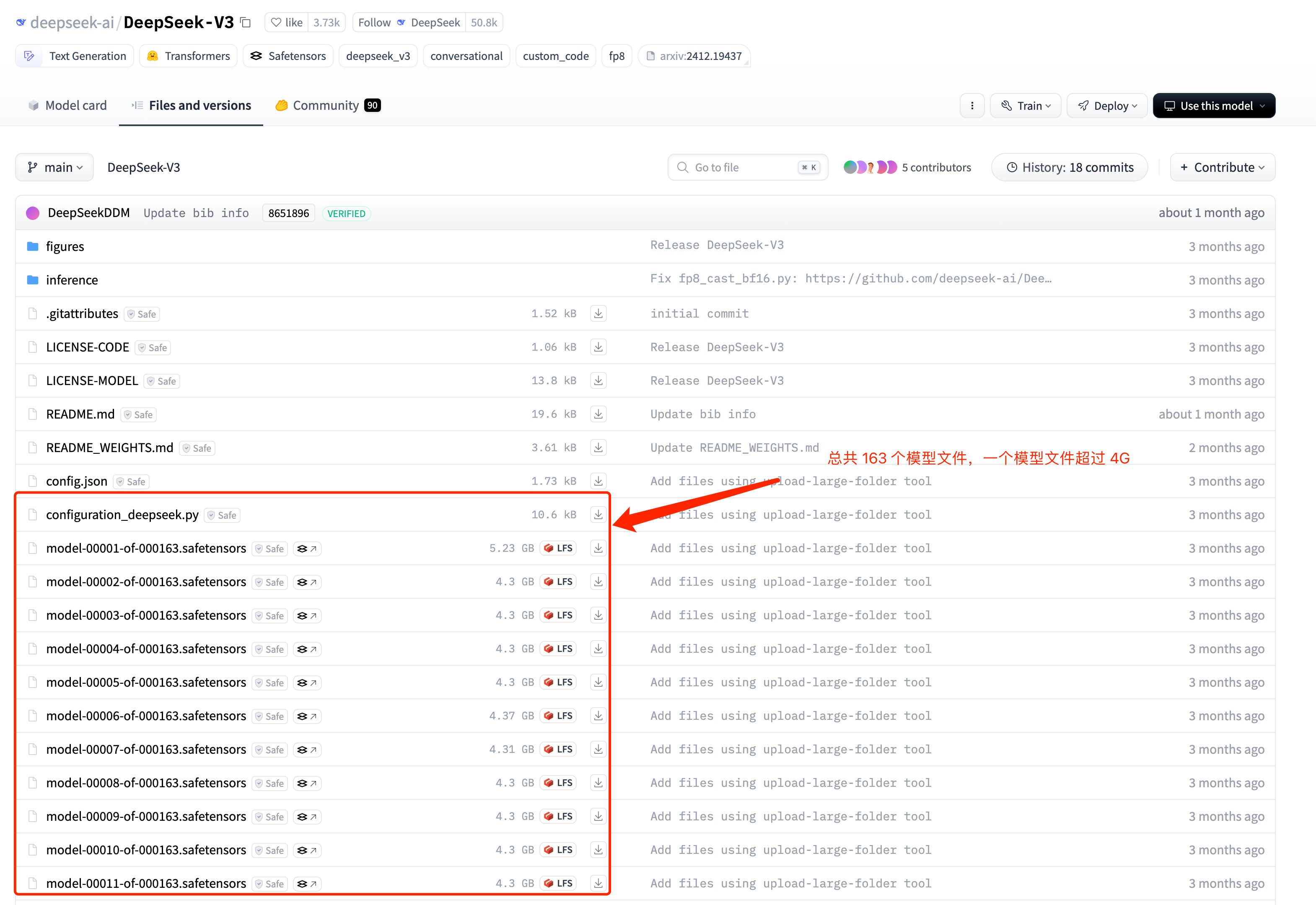
大模型文件是非常庞大,比如 DeepSeek-v3 的模型文件包含 6710 亿个神经网络参数,大小超过 700 G。庞大文件的分发就是一个问题,现在都是上传到 huggingface 网站上。 下图是 deepseekv3 的文件构成:
开源大模型怎样运行?
保存神经网络的文件格式是固定的,只要能解读文件内容可以恢复成一个在系统中运行的神经网络。当然了,现在不需要费心费力地写程序加载大模型,直接用 PyTorch、vllm、sglang 等软件加载就可以了。开源大模型训练大概率用的就是 PyTorch 框架,训练结束后导出的文件是 PyTorch支持的格式。vllm 和 sglang 是后续推出的用于加载模型、运行模型的软件,都支持开源模型使用的文件格式。
PyTorch 和 vllm/sglang 有一点区别:PyTorch 不仅可以加载运行开源的大模型,还可以在加载的大模型上继续训练。当然了,无论是 PyTorch 还是 vllm/sglang,加载运行高达 700 G 的文件,都需要有足够的硬件支持,主要就是大显存的 GPU。
PyTorch 加载开源大模型
huggingface 实现了一个名为 transformer 的 python 库。transformer library 中实现了从 huggingface 网站上下载模型文件过程,使用者只需要指定模型名称。如下:
使用模型推理:
# Use a pipeline as a high-level helper
from transformers import pipeline
messages = [
{"role": "user", "content": "Who are you?"},
]
pipe = pipeline("text-generation", model="deepseek-ai/DeepSeek-V3", trust_remote_code=True)
pipe(messages)
单纯加载模型:
# Load model directly
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/DeepSeek-V3", trust_remote_code=True)
用上面的代码加载模型得到 model 变量后,可以用 PyTorch 进行继续训练。开源大模型不开源具体训练过程,继续训练只能自己找合适的语料进行。再训练的具体方法就是 PyTorch 框架的用法,这里只普及最浅显的概念,不具体探讨怎样用 PyTorch 训练大模型。
vllm/sglang 等
vllm/sglang 等推理软件的使用更简单,直接看它们的 quickstart 文档就可以了。比如 vllm quicktstart 中加载模型以及执行批量推理的过程:
from vllm import LLM, SamplingParams
llm = LLM(model="facebook/opt-125m")
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
vllm 还支持启动一个OpenAI 接口风格的本地 apiserver:
vllm serve Qwen/Qwen2.5-1.5B-Instruct
OpenAPI 的 sdk 可以和 vllm 的 apiserver 无缝衔接:
from openai import OpenAI
# Set OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="Qwen/Qwen2.5-1.5B-Instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me a joke."},
]
)
print("Chat response:", chat_response)
OpenAPI 的接口定义方式成为一个事实的接口标准。有事实标准好处是显而易见的,要换成其它模型的时候不需要改代码。
参考

推荐阅读
Copyright @2011-2019 All rights reserved. 转载请添加原文连接,合作请加微信lijiaocn或者发送邮件: [email protected],备注网站合作
友情链接: Some Online Tools Develop by Me 系统软件 程序语言 运营经验 水库文集 网络课程 微信网文