《大型网站技术架构: 核心原理与案例分析》阅读摘录
本篇目录
说明
《大型网站技术架构:核心原理与案例分析》清晰地讲述了网站架构是如何一步步演进到现在的样子的。
负载均衡
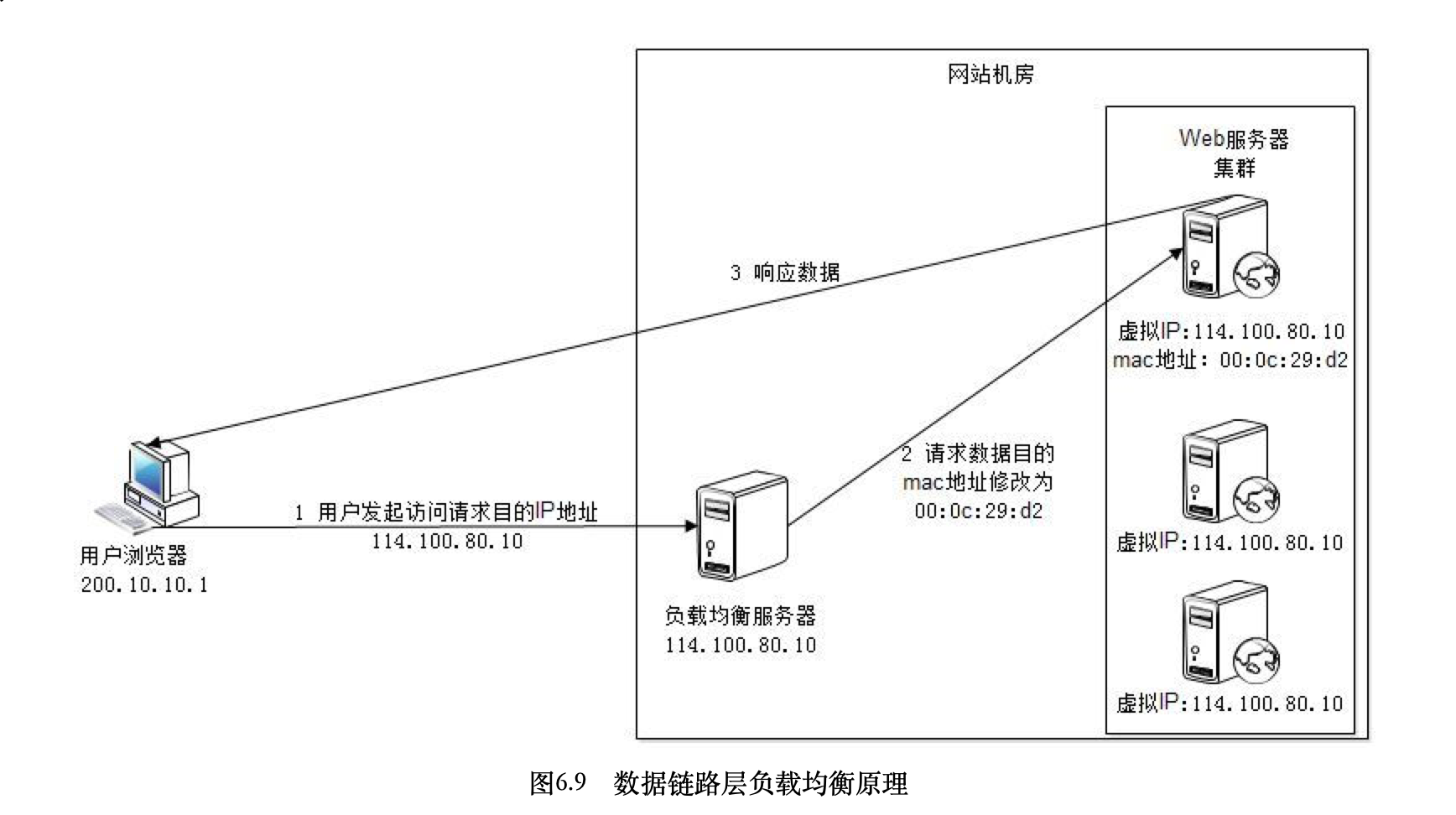
Nginx 一般用于七层负载,吞吐量有一定限制。DNS 和 Nginx 之间,接入 LVS、F5 等四层负载均衡。
DR 模式:
Session 管理方案演化
session 复制方案,复制成本高,无法大规模应用:

session 绑定方案,无法对宕机容错:

session 的 cookie 方案,无法应对客户端关闭 token 的情况:

session 服务器,:

数据备份
异步热备:

同步热备:

失效转移:

预发布

缓存:
浏览器端缓存,Expire、Cache-control。
APP客户端缓存:大促之前把 APP 需要的访问素材提前下发到客户端。
CDN 缓存:推送机制和拉取机制。
memcache 缓存:

NoSQL
一般而言 NoSQL 数据库都放弃了关系数据库的两大重要基础:
- 以关系代数为基础的结构化查询语句 SQL
- 事务一致性保证 ACID
强化了:
- 高可用
- 可伸缩性
可扩展性
事件驱动架构:


分布式服务框架:

开放API

密钥安全管理
密钥管理的目的是 防止密钥被广泛泄露:

风控系统
基于规则引擎的风控系统:

基于统计模型的风控系统:

秒杀系统

秒杀页面中加载 js 文件的 url 时添加随机编号,穿透缓存,例如:
<script type="text/javascript">
//为了兼容高版本chrome浏览器,此处不能读取缓存,故采用加随机数方式引入脚本
document.write("<s" + "cript type='text/javascript' src='//cdn.bootcss.com/jquery/3.3.1/jquery.min.js?" + Math.random() + "'></s" + "cript>");
</script>
<script type="text/javascript">
document.write("<link href='css/style.css?" + Math.random()+"' rel='stylesheet'>");
</script>
降级
这部分来自《亿级流量网站架构核心技术》
开关集中管理,通过推送机制把开关推送到应用。
服务功能降级,关闭一些不太重要的调用。
将读请求降级为只读缓存。
将写请求降级为只写缓存,异步更新 DB。
爬虫降级、风控降级。
京东单品页架构
这部分来自《亿级流量网站架构核心技术》
架构1.0:直接调用商品库获取相关的数据
架构2.0:worker 通过 MQ 接收异步通知,异步生成详情页 html,通过 rsync 同步到其它机器
架构3.0:worker 通过 MQ 接收异步通知,商品原数据异步更新到 jimdb,nginx+lua 获取数据渲染模版
参考

推荐阅读
Copyright @2011-2019 All rights reserved. 转载请添加原文连接,合作请加微信lijiaocn或者发送邮件: [email protected],备注网站合作
友情链接: Some Online Tools Develop by Me 系统软件 程序语言 运营经验 水库文集 网络课程 微信网文