系统基础
记录自认为比较重要的系统软件的知识,以及一些接触比较多的软件系统的用法。
常用工具
一些比较经常用到的软件工具的用法。
域名、IP等相关的工具
解析到 127.0.0.1 的公网域名
本站提供一个解析到 127.0.0.1 的公网域名:local.lijiaocn.com。
这个域名的好处是可以通过它访问本地的服务,比方说在本地启动一个echoserver,监听地址为 127.0.0.1:9090,可以用下面的方式访问:
$ curl local.lijiaocn.com:9090
Hostname: 57e34b409aa1
Pod Information:
-no pod information available-
Server values:
server_version=nginx: 1.13.3 - lua: 10008
Request Information:
client_address=172.17.0.1
method=GET
real path=/
query=
request_version=1.1
request_scheme=http
request_uri=http://local.lijiaocn.com:8080/
...省略...
当目标应用不支持填入 IP 地址,或者测试通过域名访问的功能时,这个域名特别有用。
dnsmasq
试验一些功能时,譬如 nginx 的透明代理 以及 kubernetes 的一些功能,需要填写可以通过域名服务器解析的域名。可以在本地用 dnsmasq 搭建一个域名服务解析服务。
在 mac 上部署 dnsmasq
- 部署 dnsmasq:
$ sudo chown -R $(whoami):admin /usr/local
$ brew install dnsmasq
- 在 /usr/local/etc/dnsmasq.conf 中添加解析,这里将 echo.example 解析到本地地址 127.0.0.1:
port 8053 # 注意,不要用 53 端口,否则需要用 root 运行
address=/echo.example/127.0.0.1
dnsmasq 监听端口最好不用 53 ,mac 的权限要求 53 端口必须用 root 身份监听,见 [Restart dnsmasq without sudo][2]。
- 启动 dnsmasq:
$ brew services start dnsmasq
验证解析:
$ dig @127.0.0.1 -p 8053 echo.example
; <<>> DiG 9.10.6 <<>> @127.0.0.1 -p 8053 echo.example
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 49022
;; flags: qr aa rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;echo.example. IN A
;; ANSWER SECTION:
echo.example. 0 IN A 127.0.0.1
;; Query time: 41 msec
;; SERVER: 127.0.0.1#8053(127.0.0.1)
;; WHEN: Wed Oct 30 17:15:03 CST 2019
;; MSG SIZE rcvd: 57
参考
HTTP 协议相关的工具
HTTP 请求回显: echoserver
下载镜像:
docker pull googlecontainer/echoserver:1.10
启动:
$ docker run -idt --name echoserver -p 9090:8080 -p 8443:8443 googlecontainer/echoserver:1.10
直接访问 echo 容器效果如下:
$ curl 127.0.0.1:9090
Hostname: 611185215d7a
Pod Information:
-no pod information available-
Server values:
server_version=nginx: 1.13.3 - lua: 10008
Request Information:
client_address=172.17.0.1
method=GET
real path=/
query=
request_version=1.1
request_scheme=http
request_uri=http://127.0.0.1:9090/
Request Headers:
accept=*/*
host=127.0.0.1:9090
user-agent=curl/7.54.0
Request Body:
-no body in request-
HTTP 请求记录: http-record
echoserver 向客户端返回接收的请求情况,http-record 不仅向客户端返回,同时在本地的标准输出打印日志。在测试流量复制功能时,复制的请求的回应会被丢弃,可以用 http-record 观察请求是否被复制。
docker run -idt --name http-record -p 9091:8080 lijiaocn/http-record:0.0.1
请求:
$ curl 127.0.0.1:9091
{
"RemoteAddr": "172.17.0.1:49802",
"Method": "GET",
"Host": "127.0.0.1:9091",
"RequestURI": "/",
"Header": {
"Accept": [
"*/*"
],
"User-Agent": [
"curl/7.54.0"
]
},
"Body": ""
}%
容器日志:
$ docker logs -f http-record
/go/src/Server/echo.go:46: {
"RemoteAddr": "172.17.0.1:49802",
"Method": "GET",
"Host": "127.0.0.1:9091",
"RequestURI": "/",
"Header": {
"Accept": [
"*/*"
],
"User-Agent": [
"curl/7.54.0"
]
},
"Body": ""
}
参考
性能测试工具
怎样压测Web应用的性能?压测工具与测量、分析方法 中的部分工具没有转移到这里。
iperf 测试网络传输性能
iperf 是一个简单常用的网络传输性能测试工具,分为服务端和客户端,iperf-doc。
安装:
# for CentOS
yum install -y epel-release
yum install -y iperf
启动 Server 端:
$ iperf -p 5001 -s
# -s: server模式
# -p: 监听端口,默认5001
服务端可以用容器启动:
$ docker run -p 5001:5001 lijiaocn/iperf-server:1.0
启动 Client 端:
$ iperf -p 5001 -c 192.168.10.2 -l 1M -t 120
#-p: server 端口,默认 5001
#-c: server 地址
#-l: 每次发送的数据的长度,默认 tcp 是 128K,UDP 是 8K
#-t: 持续的时间
netperf 更精细的网络传输测试
NetPerf 能够测试更多场景,一个很强大的网络性能测试工具,netperf doc 中有介绍。
下载源代码,编译安装:
$ yum install -y gcc make git texinfo
$ git clone https://github.com/HewlettPackard/netperf.git
$ cd netperf
$ ./autogen.sh
$ ./configure --prefix=/usr/local/
$ sudo make install
启动服务端:
$ netserver -4 -p 7777
启动客户端,客户端指定测试类型:
$ netperf -4 -H 127.0.0.1 -p 7777 -t TCP_RR
netperf 的 -t 参数支持很多场景,netperf/cases 中整理了一部分。
wrk 测试 http 服务性能
[wrk] 是一个特别高效的 http 测试工具,推荐使用。怎样压测 Web 应用的性能?压测工具与测量、分析方法 中有更多工具 。
$ git clone https://github.com/wg/wrk.git
$ cd wrk
$ make
使用方法:
$ ./wrk
Usage: wrk <options> <url>
Options:
-c, --connections <N> Connections to keep open
-d, --duration <T> Duration of test
-t, --threads <N> Number of threads to use
-s, --script <S> Load Lua script file
-H, --header <H> Add header to request
--latency Print latency statistics
--timeout <T> Socket/request timeout
-v, --version Print version details
Numeric arguments may include a SI unit (1k, 1M, 1G)
Time arguments may include a time unit (2s, 2m, 2h)
测试用例:
$ ./wrk -t 32 -c 64 -d 60s -H "Host: webshell.com" http://172.16.129.4/ping
ghz 测试 grpc 服务性能
参考
Ansible 使用手册
这里是 ansible 学习笔记 的重新,内容随着工作学习的进行不断更新。
参考
使用 ansible 操作时,用户权限相关的设置
使用 ansible 操作时,有时候需要切换到特权账号,比如 root。
切换到特权用户(root)
使用登录用户 ops 操作时,因为目标权限设置,ops 用户没有 /etc 目录的写入权限:
$ ansible -i inventories/production/hosts -u ops all -m command -a "touch /etc/a"
10.19.11.7 | FAILED | rc=1 >>
touch: cannot touch ‘/etc/a’: Permission deniednon-zero return code
10.19.117.30 | FAILED | rc=1 >>
touch: cannot touch ‘/etc/a’: Permission deniednon-zero return code
依然使用 ops 用户,加上参数 -b --become-user=root 提升到 root 用户,提升方法用 --become-method 指定,默认是 sudo:
$ ansible -i inventories/production/hosts -u ops -b --become-user=root all -m command -a "touch /etc/a"
10.19.11.7 | CHANGED | rc=0 >>
10.19.117.30 | CHANGED | rc=0 >>
使用 playbook 时,也可以在 playbook 文件中设置:
- hosts: all
gather_facts: no
become: true
become_user: root
用 ansible 操作文件和 url
将 url 指向的文件下载到指定目录
get_url_module 模块提供了该功能:
- name: Download docker repo
get_url:
url: https://download.docker.com/linux/centos/docker-ce.repo
dest: /etc/yum.repos.d/docker-ce.repo
如果 dest 指向特定用户才可以写入的目录,可能需要 提升用户权限。
参考
用 ansible 安装软件
ansible 提供了 yum-module、apt-module、apk-module等模块,用来在不同的操作系统上安装软件。
可以用下面的方法判断目标系统类型,从而导入不同的文件:
- name: install dependent packages
import_tasks: centos.yml
when: ansible_distribution == "CentOS"
用 setup 模块查看 ansible 支持的内置变量:
$ ansible -i inventories/production/hosts 10.19.11.7 -m setup
"ansible_distribution": "CentOS",
"ansible_distribution_file_parsed": true,
"ansible_distribution_file_path": "/etc/redhat-release",
"ansible_distribution_file_variety": "RedHat",
"ansible_distribution_major_version": "7",
"ansible_distribution_release": "Core",
"ansible_distribution_version": "7",
在 CentOS 上用 yum 安装
- name: Install docker
notify: Start docker
yum:
name: docker-ce
state: installed
其中 notify 指定的安装完成后执行的 handler/main.yml 中的同名操作:
- name: Start docker
systemd:
name: docker
state: started
daemon_reload: yes
enabled: yes
用 pip 安装 python 包
pip-module 调用 pip 命令安装 python 包:
- name: install docker python lib
pip:
name: docker
参考
使用 ansible 操作目标机器上的容器
docker 的安装方法见 docker 的安装。

用 ansible 安装 docker(CentOS)
在 tasks/main.yml 中写入:
- name: Download docker repo
get_url:
url: https://download.docker.com/linux/centos/docker-ce.repo
dest: /etc/yum.repos.d/docker-ce.repo
- name: Install docker
notify: Start docker
yum:
name: docker-ce
state: installed
在 handlers/main.yml 中写入:
- name: Start docker
systemd:
name: docker
state: started
daemon_reload: yes
enabled: yes
用 ansible 启动容器
docker_container 模块用来启停容器:
- name: Start pushgateway container
docker_container:
state: started
name: pushgateway-v0.9.1
image: prom/pushgateway:v0.9.1
ports:
- "9091:9091"
可能会遇到下面的错误:
TASK [pushgateway : Start pushgateway container] ***********************************************************************************************************************************************************
fatal: [10.19.11.7]: FAILED! => {"ansible_facts": {"discovered_interpreter_python": "/usr/bin/python"}, "changed": false, "msg": "Failed to import docker or docker-py (Docker SDK for Python) - No module named requests.exceptions. Try `pip install docker` or `pip install docker-py` (Python 2.6)."}
fatal: [10.19.117.30]: FAILED! => {"ansible_facts": {"discovered_interpreter_python": "/usr/bin/python"}, "changed": false, "msg": "Failed to import docker or docker-py (Docker SDK for Python) - No module named requests.exceptions. Try `pip install docker` or `pip install docker-py` (Python 2.6)."}
遇到这种情况,需要在 目标机器 上安装 docker 的 python 包:
- name: Install pip
yum:
name: python2-pip
state: installed
- name: Install docker python lib
pip:
name: docker
- name: Start pushgateway container
docker_container:
state: started
name: pushgateway-v0.9.1
image: prom/pushgateway:v0.9.1
ports:
- "9091:9091"
参考
Perf 使用手册
Perf,Performance Counters for Linux 是一个 Linux 探查工具,用来观察记录系统运行过程发生的事情。
性能调优大神 Brendan D. Gregg 在 perf example 中详细介绍了 perf 的用法,该手册的主要结构基于这篇文章,也收录了从其它各处搜集到的相关知识。
参考
Perf 技术原理:Performance Counters 子系统的配套工具
2009 年的时候,一个名为 Performance Counters 的子系统被提交到 kernel,该子系统提供“计数”事件的功能,邮件 Performance Counters for Linux 中有阐述。Perf 是该系统的配套工具。
系统调用接口
Performance Counters 子系统中的统计数据通过系统调用 perf_event_open 读取。
#include <linux/perf_event.h>
#include <linux/hw_breakpoint.h>
int perf_event_open(struct perf_event_attr *attr,
pid_t pid, int cpu, int group_fd,
unsigned long flags);
参数 pid 是目标进程号,既可以读取指定进程的事件,也可以读取所有进程的事件,详情见 linux 手册页:perf_event_open - set up performance monitoring。
权限控制
Perf Events and tool security 中介绍了设置 perf 命令权限的方法,读取内核中的统计数据,需要有响应的权限。单纯作为使用者可以不关心这个过程,发行版以及用 yum 等命令安装时,会完成相关设置。
参考
Perf 基本用法
Perf 有五个子命令,可以用 man 查看每个子命令的用法,例如 man perf-stat:
perf-stat(1), perf-top(1), perf-record(1), perf-report(1), perf-list(1)
perf 既可以获取新起的进程的事件统计,也可以获取已经存在的进程或线程的事件统计,后者用 -p、-t 指定进程号、线程号。
perf stat 执行命令并记录它的事件
运行一个命令,并记录该命令的事件信息:
perf stat [-e <EVENT> | --event=EVENT] [-a] <command>
perf stat [-e <EVENT> | --event=EVENT] [-a] — <command> [<options>]
perf top 查看特定事件的分布情况
perf top 实时显示事件在每个进程上的分布情况:
perf top [-e <EVENT> | --event=EVENT] [<options>]
perf record 将事件信息保存到文件
文件名是 perf.data:
perf record [-e <EVENT> | --event=EVENT] [-l] [-a] <command>
perf record [-e <EVENT> | --event=EVENT] [-l] [-a] — <command> [<options>]
perf report 读取文件
读取用 perf record 生成的文件:
perf report [-i <file> | --input=file]
Perf 可以获取的 PMU 事件
perf list 打印所有可以指定的事件,事件的数量非常非常多,每个子系统都有一组事件,要理解这些事件,需要对内核非常熟悉。
$ perf list
List of pre-defined events (to be used in -e):
alignment-faults [Software event]
context-switches OR cs [Software event]
cpu-clock [Software event]
cpu-migrations OR migrations [Software event]
dummy [Software event]
emulation-faults [Software event]
major-faults [Software event]
minor-faults [Software event]
page-faults OR faults [Software event]
task-clock [Software event]
msr/tsc/ [Kernel PMU event]
rNNN [Raw hardware event descriptor]
cpu/t1=v1[,t2=v2,t3 ...]/modifier [Raw hardware event descriptor]
(see 'man perf-list' on how to encode it)
mem:<addr>[/len][:access] [Hardware breakpoint]
alarmtimer:alarmtimer_cancel [Tracepoint event]
alarmtimer:alarmtimer_fired [Tracepoint event]
alarmtimer:alarmtimer_start [Tracepoint event]
alarmtimer:alarmtimer_suspend [Tracepoint event]
...
block:block_bio_backmerge [Tracepoint event]
block:block_bio_backmerge [Tracepoint event]
block:block_bio_bounce [Tracepoint event]
block:block_bio_complete [Tracepoint event]
block:block_bio_frontmerge [Tracepoint event]
block:block_bio_queue [Tracepoint event]
...
bridge:br_fdb_add [Tracepoint event]
bridge:br_fdb_external_learn_add [Tracepoint event]
bridge:br_fdb_update [Tracepoint event]
bridge:fdb_delete [Tracepoint event]
...
cgroup:cgroup_remount [Tracepoint event]
cgroup:cgroup_rename [Tracepoint event]
cgroup:cgroup_rmdir [Tracepoint event]
cgroup:cgroup_setup_root [Tracepoint event]
cgroup:cgroup_transfer_tasks [Tracepoint event]
...
clk:clk_disable [Tracepoint event]
clk:clk_disable_complete [Tracepoint event]
clk:clk_enable [Tracepoint event]
clk:clk_enable_complete [Tracepoint event]
clk:clk_prepare [Tracepoint event]
clk:clk_prepare_complete [Tracepoint event]
...
compaction:mm_compaction_begin [Tracepoint event]
compaction:mm_compaction_defer_compaction [Tracepoint event]
compaction:mm_compaction_defer_reset [Tracepoint event]
compaction:mm_compaction_deferred [Tracepoint event]
compaction:mm_compaction_end [Tracepoint event]
compaction:mm_compaction_finished [Tracepoint event]
compaction:mm_compaction_isolate_freepages [Tracepoint event]
...
context_tracking:user_enter [Tracepoint event]
context_tracking:user_exit [Tracepoint event]
...
cpuhp:cpuhp_enter [Tracepoint event]
cpuhp:cpuhp_exit [Tracepoint event]
cpuhp:cpuhp_multi_enter [Tracepoint event]
...
dma_fence:dma_fence_destroy [Tracepoint event]
dma_fence:dma_fence_emit [Tracepoint event]
dma_fence:dma_fence_enable_signal [Tracepoint event]
...
exceptions:page_fault_kernel [Tracepoint event]
exceptions:page_fault_user [Tracepoint event]
...
fib6:fib6_table_lookup [Tracepoint event]
fib:fib_table_lookup [Tracepoint event]
...
filelock:break_lease_block [Tracepoint event]
filelock:break_lease_noblock [Tracepoint event]
filelock:break_lease_unblock [Tracepoint event]
filelock:fcntl_setlk [Tracepoint event]
...
filemap:file_check_and_advance_wb_err [Tracepoint event]
filemap:filemap_set_wb_err [Tracepoint event]
filemap:mm_filemap_add_to_page_cache [Tracepoint event]
filemap:mm_filemap_delete_from_page_cache [Tracepoint event]
...
fs_dax:dax_insert_mapping [Tracepoint event]
fs_dax:dax_insert_pfn_mkwrite [Tracepoint event]
fs_dax:dax_insert_pfn_mkwrite_no_entry [Tracepoint event]
fs_dax:dax_load_hole [Tracepoint event]
...
ftrace:function [Tracepoint event]
ftrace:print [Tracepoint event]
huge_memory:mm_collapse_huge_page [Tracepoint event]
huge_memory:mm_collapse_huge_page_isolate [Tracepoint event]
huge_memory:mm_collapse_huge_page_swapin [Tracepoint event]
huge_memory:mm_khugepaged_scan_pmd [Tracepoint event]
hwmon:hwmon_attr_show [Tracepoint event]
hwmon:hwmon_attr_show_string [Tracepoint event]
hwmon:hwmon_attr_store [Tracepoint event]
hyperv:hyperv_mmu_flush_tlb_others [Tracepoint event]
hyperv:hyperv_nested_flush_guest_mapping [Tracepoint event]
hyperv:hyperv_send_ipi_mask [Tracepoint event]
i2c:i2c_read [Tracepoint event]
i2c:i2c_reply [Tracepoint event]
i2c:i2c_result [Tracepoint event]
i2c:i2c_write [Tracepoint event]
initcall:initcall_finish [Tracepoint event]
initcall:initcall_level [Tracepoint event]
initcall:initcall_start [Tracepoint event]
iommu:add_device_to_group [Tracepoint event]
iommu:attach_device_to_domain [Tracepoint event]
iommu:detach_device_from_domain [Tracepoint event]
iommu:io_page_fault [Tracepoint event]
iommu:map [Tracepoint event]
iommu:remove_device_from_group [Tracepoint event]
iommu:unmap [Tracepoint event]
irq:irq_handler_entry [Tracepoint event]
irq:irq_handler_exit [Tracepoint event]
irq:softirq_entry [Tracepoint event]
irq:softirq_exit [Tracepoint event]
irq:softirq_raise [Tracepoint event]
irq_matrix:irq_matrix_alloc [Tracepoint event]
irq_matrix:irq_matrix_alloc_managed [Tracepoint event]
kmem:kfree [Tracepoint event]
kmem:kmalloc [Tracepoint event]
kmem:kmalloc_node [Tracepoint event]
kmem:kmem_cache_alloc [Tracepoint event]
kmem:kmem_cache_alloc_node [Tracepoint event]
kmem:kmem_cache_free [Tracepoint event]
libata:ata_eh_link_autopsy [Tracepoint event]
libata:ata_eh_link_autopsy_qc [Tracepoint event]
libata:ata_qc_complete_done [Tracepoint event]
mce:mce_record [Tracepoint event]
mdio:mdio_access [Tracepoint event]
migrate:mm_migrate_pages [Tracepoint event]
module:module_free [Tracepoint event]
module:module_get [Tracepoint event]
module:module_load [Tracepoint event]
module:module_put [Tracepoint event]
module:module_request [Tracepoint event]
msr:rdpmc [Tracepoint event]
msr:read_msr [Tracepoint event]
msr:write_msr [Tracepoint event]
napi:napi_poll [Tracepoint event]
net:napi_gro_frags_entry [Tracepoint event]
net:napi_gro_receive_entry [Tracepoint event]
net:net_dev_queue [Tracepoint event]
net:net_dev_start_xmit [Tracepoint event]
nvme:nvme_async_event [Tracepoint event]
nvme:nvme_complete_rq [Tracepoint event]
nvme:nvme_setup_cmd [Tracepoint event]
oom:compact_retry [Tracepoint event]
oom:finish_task_reaping [Tracepoint event]
oom:mark_victim [Tracepoint event]
oom:oom_score_adj_update [Tracepoint event]
oom:reclaim_retry_zone [Tracepoint event]
oom:skip_task_reaping [Tracepoint event]
oom:start_task_reaping [Tracepoint event]
oom:wake_reaper [Tracepoint event]
page_isolation:test_pages_isolated [Tracepoint event]
pagemap:mm_lru_activate [Tracepoint event]
pagemap:mm_lru_insertion [Tracepoint event]
percpu:percpu_alloc_percpu [Tracepoint event]
percpu:percpu_alloc_percpu_fail [Tracepoint event]
percpu:percpu_create_chunk [Tracepoint event]
percpu:percpu_destroy_chunk [Tracepoint event]
percpu:percpu_free_percpu [Tracepoint event]
power:clock_disable [Tracepoint event]
power:clock_enable [Tracepoint event]
power:clock_set_rate [Tracepoint event]
printk:console [Tracepoint event]
qdisc:qdisc_dequeue [Tracepoint event]
random:add_device_randomness [Tracepoint event]
random:add_disk_randomness [Tracepoint event]
random:add_input_randomness [Tracepoint event]
random:credit_entropy_bits [Tracepoint event]
random:debit_entropy [Tracepoint event]
random:extract_entropy [Tracepoint event]
ras:aer_event [Tracepoint event]
ras:arm_event [Tracepoint event]
ras:mc_event [Tracepoint event]
ras:memory_failure_event [Tracepoint event]
ras:non_standard_event [Tracepoint event]
raw_syscalls:sys_enter [Tracepoint event]
raw_syscalls:sys_exit [Tracepoint event]
rcu:rcu_utilization [Tracepoint event]
regmap:regcache_drop_region [Tracepoint event]
regmap:regcache_sync [Tracepoint event]
regmap:regmap_async_complete_done [Tracepoint event]
regmap:regmap_async_complete_start [Tracepoint event]
regmap:regmap_async_io_complete [Tracepoint event]
regmap:regmap_async_write_start [Tracepoint event]
rseq:rseq_ip_fixup [Tracepoint event]
rseq:rseq_update [Tracepoint event]
rtc:rtc_alarm_irq_enable [Tracepoint event]
rtc:rtc_irq_set_freq [Tracepoint event]
rtc:rtc_irq_set_state [Tracepoint event]
rtc:rtc_read_alarm [Tracepoint event]
rtc:rtc_read_offset [Tracepoint event]
rtc:rtc_read_time [Tracepoint event]
rtc:rtc_set_alarm [Tracepoint event]
rtc:rtc_set_offset [Tracepoint event]
rtc:rtc_set_time [Tracepoint event]
rtc:rtc_timer_dequeue [Tracepoint event]
rtc:rtc_timer_enqueue [Tracepoint event]
rtc:rtc_timer_fired [Tracepoint event]
sched:sched_kthread_stop [Tracepoint event]
sched:sched_kthread_stop_ret [Tracepoint event]
sched:sched_migrate_task [Tracepoint event]
sched:sched_move_numa [Tracepoint event]
smbus:smbus_write [Tracepoint event]
sock:inet_sock_set_state [Tracepoint event]
sock:sock_exceed_buf_limit [Tracepoint event]
sock:sock_rcvqueue_full [Tracepoint event]
spi:spi_controller_busy [Tracepoint event]
spi:spi_controller_idle [Tracepoint event]
spi:spi_message_done [Tracepoint event]
spi:spi_message_start [Tracepoint event]
spi:spi_message_submit [Tracepoint event]
spi:spi_transfer_start [Tracepoint event]
spi:spi_transfer_stop [Tracepoint event]
swiotlb:swiotlb_bounced [Tracepoint event]
syscalls:sys_enter_accept [Tracepoint event]
syscalls:sys_enter_accept4 [Tracepoint event]
syscalls:sys_enter_access [Tracepoint event]
syscalls:sys_enter_acct [Tracepoint event]
task:task_newtask [Tracepoint event]
task:task_rename [Tracepoint event]
tcp:tcp_destroy_sock [Tracepoint event]
tcp:tcp_probe [Tracepoint event]
tcp:tcp_rcv_space_adjust [Tracepoint event]
tcp:tcp_receive_reset [Tracepoint event]
tcp:tcp_retransmit_skb [Tracepoint event]
tcp:tcp_retransmit_synack [Tracepoint event]
tcp:tcp_send_reset [Tracepoint event]
thermal:cdev_update [Tracepoint event]
thermal:thermal_temperature [Tracepoint event]
thermal:thermal_zone_trip [Tracepoint event]
thermal_power_allocator:thermal_power_allocator [Tracepoint event]
thermal_power_allocator:thermal_power_allocator_pid [Tracepoint event]
timer:hrtimer_cancel [Tracepoint event]
timer:hrtimer_expire_entry [Tracepoint event]
timer:hrtimer_expire_exit [Tracepoint event]
vmscan:mm_vmscan_memcg_softlimit_reclaim_begin [Tracepoint event]
vmscan:mm_vmscan_memcg_softlimit_reclaim_end [Tracepoint event]
vmscan:mm_vmscan_wakeup_kswapd [Tracepoint event]
vmscan:mm_vmscan_writepage [Tracepoint event]
vsyscall:emulate_vsyscall [Tracepoint event]
workqueue:workqueue_activate_work [Tracepoint event]
workqueue:workqueue_execute_end [Tracepoint event]
workqueue:workqueue_execute_start [Tracepoint event]
workqueue:workqueue_queue_work [Tracepoint event]
writeback:balance_dirty_pages [Tracepoint event]
writeback:bdi_dirty_ratelimit [Tracepoint event]
writeback:global_dirty_state [Tracepoint event]
writeback:sb_clear_inode_writeback [Tracepoint event]
x86_fpu:x86_fpu_copy_src [Tracepoint event]
x86_fpu:x86_fpu_dropped [Tracepoint event]
x86_fpu:x86_fpu_init_state [Tracepoint event]
x86_fpu:x86_fpu_regs_activated [Tracepoint event]
x86_fpu:x86_fpu_regs_deactivated [Tracepoint event]
x86_fpu:x86_fpu_xstate_check_failed [Tracepoint event]
xdp:xdp_cpumap_enqueue [Tracepoint event]
xdp:xdp_cpumap_kthread [Tracepoint event]
xdp:xdp_devmap_xmit [Tracepoint event]
xdp:xdp_exception [Tracepoint event]
xdp:xdp_redirect [Tracepoint event]
xdp:xdp_redirect_err [Tracepoint event]
xen:xen_mmu_set_pte [Tracepoint event]
xen:xen_mmu_set_pte_at [Tracepoint event]
xen:xen_mmu_set_pud [Tracepoint event]
xen:xen_mmu_write_cr3 [Tracepoint event]
xfs:xfs_ag_resv_alloc_extent [Tracepoint event]
xfs:xfs_ag_resv_critical [Tracepoint event]
xfs:xfs_ag_resv_free [Tracepoint event]
xfs:xfs_ag_resv_free_error [Tracepoint event]
xfs:xfs_ag_resv_free_extent [Tracepoint event]
xfs:xfs_ag_resv_init [Tracepoint event]
xfs:xfs_ag_resv_init_error [Tracepoint event]
xhci-hcd:xhci_address_ctx [Tracepoint event]
xhci-hcd:xhci_alloc_dev [Tracepoint event]
xhci-hcd:xhci_alloc_virt_device [Tracepoint event]
xhci-hcd:xhci_configure_endpoint [Tracepoint event]
xhci-hcd:xhci_dbc_alloc_request [Tracepoint event]
xhci-hcd:xhci_dbc_free_request [Tracepoint event]
xhci-hcd:xhci_dbc_gadget_ep_queue [Tracepoint event]
参考
Git 使用手册
这里是对 Git使用手册 的进一步整理,将内容分章节展示。
提交前的准备 rebase 操作和跨越多个 repo 提交的代码方法单独列出:
常用操作
参考
Git 的 rebase 操作(commit 回放)
rebase 命令将另一个分支上的修改同步到当前分支,但是和 merge 不同,rebase 修改的当前分支的 commit 之前的内容。
举例说明:
- 原始分支 A
- 基于 A 创建了分支 B
- 分支 A 作了一次提交 c1,分支 B 作了一次提交 c2
- 基于 A 对于 B 分支进行 rebase 后,分支 B 中的提交记录变成 c1 c2
执行 rebase 后,B 分支的内容等同于将 B 分支上的修改在 A 分支上重放。
rebase 会改变当前分支中的 commit id,通常在 push 之前执行 rebase 操作
rebase 的命令参数
rebase 的命令参数如下:
NAME
git-rebase - Reapply commits on top of another base tip
SYNOPSIS
git rebase [-i | --interactive] [<options>] [--exec <cmd>] [--onto <newbase>]
[<upstream> [<branch>]]
git rebase [-i | --interactive] [<options>] [--exec <cmd>] [--onto <newbase>]
--root [<branch>]
git rebase --continue | --skip | --abort | --quit | --edit-todo | --show-current-patch
如果不指定 branch,默认对当前分支进行 rebase,如果指定了 branch,先切换到指定分支,再 rebase。
基于 tag 进行 rebase
--onto 指定 rebase 回放操作的开始位置,譬如 A 分支上有 b1 b2 c1 三个 commit,--onto b2 指定在 A 分支的 b2 位置回放当前分支的 commit。我们可以用这个参数进行基于 tag 进行回放。
如果不使用 --onto,默认在 A 分支最新的 commit 上进行回放,最常遇到的情况是 A 分支上既有 release tag 之前的 commit,也有之后的 commit,我们通常需要在 release tag 的基础上回放,暂时不引用未 release 的 commit。
git rebase upstream/master --onto nginx-0.25.1
upstream/master 中的 upstream 是远程仓库,上面的命令表示在 upstream 中的 master 分支的 nginx-0.25.1 tag 上回放当前分支中的 commit。查看远程仓库的方法:
git remote -v
origin http://gitlab.XXXXX.cn/infrastructure/ingress-nginx.git (fetch)
origin http://gitlab.XXXXX.cn/infrastructure/ingress-nginx.git (push)
upstream https://github.com/kubernetes/ingress-nginx.git (fetch)
upstream https://github.com/kubernetes/ingress-nginx.git (push)
Git rebase onto a tag when master and a branch is ahead of the current commits 中讨论了这个问题。
如果 rebase 过程出现冲突
用 git status 查看冲突文件:
$ git status
rebase in progress; onto 5179893a9
You are currently rebasing branch 'nginx-0.25.0-fp' on '5179893a9'.
(fix conflicts and then run "git rebase --continue")
(use "git rebase --skip" to skip this patch)
(use "git rebase --abort" to check out the original branch)
Unmerged paths:
(use "git reset HEAD <file>..." to unstage)
(use "git add <file>..." to mark resolution)
both modified: Makefile
no changes added to commit (use "git add" and/or "git commit -a")
修改冲突文件,并提交,然后继续 rebase (git rebase --continue):
Resolve all conflicts manually, mark them as resolved with
"git add/rm <conflicted_files>", then run "git rebase --continue".
You can instead skip this commit: run "git rebase --skip".
To abort and get back to the state before "git rebase", run "git rebase --abort".
参考
git 跨 repo 操作
如果使用了一个开源的项目,并且基于这个项目开发了自己的分支,同时又希望把改动反馈到社区,就会遇到在跨 repo 操作的问题。
将 github 项目导入 gitlab
使用开源项目,通常需要把开源项目导入到自己公司的 git ,操作方法见 将github项目导入gitlab。
这里的示例情况如下,origin 是公司私有的 repo,upstream 是开源社区的 repo:
$ git remote -v
origin http://gitlab.xxxx.cn/infrastructure/ingress-nginx.git (fetch)
origin http://gitlab.xxxx.cn/infrastructure/ingress-nginx.git (push)
upstream https://github.com/kubernetes/ingress-nginx.git (fetch)
upstream https://github.com/kubernetes/ingress-nginx.git (push)
添加另一个远程仓库
如果要把改动贡献给开源社区,需要在 github 上 fork 原始项目,通过这个 fork 的 repo 提交 pr。
将 fork 的 repo,作为远程仓库加入:
git remote add lijiaocn https://github.com/lijiaocn/ingress-nginx.git
加入后,一共有三个远程仓库,分别是 github 上的 fork 分支(lijiaocn)、原始的项目(upstream)、公司私有分支(origin):
$ git remote -v
lijiaocn https://github.com/lijiaocn/ingress-nginx.git (fetch)
lijiaocn https://github.com/lijiaocn/ingress-nginx.git (push)
upstream https://github.com/kubernetes/ingress-nginx.git (fetch)
upstream https://github.com/kubernetes/ingress-nginx.git (push)
origin http://gitlab.xxxx.cn/infrastructure/ingress-nginx.git (fetch)
origin http://gitlab.xxxx.cn/infrastructure/ingress-nginx.git (push)
添加之后,还要把新的远程仓库的内容拉取到本地:
$ git fetch lijiaocn
然后才能够看到新远程仓库 lijiaocn 中的分支:
$ git branch -r
lijiaocn/gh-pages
lijiaocn/master
upstream/HEAD -> upstream/master
upstream/gh-pages
upstream/master
创建跟踪另一个远程仓库的分支
$ git branch lijiaocn_master lijiaocn/master
$ git branch -u lijiaocn/master lijiaocn_master (不是必须)
$ git branch -vv
lijiaocn_master 846ff0036 [lijiaocn/master: ahead 167] Merge pull request #4560 from Shopify/basic-auth-map
* master 846ff0036 [origin/master: ahead 165] Merge pull request #4560 from Shopify/basic-auth-map
将远程仓库 A 中的更新 rebase 到远程仓库 B 中
这里将远程仓库 upstream 中的更新同步到 lijiaocn_master 分支中:
$ git remote -v
lijiaocn https://github.com/lijiaocn/ingress-nginx.git (fetch)
lijiaocn https://github.com/lijiaocn/ingress-nginx.git (push)
upstream https://github.com/kubernetes/ingress-nginx.git (fetch)
upstream https://github.com/kubernetes/ingress-nginx.git (push)
采用 rebase 的方式,合并过程如下:
$ git fetch upstream # 将 upstream 的更新同步到本地
$ git rebase upstream/master lijiaocn_master
将另一个分支中的特定 commit 提交到当前分支
$ git checkout lijiaocn_master
$ git cherry-pick 800e5fe9dc852fb0 (800..是另一个分支中的 commit)
将本地分支推送到另一个远程仓库的 master 中
$ git checkout lijiaocn_master
...进行了一些改动 ...
$ git commit -s -m "提交..."
$ git push -u lijiaocn HEAD:master # 推送到远程仓库 lijiaocn 的 master 分支中
参考
Mac/macOS 使用手册,开发人员常用命令
Mac 几乎成为程序员的标准开发环境了,但是 MacOS 系统的命令行指令对大多数人来说,还是很陌生的,部分指令是 BSD 风格的,与 linux 的操作命令的形似而不同,也常常带来困扰。这里收集在开发过程中会经常用到的 MacOS 命令行指令。
常用软件在 Mac 上的安装和使用
必备软件
安装 brew:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)"
安装 iterm2:
下载解压,拖动到应用程序
安装oh-my-zsh:
sh -c "$(curl -fsSL https://raw.github.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"
其它软件:
brew cask install gitbook
sudo gem install bundler jekyll
brew install npm
npm install -g gitbook-cli
数据库图形工具
mysql 图形界面管理工具:sequel-pro、mysqlworkbench:
brew cask install sequel-pro mysqlworkbench
通用的数据库图形界面工具:navicat-premium
brew cask install navicat-premium
Getting Started with PostgreSQL on Mac OSX 列出了几个 postgres 的图形界面管理工具:
- Postico
- pgAdmin
postgres
PostgreSQL 好像越来越流行了。
推荐:
以前的笔记:
安装 postgres
在 Mac 上用 brew 安装:
$ brew search postgres
postgresql@11 postgresql@10 [email protected] [email protected] [email protected]
$ brew install postgresql@11
安装完成后显示操作提示:
To migrate existing data from a previous major version of PostgreSQL run:
brew postgresql-upgrade-database
postgresql@11 is keg-only, which means it was not symlinked into /usr/local,
because this is an alternate version of another formula.
If you need to have postgresql@11 first in your PATH run:
echo 'export PATH="/usr/local/opt/postgresql@11/bin:$PATH"' >> ~/.zshrc
For compilers to find postgresql@11 you may need to set:
export LDFLAGS="-L/usr/local/opt/postgresql@11/lib"
export CPPFLAGS="-I/usr/local/opt/postgresql@11/include"
For pkg-config to find postgresql@11 you may need to set:
export PKG_CONFIG_PATH="/usr/local/opt/postgresql@11/lib/pkgconfig"
To have launchd start postgresql@11 now and restart at login:
brew services start postgresql@11
Or, if you don't want/need a background service you can just run:
pg_ctl -D /usr/local/var/postgresql@11 start
设置环境变量:
echo 'export PATH="/usr/local/opt/postgresql@11/bin:$PATH"' >> ~/.zshrc
验证版本:
$ postgres -V
postgres (PostgreSQL) 11.6
命令行工具的单独安装
如果只是要从本地访问 postgres,可以只安装命令行工具:
$ brew install pgcli
...
If you need to have libpq first in your PATH run:
echo 'export PATH="/usr/local/opt/libpq/bin:$PATH"' >> ~/.zshrc
For compilers to find libpq you may need to set:
export LDFLAGS="-L/usr/local/opt/libpq/lib"
export CPPFLAGS="-I/usr/local/opt/libpq/include"
For pkg-config to find libpq you may need to set:
export PKG_CONFIG_PATH="/usr/local/opt/libpq/lib/pkgconfig"
启动 postgres
启动 postgres:
$ brew services start postgresql@11
==> Successfully started `postgresql@11` (label: homebrew.mxcl.postgresql@11)
查看状态:
$ brew services list |grep postgres
postgresql@11 started lijiao /Users/lijiao/Library/LaunchAgents/[email protected]
默认数据库文件路径:
$ ls /usr/local/var/postgresql@11
PG_VERSION pg_ident.conf pg_snapshots pg_wal
base pg_logical pg_stat pg_xact
global pg_multixact pg_stat_tmp postgresql.auto.conf
pg_commit_ts pg_notify pg_subtrans postgresql.conf
pg_dynshmem pg_replslot pg_tblspc postmaster.opts
pg_hba.conf pg_serial pg_twophase postmaster.pid
第一次登陆
本地登陆 postgres:
$ psql postgres
psql (11.6)
Type "help" for help.
postgres=#
默认创建的 role(用户):
postgres=# \du
List of roles
Role name | Attributes | Member of
-----------+------------------------------------------------------------+-----------
lijiao | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
所在的系统的当前用户会被自动创建为 postgres 的超级用户,所以在本地可以直接用 psql postgres 登陆。
创建其它用户
创建一个新用户:
create user postgresdemo with password 'password123';
在本地用新用户登陆(注意指定 -h 127.0.0.1 -p 5432):
$ psql -h 127.0.0.1 -p 5432 -U postgresdemo
Password:
psql (11.6)
Type "help" for help.
postgres=>
本地登陆时,可能无需密码就成功了,远程登陆时可能密码正确也无法登陆,这是 postgres 的认证配置导致的:
$ cat /usr/local/var/postgresql@11/pg_hba.conf |grep all
local all all trust
host all all 127.0.0.1/32 trust
host all all ::1/128 trust
local replication all trust
host replication all 127.0.0.1/32 trust
host replication all ::1/128 trust
默认对本地全部信任(trust),没有配置其它来源访问。
用下面的配置允许 postgresdemo 用户从任何地址访问所有数据库,通过密码认证:
# TYPE DATABASE USER ADDRESS METHOD
host all postgresdemo 0.0.0.0/0 password
添加配置后需要重启 postgresql,详细说明见: Postgres 新建用户怎样才能用密码登陆?
创建数据库
创建数据库并授权给 postgresdemo:
create database postgresdemo;
grant all on database postgresdemo to postgresdemo;
如果要限制该数据库的访问方式,可以在 pg_hba.conf 添加类似配置:
# TYPE DATABASE USER ADDRESS METHOD
host postgresdemo postgresdemo 0.0.0.0/0 password
数据库操作:
\list: lists all the databases in Postgres
\connect: connect to a specific database
\dt: list the tables in the currently connected database
参考
Mac/macOS 使用手册
netstat
macOS 上的 netstat 命令用来查看本机的网络连接情况,但是要注意,macOS 的 netstat 命令用法与 linux 上的 netstat 不同。譬如在 linux 中 -p 参数的意思是显示关联的进程的程序名,在 macOS 中是指定协议:
-p protocol
Show statistics about protocol, which is either a well-known name for a protocol or an alias for it.
查看路由表
netstat -nr
查看监听的端口和连接
查看 tcp 监听端口,在 linux 上是 netstat -lnt,在 macOS 中是:
$ netstat -n -a -p tcp |grep "LISTEN"
# -n: 含义与 linux 相同,显示数字
# -a: 显示所有 socket,带有这个参数,才能显示监听端口
# -p tcp: 指定 tcp 协议
#
# 最后用 grep 将监听状态的 socket 过滤出来
如下:
$ netstat -n -a -p tcp |grep "LISTEN"
tcp46 0 0 *.5002 *.* LISTEN
tcp4 0 0 127.0.0.1.51526 *.* LISTEN
tcp4 0 0 127.0.0.1.63886 *.* LISTEN
tcp46 0 0 *.80 *.* LISTEN
...
查找监听端口的进程
在 linux 上 netstat 的 -p 参数会显示连接或者 socket 所属的进程号和程序名称,macOS 的 netstat 没有类似的选项,需要用其它方法找到监听端口的进程。 lsof 是最好的选择之一,在 macOS 上的用法和在 linux 中的用法相同:
# 查找监听 80 端口的进程
$ lsof -n -i :80 |grep LISTEN
com.docke 6777 lijiao 35u IPv6 0x65955d0d6aba74bb 0t0 TCP *:http (LISTEN)
# -i,指定网络地址
使用 lsof 代替 Mac OS X 中的 netstat 查看占用端口的程序
Linux 系统知识
Linux 系统的学习笔记。
学习资料:
参考
说明
一直想系统学习 linux 网络设备,苦于没有一份能够提供完整知识大纲的资料。既然没有现成的资料,那就自己动手整理吧。
主要参考了一下资料:
- Guide to IP Layer Network Administration with Linux
- Linux Advanced Routing & Traffic Control HOWTO
- iproute2 src: man/man8
另外还参考了大量网上问答的内容,在每个知识点中以参考文献的方式给出了对应的页面链接,这里不一一列出。
环境准备
用 vagrant 启动三台虚拟机
用 vagrant 启动三台虚拟机,每台虚拟机有两个网卡,一个网卡为 NAT 模式用于联通外网,一个网卡为 Host-only Network 用于网络实验。三台虚拟机规划网址是:
Gateway:192.168.33.1
Node10:192.168.33.10
Node20:192.168.33.20
Node30:192.368.33.30
创建第一台虚拟机 Node10:
$ mkdir ubuntu10
$ cd ubuntu10
$ vagrant init ubuntu/focal64
vagrant init 会在当前目录中生成文件 Vagrantfile,编辑该文件,将其中的 config.vm.network 设置为如下内容:
# 配置虚拟机第二块网卡的网络类型以及IP地址
config.vm.network "private_network", ip: "192.168.33.10"
# 配置在 shell 提示符中展示的主机名,只是为了方便通过 shell 提示符确认当前所在的 Node
config.vm.hostname = "Node10"
然后启动虚拟机:
$ vagrant up
虚拟机启动结束后,用 vagrant ssh 进入:
$ vagrant ssh
用 ip link 看到有 enp0s3 和 enp0s8 两个网卡:
$ ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
link/ether 02:cd:6a:13:84:49 brd ff:ff:ff:ff:ff:ff
3: enp0s8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
link/ether 08:00:27:4c:de:3c brd ff:ff:ff:ff:ff:ff
用类似的方式创建 Node20 和 Node30,Vagrantfile 中的 IP 地址相应修改成 192.168.33.20 和 192.168.33.30。
实验环境验证
在 Node10 上 Ping Node20 和 Node30,确定网络联通:
vagrant@Node10$ ping -c 3 192.168.33.20
PING 192.168.33.20 (192.168.33.20) 56(84) bytes of data.
64 bytes from 192.168.33.20: icmp_seq=1 ttl=64 time=0.623 ms
64 bytes from 192.168.33.20: icmp_seq=2 ttl=64 time=1.12 ms
64 bytes from 192.168.33.20: icmp_seq=3 ttl=64 time=1.08 ms
--- 192.168.33.20 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2034ms
rtt min/avg/max/mdev = 0.623/0.940/1.119/0.224 ms
$ ping -c 3 192.168.33.30
PING 192.168.33.30 (192.168.33.30) 56(84) bytes of data.
64 bytes from 192.168.33.30: icmp_seq=1 ttl=64 time=1.43 ms
64 bytes from 192.168.33.30: icmp_seq=2 ttl=64 time=1.02 ms
64 bytes from 192.168.33.30: icmp_seq=3 ttl=64 time=0.879 ms
--- 192.168.33.30 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2005ms
rtt min/avg/max/mdev = 0.879/1.109/1.425/0.230 ms
说明
iproute2 是一组在 Linux 中进行网络设备、流量管理的工具。iproute2 的目标是取代历史更悠久的 net-tools 工具集。 iproute2 包含众多命令,在 iproute2 src: man/man8 中可以看到 iproute2 包含的工具:
arpd
bridge
lnstat
dcb
devlink
genl
ifstat
ip
rdma
routel
nstat,rtacct
rtmon
ss
tc
tipc
vdpa
部分工具包含大量子命令,比如 iproute2 的主要工具 ip 和 tc。以 ip 包含的子命令为例:
link
address
addrlabel
route
rule
neigh
ntable
tunnel
tuntap
maddress
mroute
mrule
monitor
xfrm
netns
l2tp
tcp_metrics
token
macsec
参考
说明
ip link 用于配置网络设备,包含多个子命令,在 man ip link 中可以查看详细说明。
show
set
add
delete
xstats
afstats
property
ip link show 查看网络设备属性
$ ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
link/ether 02:cd:6a:13:84:49 brd ff:ff:ff:ff:ff:ff
3: enp0s8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
link/ether 08:00:27:4c:de:3c brd ff:ff:ff:ff:ff:ff
ip link show 将网络设备的属性用统一的格式呈现出来。前面三项含义分别是设备编号、设备名称、设备状态标识(<>中的内容)。 之后都是(字段含义 字段值)的格式。以第二个设备为例,ip link 显示的内容含义如下:
2: 在 ip link 输出结果中的编号
enp0s3: 设备名称
<BROADCAST,MULTICAST,UP,LOWER_UP> 设备状态为 broadcast/multicast/up/lower_up
mtu 65536 mtu 数值为 65536
qdisc fq_codel 流量控制策略为 fa_codel
status UP 设备状态为 UP
mode DEFAULT 设备模式为 DEFAULT
group default 设备位于 default 组
qlen 1000 队列长度 1000
link/ether 02:cd:6a:13:84:49 设备物理地址
brd ff:ff:ff:ff:ff:ff broadcast 地址
设备状态标识
(参考链接:2)
Linux 网络设备有很多个状态标识,man 7 netdeivce 中列出了已经支持的状态标识。
Device flags
IFF_UP Interface is running.
IFF_BROADCAST Valid broadcast address set.
IFF_DEBUG Internal debugging flag.
IFF_LOOPBACK Interface is a loopback interface.
IFF_POINTOPOINT Interface is a point-to-point link.
IFF_RUNNING Resources allocated.
IFF_NOARP No arp protocol, L2 destination address not set.
IFF_PROMISC Interface is in promiscuous mode.
IFF_NOTRAILERS Avoid use of trailers.
IFF_ALLMULTI Receive all multicast packets.
IFF_MASTER Master of a load balancing bundle.
IFF_SLAVE Slave of a load balancing bundle.
IFF_MULTICAST Supports multicast
IFF_PORTSEL Is able to select media type via ifmap.
IFF_AUTOMEDIA Auto media selection active.
IFF_DYNAMIC The addresses are lost when the interface goes down.
IFF_LOWER_UP Driver signals L1 up (since Linux 2.6.17)
IFF_DORMANT Driver signals dormant (since Linux 2.6.17)
IFF_ECHO Echo sent packets (since Linux 2.6.25)
流量控制策略 qdisc
设备分组 group
设备可以加入到指定分组,有一些命令支持按分组进行操作,比如查看指定分组中的设备:
$ ip link show group default
分组信息记录在 /etc/iproute2/group 中,可以手动在其中添加:
$ cat /etc/iproute2/group
# device group names
0 default
广播地址 brd
(参考链接:5)
参考
- 李佶澳的博客
- ip-link-and-ip-addr-output-meaning
- linux-traffic-control_configuring-and-managing-networking
- tc-fq_codel.8
- meaning-of-brd-in-output-of-ip-commands
iptables 的使用方法
这里是对 iptables:Linux的iptables使用 的重新整理、扩充。
安装 iptables 工具
在 Debian/Ubuntu 上安装:
apt-get update
apt-get install iptables -y
iptables 原理
iptables 根植于 kernel 中的 netfilter 模块,通过 netfilter 在影响正在被内核处理的网络报文,一共有 PREROUTING、FORWARD、POSTROUTING、INPUT 和 OUTPUT 5 个干涉点,每个干涉点可以挂一串的处理规则(Chain):
INPUT OUPUT
. |
/_\ +--------+
| _|_
+--------+ \ /
| '
Router --------|> FORWARD
. | |
/_\ +--------+ |
| _|_ _|_
+---------+ \ / \ /
| ' '
PKT ---> PREROUTING POSTROUTING ---> PKT
iptables 的规则管理与作用顺序
iptables 的规则通过 5 张表管理,有的表包括所有的干涉点,有的表只包括部分干涉点:
filter:
Chain INPUT
Chain FORWARD
Chain OUTPUT
nat:
Chain PREROUTING
Chain INPUT
Chain OUTPUT
Chain POSTROUTING
mangle:
Chain PREROUTING
Chain INPUT
Chain FORWARD
Chain OUTPUT
Chain POSTROUTING
raw:
Chain PREROUTING
Chain OUTPUT
security:
Chain INPUT
Chain FORWARD
Chain OUTPUT
上面 5 张表中的 Chain 的作用顺序是固定的,贯穿了报文的处理过程,structure-of-iptables 中有非常详细的说明:
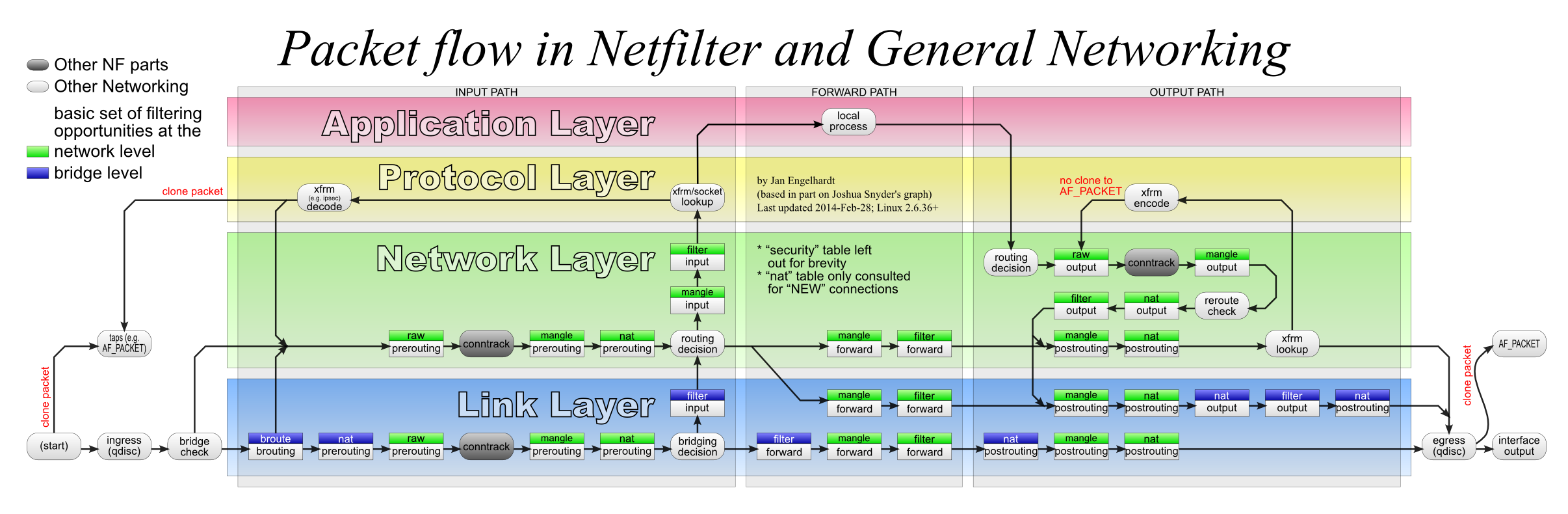
-
进入主机的报文:
raw.PREROUTING -> mangle.PREROUTING -> nat.PREROUTING -> mangle.INPUT -> filter.INPUT
-
经主机转发的报文:
raw.PREROUTING -> mangle.PREROUTING -> nat.PREROUTING -> mangle.FORWARD -> filter.FORWARD -> mangle.POSTROUTING -> nat.POSTROUTING
-
主机发出的报文:
raw.OUTPUT -> mangle.OUTPUT -> nat.OUTPUT -> filter.OUTPUT -> mangle.POSTROUTING ->nat.POSTROUTING
规则格式
规则语法如下:
rule-specification = [matches...] [target]
match = -m matchname [per-match-options]
target = -j targetname [per-target-options]
可以使用的规则参数:
-4, --ipv4
-6, --ipv6
[!] -p, --protocol protocol
可以使用:
1. tcp, udp, udplite, icmp, icmpv6,esp, ah, sctp, mh or the special keyword "all"
2. 协议号,0等同于"all"
3. /etc/protocols中列出的协议名
[!] -s, --source address[/mask][,...]
Address can be either:
a network name, a hostname, a network IP address (with /mask), or a plain IP address.
Multiple addresses can be specified, but this will expand to multiple rules (when
adding with -A), or will cause multiple rules to be deleted (with -D).
[!] -d, --destination address[/mask][,...]
-m, --match match
不同的模块有不同的参数,在下一节中单独讨论
-j, --jump target
-g, --goto chain
Unlike the --jump option return will not continue processing in this chain but instead
in the chain that called us via --jump
[!] -i, --in-interface name
[!] -o, --out-interface name
[!] -f, --fragment
This means that the rule only refers to second and further IPv4 fragments of fragmented packets.
Since there is no way to tell the source or destination ports of such a packet (or ICMP type),
such a packet will not match any rules which specify them.
When the "!" argument precedes the "-f" flag, the rule will only match head fragments, or unfragmented packets.
This option is IPv4 specific, it is not available in ip6tables.
-c, --set-counters packets bytes
This enables the administrator to initialize the packet and byte counters of a rule
(during INSERT, APPEND, REPLACE operations).
怎样用 iptables 实现各种效果,见后面章节。
参考
iptables 的报文匹配方法
iptables 规则的意思就是,对满足什么什么条件的报文,做怎样怎样的处理。第一步就是撰写报文的匹配规则,然后设置处理动作。这里收集 iptables 提供的报文匹配方法。
基本匹配
man iptables 的 PARAMETERS 中列出可以在规则中使用的参数:
-4, --ipv4
-6, --ipv6
[!] -p, --protocol protocol
[!] -s, --source address[/mask][,...]
[!] -d, --destination address[/mask][,...]
[!] -i, --in-interface name
[!] -o, --out-interface name
[!] -f, --fragment # 匹配分片报文
# This means that the rule only refers to second and
# further IPv4 fragments of fragmented packets.
支持的协议
-p 后面的 protocol 可以是数字表示的协议号,可以是下面的字符串(0 和 "all" 表示匹配所有协议),或者 /etc/protocols 中列出的协议名:
tcp, udp, udplite, icmp, icmpv6, esp, ah, sctp, mh, all
$ cat /etc/protocols
# /etc/protocols:
# $Id: protocols,v 1.11 2011/05/03 14:45:40 ovasik Exp $
#
# Internet (IP) protocols
#
# from: @(#)protocols 5.1 (Berkeley) 4/17/89
#
# Updated for NetBSD based on RFC 1340, Assigned Numbers (July 1992).
# Last IANA update included dated 2011-05-03
#
# See also http://www.iana.org/assignments/protocol-numbers
ip 0 IP # internet protocol, pseudo protocol number
hopopt 0 HOPOPT # hop-by-hop options for ipv6
icmp 1 ICMP # internet control message protocol
igmp 2 IGMP # internet group management
...省略...
扩展匹配
基本匹配的规则比较简单,只有协议、源地址、目的地址、接收网卡、发送网卡和分片报文,这几种匹配是远远不够的,iptables 的 -m 参数可以指定扩展模块,实现更复杂、更精细的匹配:
-m, --match match
iptables 提供的扩展模块非常多,种类和用法可以在 man iptables-extensions 中看到。
扩展模块分为 MATCH EXTENSIONS 和 TARGET EXTENSIONS 两类,前者用于报文匹配,后者用于报文处理。
下面是 MATCH EXTENSIONS 列表:
addrtype
ah (IPv6-specific)
ah (IPv4-specific)
bpf
cgroup
cluster
comment
connbytes
connlabel
connlimit
connmark
conntrack
cpu
dccp
devgroup
dscp
dst (IPv6-specific)
ecn
esp
eui64 (IPv6-specific)
frag (IPv6-specific)
hashlimit
hbh (IPv6-specific)
helper
hl (IPv6-specific)
icmp (IPv4-specific)
icmp6 (IPv6-specific)
iprange
ipv6header (IPv6-specific)
ipvs
length
limit
mac
mark
mh (IPv6-specific)
multiport
nfacct
osf
owner
physdev
pkttype
policy
quota
rateest
realm (IPv4-specific)
recent
rpfilter
rt (IPv6-specific)
sctp
set
socket
state
statistic
string
tcp
tcpmss
time
tos
ttl (IPv4-specific)
u32
udp
unclean (IPv4-specific)
匹配特定用户的报文
istio 中用下面的方法,对应用户 1337 启动的 envoy 进程创建的报文单独处理:
-A ISTIO_OUTPUT -m owner --uid-owner 1337 -j RETURN
-A ISTIO_OUTPUT -m owner --gid-owner 1337 -j RETURN
使用用户名也可以:
iptables -t nat -A LOCAL_PROXY -m owner --uid-owner nginx -j RETURN
参考
iptable 的报文处理动作
设置 匹配规则 后,为报文设置处理动作。
报文处理动作用下面是三个参数指定:
-j, --jump target # 使用指定的扩展模块处理报文,处理完成后返回
-g, --goto chain # 跳转到另一条规则链处理
-c, --set-counters packets bytes # 计数器重置
报文处理动作主要是用 -j 指定,-j 也可以像 -g 一样指向另一条规则链。
另一条规则链我们把它称为子链:
- 如果子链是通过
-j跳转的,子链中的 return 动作会终止子链中处理,返回到父链中继续处理 - 如果子链是通过
-g跳转的,子链中的 return 动作会终止子链中处理,且跳过父链的后续规则
Unlike the --jump option return will not continue processing in this chain but instead in the chain that called us via --jump.
基本动作
ACCEPT # 放行报文
DROP # 丢弃报文
RETURN # 返回到上一条规则链中继续处理
扩展动作
大部分处理是用扩展完成的,在 man iptables-extensions 中可以看到支持的扩展动作:
AUDIT
CHECKSUM
CLASSIFY
CLUSTERIP (IPv4-specific)
CONNMARK
CONNSECMARK
CT
DNAT
DNPT (IPv6-specific)
DSCP
ECN (IPv4-specific)
HL (IPv6-specific)
HMARK
IDLETIMER
LED
LOG
MARK
MASQUERADE
MIRROR (IPv4-specific)
NETMAP
NFLOG
NFQUEUE
NOTRACK
RATEEST
REDIRECT
REJECT (IPv6-specific)
REJECT (IPv4-specific)
SAME (IPv4-specific)
SECMARK
SET
SNAT
SNPT (IPv6-specific)
TCPMSS
TCPOPTSTRIP
TEE
TOS
TPROXY
TRACE
TTL (IPv4-specific)
ULOG (IPv4-specific)
报文重定向
REDIRECT 能够在 nat 表的 PREROUTING 和 OUTPUT 链中,将报文的目地 IP 修改为接收到这个报文的网卡的 IP,从而将报文重定向到本地的监听地址。
目标端口如果不指定则不修改,复用原始报文的目标端口:
--to-ports port[-port] # 将目标端口修改为范围内的数值
--random # 为目标端口随机取值
示例,nginx 本地透明代理:
# 新建一个规则链
iptables -t nat -N LOCAL_PROXY
# 不代理 nginx 生成的报文,防止出现 nginx 代理 nginx 的死循环
iptables -t nat -A LOCAL_PROXY -m owner --uid-owner nginx -j RETURN
# 将本地生成的目标端口为 8080 的 tcp 报文,重定向到本地的 :8080 监听地址
iptables -t nat -A LOCAL_PROXY -p tcp -m tcp --dport 8080 -j REDIRECT --to-ports 8080
参考
Linux 的网络设置
Linux 的 Local 地址的认定
127.0.0.1 默认是 local 地址,其实认定为 local 地址的 IP 是可以设置的:
- 在 mangle 表中为要被转发的报文打上标记 1
- 指定带有上述标记的报文使用路由表 100
- 将 0.0.0.0/0(即所有 IP)设置为路由表 100 的 local
iptables -t mangle -I PREROUTING -p udp --dport 5301 -j MARK --set-mark 1
ip rule add fwmark 1 lookup 100
ip route add local 0.0.0.0/0 dev lo table 100
设置上述规则后,所有目标端口为 5301 的 UDP 报文,无论目的地址是多少,都被认为是发送到给本机(local)的。监听本地地址 0.0.0.0:5301,会收到所有目标端口为 5301 的 udp 报文,无论报文的目的 IP 是不是本地 IP。
参考
Linux 的透明代理
TODO: 待试验。
透明代理是 Linux kernel 的功能,用 iptables 或者 nft 命令设置,将发送到地址 A 的报文转发给本地的另一个监听地址,监听改地址的本地进程能够获取到原始的目的地址。
代理报文的通常做法是 REDIRECT,也就是做 NAT,kernel 将报文的目标地址改写为另一个地址,同时将源地址改写为自身的地址,然后维护这两个地址的对应关系。这种方式存在一个明显的弊端,本地接收端不能或者很难获得报文的原始地址。
透明代理是另一种做法,在 kernel 上创建一张路由表,本地接收端(用户态程序)建立监听该路由表中地址的 socket。匹配规则报文被转发给本地接收端后,本地接收端可以用对应的 socket 函数获取原始的目标地址。
内核文档 Transparent proxy support 对该功能有简单说明,Linux transparent proxy support 介绍的更详细。 下面的内容主要来自第二篇文档。
准备本地代理进程
本地代理进程是一个用户态进程,创建一个监听 socket 接收新建连接和报文。监听地址可以是任意需要的 IP 地址,但需要注意,如果不是 0.0.0.0,那么需要使用 IP_TRANSPARENT 选项。认定为 local 的 IP 地址是可以配置的,见 Linux 系统知识/local 地址
本地代理进程从监听 sockert 中读取新建连接,可以自由地将接收的内容转发到另一个地址。
Socket s(AF_INET, SOCK_DGRAM, 0);
SSetsockopt(s, IPPROTO_IP, IP_TRANSPARENT, 1);
ComboAddress local("1.2.3.4", 5300);
ComboAddress remote("198.41.0.4", 53);
SBind(s, local);
SSendto(s, "hi!", remote);
透明代理能够获得原始地址,指的本地代理程序能够用 socket 函数获取报文的原始地址,TCP 协议用 getsockname() 获取 :
Socket s(AF_INET, SOCK_STREAM, 0);
SSetsockopt(s, IPPROTO_IP, IP_TRANSPARENT, 1);
ComboAddress local("127.0.0.1", 10025);
SBind(s, local);
SListen(s, 128);
ComboAddress remote(local), orig(local);
int client = SAccept(s, remote);
cout<<"Got connection from "<<remote.toStringWithPort()<<endl;
SGetsockname(client, orig);
cout<<"Original destination: "<<orig.toStringWithPort()<<endl;
UDP 协议需要用 setsockopt() 设置 IP_RECVORIGDSTADDR,然后从 recvmsg() 收到的 cmsg 中获取,索引为 IP_ORIGDSTADDR。
设置 iptables 规则
准备好本地代理进程后,还需要设置 iptables 规则,将报文转发给本地代理。
在 iptables 规则中使用名为 TPROXY 的 TARGET,也就是透明代理。下面的规则将目标端口是 25 的 TCP 报文以透明代理的方式发送到了本地地址 127.0.0.1:10025。
iptables -t mangle -A PREROUTING -p tcp --dport 25 -j TPROXY \
--tproxy-mark 0x1/0x1 --on-port 10025 --on-ip 127.0.0.1
参考
Linux 的资源管理
cgroup
- 怎样掌握 Linux 的 cgroup?资源限制机制 cgroup 学习指引与概念辨析
- cgroup(一):初级入门使用方法
- cgroup(二):资源限制 cgroup v1 和 cgroup v2 的详细介绍
- cgroup(三):cgroup controller 汇总和控制器的参数(文件接口)
参考
Linux问题分析与性能优化
个人学习笔记,记录Linux相关的知识,性能优化部分的内容主要来自极客时间出品的倪鹏飞专栏《Linux性能优化》。这里使用的操作系统是CentOS,索引了大量参考资料,为了能够查看内核文档,需要在系统上安装man-pages:
yum install -y man-pages
倪朋飞专栏《Linux性能优化》:

排查顺序
整体情况:
top/htop/atop命令查看进程/线程、CPU、内存使用情况,CPU使用情况;dstat 2查看CPU、磁盘IO、网络IO、换页、中断、切换,系统I/O状态;vmstat 2查看内存使用情况,内存状态;iostat -d -x 2查看所有磁盘的IO情况,系统I/O状态;iotop查看IO靠前的进程,系统的I/O状态;perf top查看占用CPU最多的函数,CPU使用情况;perf record -ag -- sleep 15;perf report查看CPU事件占比,CPU使用情况;sar -n DEV 2查看网卡的吞吐,网卡状态;/usr/share/bcc/tools/filetop -C查看每个文件的读写情况,系统的I/O状态;/usr/share/bcc/tools/opensnoop显示正在被打开的文件,系统的I/O状态;
进程分析,进程占用的资源:
pidstat 2 -p 进程号查看可疑进程CPU使用率变化情况;pidstat -w -p 进程号 2查看可疑进程的上下文切换情况;pidstat -d -p 进程号 2查看可疑进程的IO情况;lsof -p 进程号查看进程打开的文件;strace -f -T -tt -p 进程号显示进程发起的系统调用;
协议栈分析,连接/协议栈状态:
netstat -nat|awk '{print awk $NF}'|sort|uniq -c|sort -n查看连接状态分布;ss -ntp或者netstat -ntp查看连接队列;
方法论
RED方法:监控服务的请求数(Rate)、错误数(Errors)、响应时间(Duration)。Weave Cloud在监控微服务性能时提出的思路。
USE方法:监控系统资源的使用率(Utilization)、饱和度(Saturation)、错误数(Errors)。

性能分析工具

CPU分析思路



内存分析思路


IO分析思路



网络分析思路



基准测试工具

参考
相当一部分内容来自极客时间出品的倪鹏飞专栏《Linux性能优化》,是这个专栏的学习笔记。
另一份资料是IBM红宝书Linux性能调优指南。
此外,The Linux Documentation Project是一个非常好的资料库。
将硬件中断的处理任务分配个多个CPU:SMP affinity and proper interrupt handling in Linux
Hidden Costs of Memory Allocation
形成认识框架
认识框架(也就是知识大纲)非常重要,宏观上有了理解之后:1)才能有的放矢的深入细节,并能将繁杂多样的细节串联起来;2)在遇到问题的时候,才有能够正确的思考,有头绪、有方法、有步骤的调查问题、解决问题。
下面这张图是最宏观的图片,从上往下是“应用->库->系统调用->内核->设备”,如果发现一个应用的性能特别不理想,可以按照这个顺序查找问题所在,即先查应用、再查依赖库、然后查系统、最后查硬件。
 (图片来源:倪鹏飞,极客时间, [《Linux性能优化]》]1 )
(图片来源:倪鹏飞,极客时间, [《Linux性能优化]》]1 )
{kind=link}
Brendan Gregg制作了一份Linux性能工具图谱,这些工具可以用来定位各个方面的问题:

近几年比较流行的eBPF也提供了大量工具,eBPF的介绍见《Linux内核功能eBPF入门学习》:

注意上面两张工具图使用的分类方法(图片中间部分),这个分类就是我们要在头脑中形成记忆的认知框架,有了这个认知框架之后,在遇到性能问题的时候才会有清晰、明确的排查思路,不再抓瞎。
倪鹏飞的Linux性能优化专栏中给出的这张思维导图也是一个不错的知识框架,总共有10部分:性能监控、性能测试、应用程序、架构设计、Linux内核、文件系统、CPU、内存、网络、磁盘。

参考
Linux Kernel相关知识
对kernel了解的越多,性能分析、优化就越顺畅。
参考
动态追踪技术
主要的动态追踪工具有:ftrace、perf、eBPF(bcc)、SystemTap、sysdig。
这里只简单整理一下,以后在实践中加深了解。

如果使用的是新版本内核,eBPF和BCC是最灵活的动态追踪方法,在旧版本的内核中,因为eBPF受限,SystemTap和ftrace是比较好的选择。
ftrace与trace-cmd
ftrace通过debugfs提供用户态接口,debugfs需要事先挂载:
mount -t debugfs nodev /sys/kernel/debug
debugfs中提供多个虚拟文件:
$ ls /sys/kernel/debug/tracing
README instances set_ftrace_notrace trace_marker_raw
available_events kprobe_events set_ftrace_pid trace_options
...
ftrace用起来比较繁琐,trace-cmd简化了ftrace的使用:
yum install trace-cmd
trace-cmd用法:
$ trace-cmd record -p function_graph -g do_sys_open -O funcgraph-proc ls
$ trace-cmd report
...
ls-12418 [000] 85558.075341: funcgraph_entry: | do_sys_open() {
ls-12418 [000] 85558.075363: funcgraph_entry: | getname() {
ls-12418 [000] 85558.075364: funcgraph_entry: | getname_flags() {
ls-12418 [000] 85558.075364: funcgraph_entry: | kmem_cache_alloc() {
ls-12418 [000] 85558.075365: funcgraph_entry: | _cond_resched() {
ls-12418 [000] 85558.075365: funcgraph_entry: 0.074 us | rcu_all_qs();
ls-12418 [000] 85558.075366: funcgraph_exit: 1.143 us | }
ls-12418 [000] 85558.075366: funcgraph_entry: 0.064 us | should_failslab();
ls-12418 [000] 85558.075367: funcgraph_entry: 0.075 us | prefetch_freepointer();
ls-12418 [000] 85558.075368: funcgraph_entry: 0.085 us | memcg_kmem_put_cache();
ls-12418 [000] 85558.075369: funcgraph_exit: 4.447 us | }
ls-12418 [000] 85558.075369: funcgraph_entry: | __check_object_size() {
ls-12418 [000] 85558.075370: funcgraph_entry: 0.132 us | __virt_addr_valid();
ls-12418 [000] 85558.075370: funcgraph_entry: 0.093 us | __check_heap_object();
ls-12418 [000] 85558.075371: funcgraph_entry: 0.059 us | check_stack_object();
ls-12418 [000] 85558.075372: funcgraph_exit: 2.323 us | }
ls-12418 [000] 85558.075372: funcgraph_exit: 8.411 us | }
ls-12418 [000] 85558.075373: funcgraph_exit: 9.195 us | }
...
perf 跟踪内核函数
查看perf支持的事件:
$ perf list
List of pre-defined events (to be used in -e):
alignment-faults [Software event]
context-switches OR cs [Software event]
cpu-clock [Software event]
cpu-migrations OR migrations [Software event]
dummy [Software event]
emulation-faults [Software event]
...
添加探针:
$ perf probe --add do_sys_open
Added new event:
probe:do_sys_open (on do_sys_open)
You can now use it in all perf tools, such as:
perf record -e probe:do_sys_open -aR sleep 1
使用探针采样:
$ perf record -e probe:do_sys_open -aR sleep 10
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.148 MB perf.data (19 samples) ]
查看采样结果:
$ perf script
perf 12886 [000] 89565.879875: probe:do_sys_open: (ffffffffa807b290)
sleep 12889 [000] 89565.880362: probe:do_sys_open: (ffffffffa807b290)
sleep 12889 [000] 89565.880382: probe:do_sys_open: (ffffffffa807b290)
sleep 12889 [000] 89565.880635: probe:do_sys_open: (ffffffffa807b290)
sleep 12889 [000] 89565.880669: probe:do_sys_open: (ffffffffa807b290)
查看内核函数的参数,需要安装debufinfo:
yum --enablerepo=base-debuginfo install -y kernel-debuginfo-$(uname -r):
$ perf probe -V do_sys_open
Available variables at do_sys_open
@<do_sys_open+0>
char* filename
int dfd
int flags
struct open_flags op
umode_t mode
删除探针:
perf probe --del probe:do_sys_open
添加带参数的探针:
$ perf probe --add 'do_sys_open filename:string'
Added new event:
probe:do_sys_open (on do_sys_open with filename:string)
You can now use it in all perf tools, such as:
perf record -e probe:do_sys_open -aR sleep 1
采样结果将是这样的:
$ perf script
perf 13593 [000] 91846.053622: probe:do_sys_open: (ffffffffa807b290) filename_string="/proc/13596/status"
ls 13596 [000] 91846.053995: probe:do_sys_open: (ffffffffa807b290) filename_string="/etc/ld.so.cache"
ls 13596 [000] 91846.054011: probe:do_sys_open: (ffffffffa807b290) filename_string="/lib/x86_64-linux-gnu/libselinux.so.1"
ls 13596 [000] 91846.054066: probe:do_sys_open: (ffffffffa807b290) filename_string="/lib/x86_64-linux-gnu/libc.so.6”
...
perf 跟踪链接库函数
查看指定二进制文件(-x /bin/bash)可以追踪的所有的函数:
$ perf probe -x /bin/bash —funcs
查看函数的参数,需要安装有对应的debuginfo:
$ perf probe -x /bin/bash -V readline
Available variables at readline
@<readline+0>
char* prompt
为 /bin/bash 添加 readline 探针:
$ perf probe -x /bin/bash 'readline%return +0($retval):string’
开始采样:
$ perf record -e probe_bash:readline__return -aR sleep 5
查看结果:
$ perf script
bash 13348 [000] 93939.142576: probe_bash:readline__return: (5626ffac1610 <- 5626ffa46739) arg1="ls"
删除探针
$ perf probe --del probe_bash:readline__return
perf trace 与 trace
trace命令通过系统调用ptrace获取进程的调用系统情况,它会频繁在内核态和用户态切换,影响目标进程的性能,ptrace又会用SIGSTOP信号挂起目标进程,影响目标进程的行为。
perf trace基于内核事件,性能要好很多:
$ perf trace ls
? ( ): ls/14234 ... [continued]: execve()) = 0
0.177 ( 0.013 ms): ls/14234 brk( ) = 0x555d96be7000
0.224 ( 0.014 ms): ls/14234 access(filename: 0xad98082 ) = -1 ENOENT No such file or directory
0.248 ( 0.009 ms): ls/14234 access(filename: 0xad9add0, mode: R ) = -1 ENOENT No such file or directory
0.267 ( 0.012 ms): ls/14234 openat(dfd: CWD, filename: 0xad98428, flags: CLOEXEC ) = 3
0.288 ( 0.009 ms): ls/14234 fstat(fd: 3</usr/lib/locale/C.UTF-8/LC_NAME>, statbuf: 0x7ffd2015f230 ) = 0
0.305 ( 0.011 ms): ls/14234 mmap(len: 45560, prot: READ, flags: PRIVATE, fd: 3 ) = 0x7efe0af92000
0.324 Dockerfile test.sh
( 0.008 ms): ls/14234 close(fd: 3</usr/lib/locale/C.UTF-8/LC_NAME> ) = 0
...
eBPF和BCC
eBPF以及BCC的原理和用途,以及BCC系列工具的用法:
- Linux内核功能eBPF入门学习(一):BPF、eBPF、BCC等基本概念
- Linux内核功能eBPF入门学习(二):BCC中的eBPF应用与bpftrace等
- BCC Tutorial
- BCC Python Developer Tutorial
- BPF Features by Linux Kernel Version

CentOS中用yum直接安装,有协议额
yum install bcc-tools
命令安装在/usr/share/bcc/tools/中:
$ ls /usr/share/bcc/tools/
argdist dbstat javacalls offcputime rubyobjnew tcplife
bashreadline dcsnoop javaflow offwaketime rubystat tcpretrans
biolatency dcstat javagc oomkill runqlat tcpstates
如果遇到下面的错误,说明内核版本太低,不支持相关特性:
[root@prod-k8s-node-138-127 phops]# /usr/share/bcc/tools/execsnoop
In file included from <built-in>:2:
/virtual/include/bcc/bpf.h:13:10: fatal error: 'linux/bpf_common.h' file not found
#include <linux/bpf_common.h>
^~~~~~~~~~~~~~~~~~~~
1 error generated.
Traceback (most recent call last):
File "/usr/share/bcc/tools/execsnoop", line 166, in <module>
b = BPF(text=bpf_text)
File "/usr/lib/python2.7/site-packages/bcc/__init__.py", line 318, in __init__
raise Exception("Failed to compile BPF text")
Exception: Failed to compile BPF text
BPF Features by Linux Kernel Version汇总了每个特性需要的最低内核版本,下图提供了部分信息:

BCC Python Developer Tutorial中介绍了eBPF应用程序的开发方法,掌握以后可以自行开发追踪工具。
支持旧内核的SystemTap
和eBPF根植于内核不同,SystemTap是独立于内核的,并且在RHEL系统中好用,在其它发行版上容易出现各种异常问题。eBPF是比较新的内核特性,对内核版本要求高,SystemTap的先于eBPF诞生,支持3.x等旧版本的内核。
容器动态追踪sysdig
Sysdig vs DTrace vs Strace: a Technical Discussion
参考
CPU 相关知识
这里记录CPU相关的知识。
参考
CPU的运行状态
CPU一共有多种工作状态,其中只有idle状态是空闲状态。
top命令显示过去2秒(2s是默认值,可以用-d参数修改)中,每个CPU在每个状态中停留的时间比例:
%Cpu(s): 14.5 us, 0.3 sy, 0.0 ni, 85.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
us是CPU在用户态的时间比例,sy是CPU在内核态的时间比例,其它指标含义如下:
us, user : time running un-niced user processes
sy, system : time running kernel processes
ni, nice : time running niced user processes
id, idle : time spent in the kernel idle handler
wa, IO-wait : time waiting for I/O completion
hi : time spent servicing hardware interrupts
si : time spent servicing software interrupts
st : time stolen from this vm by the hypervisor
在man top和中可以找到这些说明。另外man proc给出了更多状态说明:
user (1) Time spent in user mode.
nice (2) Time spent in user mode with low priority (nice).
system (3) Time spent in system mode.
idle (4) Time spent in the idle task.
This value should be USER_HZ times the second entry in the /proc/uptime pseudo-file.
iowait (since Linux 2.5.41)
(5) Time waiting for I/O to complete.
irq (since Linux 2.6.0-test4)
(6) Time servicing interrupts.
softirq (since Linux 2.6.0-test4)
(7) Time servicing softirqs.
steal (since Linux 2.6.11)
(8) Stolen time, which is the time spent in other operating systems when running in a virtualized environment
guest (since Linux 2.6.24)
(9) Time spent running a virtual CPU for guest operating systems under the control of the Linux kernel.
guest_nice (since Linux 2.6.33)
(10) Time spent running a niced guest (virtual CPU for guest operating systems under the control of the Linux kernel).
Understanding CPU Steal Time - when should you be worried?中详细介绍了steal time,如果steal time占比持续20分钟超过10%,vm性能可能受到了显著影响。
CPU使用率的计算
CPU使用率计算方法是:1-空闲时间/CPU总时间。
CPU处于每种状态的时间
top中会显示CPU在每个状态的时间占比,这些数据来自于/proc/stat,这个文件中记录每个CPU在每种模式下耗费的时间分片数量,第一行是所有CPU的数值的累加:
$ cat /proc/stat
cpu 2295737 1270 903726 238996130 61210 0 90996 27778 0 0
cpu0 435456 334 213700 59922519 15305 0 18523 6715 0 0
cpu1 626136 317 229817 59638019 15702 0 35754 7526 0 0
cpu2 635052 320 237094 59685588 15354 0 18630 6930 0 0
cpu3 599092 297 223113 59750002 14847 0 18087 6605 0 0
...
注意:/proc/stat中数值的单位不是秒/毫秒,而是时间分片的个数:
The amount of time, measured in units of USER_HZ (1/100ths of a second on most architectures,
use sysconf(_SC_CLK_TCK) to obtain the right value), that the system spent in vari‐
每个时间分片时长是1/100秒。
用户态与内核态的详细说明
用户态和内核态其实是CPU的工作模式,一些特殊的指令可以让CPU在用户态和内核态的切换。 CPU在内核态时,操作的是内核中的数据,用户态时操作的是用户态数据。
用户态进程是通过发起系统调用,进入到内核态的。
系统调用可以理解为内核提供的功能接口,用户态程序发起系统调用的时候,CPU转为内核态,完成了相关操作后,再切换回用户态。
参考
CPU运行上下文的切换
CPU上下文就是CPU中所有寄存器、计数器的快照,是CPU工作环境。当CPU要执行另一个进程的时候,需要将一些寄存器的数值修改为目标进程的相应值,这个过程叫做CPU上下文切换。
CPU上下文切换发生在这几个场景中:
- 特权模式切换(系统调用)
- 进程上下文切换
- 线程上下文切换
- 中断上下文切换
特权模式切换(系统调用)
在Linux中,CPU特权模式切换就是用户态和内核态的切换,用户态进程通过调用系统调用进入到内核态,这个过程中一些特殊的CPU指令会被执行,将CPU切换特权模式,CPU的上下文也随之切换,切入切回,一次系统调用伴随着两次上下文切换。
第一次切换:调用系统调用时候,保存用户态的状态,然后切换到内核态,加载内核态代码。
第二次切换:内核态的系统调用处理代码执行结束后,退出特权模式,加载之前保留的用户态状态。
系统调用的切换过程中一直都是一个进程,和进程与进程的切换不同,不涉及虚拟内存等用户态资源。
进程上下文切换
进程是内核管理调度的,切换过程在内核态进行。相比系统调用中的切换,进程切换时需要保留更多状态数据,例如虚拟内存、栈、全局变量,和内核堆栈、寄存器数值。
进程上下文切换时,先保留当前进程的状态,然后加载下一个进程的状态,每次切换需要几十纳秒到几微妙的时间,开销比较大。(硬件寄存器的缓存需要被重新刷新,也使执行效率受到影响,在多核的机器,进程还可能在不同CPU核心上移动)
进程上下文切换是不可避免的,通常情况下,进程的数量一定是远远超过CPU核心数的,进程不能独占CPU,需要接受内核的调度,每次调度都会触发进程切换。
引发内核重新调度的因素有:
- 正在运行的进程的当前时间片耗尽
- 系统资源不足(譬如内存),进程需要等待
- 进程通过sleep等函数,将自己挂起
- 出现了优先级更高的进程(内核需要设置为支持抢占)
- 发生硬件中断,被切换到中断服务程序(注意,软中断不会触发切换)
如果一个进程因为被频繁地切换上下文,导致效率不高,可以将进程绑定指定CPU核心上。
线程上下文切换
进程是资源拥有的基本单位,线程是调度的基本单位。一个进程对应至少一个线程,可以对应多个线程。
隶属于同一个继承的线程间进行上下文切换的开销相对较小,因为它们有一部分共用的数据,这些数据可以免除切换。
中断上下文切换
中断通常是硬件发出的,也可以用实现“软中断”,中断发生后,CPU通常需要停下当前的工作,优先处理中断实现,指定中断事件对应的指令。
中断只发生在内核态。
中断会打断其它进程的调度和执行,带来额外的开销,如果中断次数过多,会显著降低整体系统。
参考
Linux中查看CPU的使用情况
CPU使用分析主要就是分析CPU的使用率,看看那些进程占用的CPU资源比较多。
top/htop/atop查看CPU使用情况
top命令不多说了,需要注意的是在top中键入H后,进入线程模式。
htop和atop是两个功能更丰富的类top工具:
yum install -y htop atop
pidstat查看进程的CPU使用率
pidstat命令可以显示每个进程的在不同CPU状态中耗费的时间的百分比(1,每秒显示一次;-p,指定进程,如果不指定,显示所有进程):
$ pidstat 1 -p 27936
Linux 3.10.0-693.11.6.el7.x86_64 (10.10.64.58) 12/04/2018 _x86_64_ (4 CPU)
05:00:59 PM UID PID %usr %system %guest %CPU CPU Command
05:01:00 PM 99 27936 0.00 0.00 0.00 0.00 0 openresty
05:01:01 PM 99 27936 0.00 0.00 0.00 0.00 0 openresty
05:01:02 PM 99 27936 0.00 0.00 0.00 0.00 0 openresty
perf top查看CPU占用高的函数
perf top显示占用CPU时间最多的函数或者指令:
$ perf top
Samples: 3K of event 'cpu-clock', Event count (approx.): 903937500
Overhead Shared Object Symbol
8.69% perf [.] symbols__insert
5.33% perf [.] rb_next
3.41% [kernel] [k] _raw_spin_unlock_irqrestore
3.12% libc-2.17.so [.] __memcpy_ssse3_back
2.40% [kernel] [k] finish_task_switch
2.40% libc-2.17.so [.] __strchr_sse42
2.08% libelf-0.168.so [.] gelf_getsym
...省略后续内容...
perf report查看cpu事件占比
用perf record将采样数据保存,然后用perf record查看,或者直接用下面的命令一次完成,-a查看所有cpu:
perf record -ag -- sleep 15;perf report
perf report中显示,stress进程的cpu事件占比是77%,它大量调用了随机数生成函数random():

vmstat查看上下文切换
vmstat命令显示系统整体状态,输出如下:
$ vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 5980 126076 648 6997448 0 0 6 27 13 1 1 1 97 0 0
可以在后面加上一个数字,每隔指定时间输出一次,例如vmstat 5,如果感觉数据排列太密集,可以加上参数-w,用宽格式显示。
vmstat命令的输出包含procs、memory、 swap、io、system和cpu六块内容。
每列数据的含义如下,可以在man vmstat中找到:
Procs
r: The number of runnable processes (running or waiting for run time).
b: The number of processes in uninterruptible sleep.
Memory
swpd: the amount of virtual memory used.
free: the amount of idle memory.
buff: the amount of memory used as buffers.
cache: the amount of memory used as cache.
inact: the amount of inactive memory. (-a option)
active: the amount of active memory. (-a option)
Swap
si: Amount of memory swapped in from disk (/s).
so: Amount of memory swapped to disk (/s).
IO
bi: Blocks received from a block device (blocks/s).
bo: Blocks sent to a block device (blocks/s).
System
in: The number of interrupts per second, including the clock.
cs: The number of context switches per second.
CPU
These are percentages of total CPU time.
us: Time spent running non-kernel code. (user time, including nice time)
sy: Time spent running kernel code. (system time)
id: Time spent idle. Prior to Linux 2.5.41, this includes IO-wait time.
wa: Time spent waiting for IO. Prior to Linux 2.5.41, included in idle.
st: Time stolen from a virtual machine. Prior to Linux 2.6.11, unknown.
其中cs是一秒内发生的上下文切换次数。
pidstat查看特定进程的切换情况
pidstat -w可以显示每个进程的上下文切换情况:
$ pidstat -w
Linux 3.10.0-693.11.6.el7.x86_64 (10.10.64.58) 12/04/2018 _x86_64_ (4 CPU)
04:04:15 PM UID PID cswch/s nvcswch/s Command
04:04:15 PM 0 1 1.75 0.00 systemd
04:04:15 PM 0 2 0.01 0.00 kthreadd
04:04:15 PM 0 3 2.54 0.00 ksoftirqd/0
...省略后续内容...
(可以在后面上一个数字,每隔指定时间输出一次,例如pidstat -w 5)
特别注意:pidstats -w显示的是进程的状态,如果要将线程一并显示出来,需要再加一个-t参数:
$ pidstat -wt
Average: UID TGID TID cswch/s nvcswch/s Command
Average: 0 3 - 3.92 0.00 ksoftirqd/0
Average: 0 - 3 3.92 0.00 |__ksoftirqd/0
Average: 0 9 - 45.59 0.00 rcu_sched
Average: 0 - 9 45.59 0.00 |__rcu_sched
Average: 0 13 - 1.96 0.00 ksoftirqd/1
Average: 0 - 13 1.96 0.00 |__ksoftirqd/1
Average: 0 17 - 0.49 0.00 migration/2
...省略后续内容...
-w参数的作用是显示进程切换状态,每一列的含义如下(可以在man pidstat中找到):
-w Report task switching activity (kernels 2.6.23 and later only).
The following values may be displayed:
UID
The real user identification number of the task being monitored.
USER
The name of the real user owning the task being monitored.
PID
The identification number of the task being monitored.
cswch/s
Total number of voluntary context switches the task made per second.
A voluntary context switch occurs when a task blocks because it requires
a resource that is unavailable.
nvcswch/s
Total number of non voluntary context switches the task made per second.
A involuntary context switch takes place when a task executes for the duration
of its time slice and then is forced to relinquish the processor.
Command
The command name of the task.
需要注意自愿切换(cswch/s,voluntary context switches)和非自愿切换(nvcswch/s,non voluntary context switches)的区别。前者是因为需要的资源没有准备好,主动让出CPU发生的切换,后者是进程分配的时间片已经用完,被调度器强制切换。
另外pidstat还有一个-u参数,可以一并输出进程和线程(加-t)的CPU使用情况:
[[email protected] ~]# pidstat -wt -u
Linux 3.10.0-693.11.6.el7.x86_64 (10.10.64.58) 12/04/2018 _x86_64_ (4 CPU)
04:21:56 PM UID TGID TID %usr %system %guest %CPU CPU Command
04:21:56 PM 0 1 - 0.02 0.01 0.00 0.03 0 systemd
04:21:56 PM 0 - 1 0.02 0.01 0.00 0.03 0 |__systemd
04:21:56 PM 0 2 - 0.00 0.00 0.00 0.00 0 kthreadd
04:21:56 PM 0 - 2 0.00 0.00 0.00 0.00 0 |__kthreadd
...省略后续内容...
04:21:56 PM UID TGID TID cswch/s nvcswch/s Command
04:21:56 PM 0 1 - 1.75 0.00 systemd
04:21:56 PM 0 - 1 1.75 0.00 |__systemd
04:21:56 PM 0 2 - 0.01 0.00 kthreadd
04:21:56 PM 0 - 2 0.01 0.00 |__kthreadd
04:21:56 PM 0 3 - 2.53 0.00 ksoftirqd/0
...省略后续内容...
/proc/interrupts记录的中断状态
watch -d cat /proc/interrupts用可以显示中断的变化情况。
Every 2.0s: cat /proc/interrupts Tue Dec 4 16:29:25 2018
CPU0 CPU1 CPU2 CPU3
0: 153 0 0 0 IO-APIC-edge timer
1: 10 0 0 0 IO-APIC-edge i8042
6: 3 0 0 0 IO-APIC-edge floppy
8: 0 0 0 0 IO-APIC-edge rtc0
9: 0 0 0 0 IO-APIC-fasteoi acpi
10: 0 0 0 0 IO-APIC-fasteoi virtio0
11: 31 0 3 0 IO-APIC-fasteoi uhci_hcd:usb1
12: 15 0 0 0 IO-APIC-edge i8042
14: 0 0 0 0 IO-APIC-edge ata_piix
15: 0 0 0 0 IO-APIC-edge ata_piix
24: 0 0 0 0 PCI-MSI-edge virtio3-config
25: 6234 0 120283 272843 PCI-MSI-edge virtio3-req.0
26: 0 0 0 0 PCI-MSI-edge virtio1-config
27: 99 176029503 172147021 0 PCI-MSI-edge virtio1-input.0
28: 24 2721 497 4165 PCI-MSI-edge virtio1-output.0
29: 0 0 0 0 PCI-MSI-edge virtio2-config
30: 19 0 0 0 PCI-MSI-edge virtio2-virtqueues
31: 0 0 0 0 PCI-MSI-edge virtio4-config
32: 131111 0 0 0 PCI-MSI-edge virtio4-req.0
NMI: 0 0 0 0 Non-maskable interrupts
LOC: 64284244 70653905 70450086 65741168 Local timer interrupts
SPU: 0 0 0 0 Spurious interrupts
PMI: 0 0 0 0 Performance monitoring interrupts
IWI: 1242971 1424513 1360783 1296367 IRQ work interrupts
RTR: 0 0 0 0 APIC ICR read retries
RES: 33708963 29562936 30300354 32946303 Rescheduling interrupts
CAL: 131150935 64213698 67023823 133615842 Function call interrupts
TLB: 519133 541110 531432 522850 TLB shootdowns
TRM: 0 0 0 0 Thermal event interrupts
THR: 0 0 0 0 Threshold APIC interrupts
DFR: 0 0 0 0 Deferred Error APIC interrupts
MCE: 0 0 0 0 Machine check exceptions
MCP: 2001 2001 2001 2001 Machine check polls
ERR: 0
MIS: 0
PIN: 0 0 0 0 Posted-interrupt notification event
PIW: 0 0 0 0 Posted-interrupt wakeup event
Rescheduling interrupts是重调度中断,用来唤醒空闲的CPU执行新的任务。
参考
内存相关的知识
参考
Linux的内存管理方法
虚拟内存地址空间划分


虚拟内存与物理内存的映射


NUMA:node独立内存
在NUMA架构(多CPU)下,每个node(物理CPU)都有自己的本地内存,在分析内存的时候需要分析每个node的情况:

$ numactl --hardware
available: 1 nodes (0)
node 0 cpus: 0 1
node 0 size: 7977 MB
node 0 free: 4416 MB
...
/proc/sys/vm/zone_reclaim_mode设置NUMA本地内存的回收策略,当node本地内存不足时,默认可以从其它node寻找空闲内存,也可以从本地回收。
Swap
Swap的设置开启:
# 创建 Swap 文件
$ fallocate -l 8G /mnt/swapfile
# 修改权限只有根用户可以访问
$ chmod 600 /mnt/swapfile
# 配置 Swap 文件
$ mkswap /mnt/swapfile
# 开启 Swap
$ swapon /mnt/swapfile
sar显示Swap的使用情看,-r 表示显示内存使用情况,-S 表示显示 Swap 使用情况:
$ sar -r -S 1
04:39:56 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
04:39:57 6249676 6839824 1919632 23.50 740512 67316 1691736 10.22 815156 841868 4
04:39:56 kbswpfree kbswpused %swpused kbswpcad %swpcad
04:39:57 8388604 0 0.00 0 0.00
04:39:57 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
04:39:58 6184472 6807064 1984836 24.30 772768 67380 1691736 10.22 847932 874224 20
04:39:57 kbswpfree kbswpused %swpused kbswpcad %swpcad
04:39:58 8388604 0 0.00 0 0.00
内存分配:brk()与mmap()
brk()分配的是堆中的内存,这些内存释放以后不会被立刻归还系统,而是被缓存起来重复使用。brk()会缓存获得的物理内存页,减少缺页异常,但是频繁的内存分配和释放会造成内存碎片。
mmap()分配的文件映射段的内存,释放时直接归还系统,下载再使用要再次触发缺页异常,让内核分配对应的物理内存。 mmap()直接归还获得的物理内存页,每次都会触发缺页异常,频繁内存分配会增加内核压力。
在C标准库中,小于128K的内存用brk()分配,大于128K的内存用mmap()分配。
内核内存:伙伴系统
内核用伙伴系统管理内存分配。
内存泄露
BCC中的memleak用来检测内存泄露:
$ /usr/share/bcc/tools/memleak -p $(pidof app) -a
Attaching to pid 12512, Ctrl+C to quit.
[03:00:41] Top 10 stacks with outstanding allocations:
addr = 7f8f70863220 size = 8192
addr = 7f8f70861210 size = 8192
addr = 7f8f7085b1e0 size = 8192
addr = 7f8f7085f200 size = 8192
addr = 7f8f7085d1f0 size = 8192
40960 bytes in 5 allocations from stack
fibonacci+0x1f [app]
child+0x4f [app]
start_thread+0xdb [libpthread-2.27.so]
参考
内存缓存
buffer与cache
free的命令中有一栏是buff/cache,buffer和cache都是内存缓存,但是又有区别。
$ free
total used free shared buff/cache available
Mem: 32731868 1170284 28024100 254420 3537484 30824636
Swap: 67108860 3376124 63732736
buffer中缓存的是将要写到磁盘的数据,通过合并写的方式提高写入效率。
cache中缓存的是从磁盘读取的数据。
缓存命中率
BCC中的cachestat和cachetop分别用来查看整个系统的缓存读写命中情况、每个进程的缓存命中情况。
$ cachestat 1 3
TOTAL MISSES HITS DIRTIES BUFFERS_MB CACHED_MB
2 0 2 1 17 279
2 0 2 1 17 279
2 0 2 1 17 279
TOTAL是总的IO次数,DIRTIES是新增到缓存中的脏页。
$ cachetop
11:58:50 Buffers MB: 258 / Cached MB: 347 / Sort: HITS / Order: ascending
PID UID CMD HITS MISSES DIRTIES READ_HIT% WRITE_HIT%
13029 root python 1 0 0 100.0% 0.0%
文件的缓存大小
pcstat用来查看一个文件的缓存大小:
$ pcstat /bin/ls
+---------+----------------+------------+-----------+---------+
| Name | Size (bytes) | Pages | Cached | Percent |
|---------+----------------+------------+-----------+---------|
| /bin/ls | 133792 | 33 | 0 | 000.000 |
+---------+----------------+------------+-----------+---------+
pcstat的安装方法:
$ go get golang.org/x/sys/unix
$ go get github.com/tobert/pcstat/pcstat
在测试文件读写性能的时候,要清理缓存:
$ echo 3 > /proc/sys/vm/drop_caches
参考
查看内存状态
vmstat查看内存状态
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 1 0 6809304 1368 856744 0 0 32640 0 52 478 1 0 50 49 0
0 1 0 6776620 1368 889456 0 0 32640 0 33 490 0 0 50 49 0
0 0 0 6747540 1368 918576 0 0 29056 0 42 568 0 0 56 44 0
0 0 0 6747540 1368 918576 0 0 0 0 40 141 1 0 100 0 0
0 0 0 6747160 1368 918576 0 0 0 0 40 148 0 1 99 0 0
buff: 写入缓冲区。
cache: 读取缓冲区。
bi: 每秒从块设备上读取的块数(block/s)。
bo: 每秒向块设备上写入的块数(block/s)。
in: 每秒中断次数,包含时钟中断。
cs: 每秒的上下文切换次数。
参考
系统中断
中断是重要的内核机制,是内核的事件处理机制。
参考
Linux的系统中断
中断分为硬中断和软中断,发生中断以后,中断处理程序会被调用。
中断处理程序运行期间,不能再次中断(设置了中断禁止)的中断是硬中断,硬中断处理期间发生的中断会丢失,所以硬中断的处理时间不能过程。中断处理程序运行期间,可以再次中断的中断是软中断。
Linux将中断处理过程分为两个阶段:
-
第一阶段是上半部,在中断禁止模式下运行,用来快速处理硬件相关或者时间敏感的任务,触发上半部处理的中断是硬中断;
-
第二阶段是下半部,允许继续中断,用于处理上半部未完成的工作,通常以内核线程的方式运行,触发下半部操作的中断是软中断。
上半部处理结束时,通常会发送一个软中断,由下半部处理时效性不那么紧迫的任务。上半部通常是硬件触发,处理硬件请求,下半部是内核触发。
下半部是软中断,软中断不全是下半部,一些内核自定义事件也是软中断,例如内核调度、RCU锁等。
每个CPU都有一个软中断内核线程,ksoftirqd/cpu编号:
$ps aux|grep ksoft
root 3 0.0 0.0 0 0 ? S Apr05 1:19 [ksoftirqd/0]
root 13 0.0 0.0 0 0 ? S Apr05 1:24 [ksoftirqd/1]
root 18 0.0 0.0 0 0 ? S Apr05 1:25 [ksoftirqd/2]
root 23 0.0 0.0 0 0 ? S Apr05 1:14 [ksoftirqd/3]
root 28 0.0 0.0 0 0 ? S Apr05 1:26 [ksoftirqd/4]
root 33 0.0 0.0 0 0 ? S Apr05 1:09 [ksoftirqd/5]
root 38 0.0 0.0 0 0 ? S Apr05 1:09 [ksoftirqd/6]
系统中断状态
/proc/softirqs中是软中断的运行情况,同一中断在不同CPU上的运行次数应当是接近的,如果明显不均衡,表明多核CPU没有被充分利用:
$ cat /proc/softirqs
CPU0 CPU1 CPU2 CPU3
HI: 1 1 0 0
TIMER: 607522918 541095809 566655073 545147469
NET_TX: 1188125 727904 1105106 1090468
NET_RX: 227103214 1942391353 244785330 214470397
BLOCK: 9212292 9070209 6004124 9196281
IRQ_POLL: 0 0 0 0
TASKLET: 461 703 559 512
SCHED: 262424378 225458960 231808842 212340029
HRTIMER: 1598 1163 1373 1445
RCU: 348165561 309546532 322077899 312389145
/proc/interrupts中是硬中断的运行情况:
$ cat /proc/interrupts
CPU0 CPU1 CPU2 CPU3
0: 114 0 0 0 IO-APIC 2-edge timer
1: 9 0 0 0 IO-APIC 1-edge i8042
6: 0 0 3 0 IO-APIC 6-edge floppy
8: 0 0 0 0 IO-APIC 8-edge rtc0
9: 0 0 0 0 IO-APIC 9-fasteoi acpi
10: 0 0 0 0 IO-APIC 10-fasteoi virtio0
11: 0 0 35 0 IO-APIC 11-fasteoi uhci_hcd:usb1
12: 0 0 0 15 IO-APIC 12-edge i8042
14: 0 0 0 0 IO-APIC 14-edge ata_piix
15: 0 0 0 0 IO-APIC 15-edge ata_piix
24: 0 0 0 0 PCI-MSI 81920-edge virtio2-config
25: 0 0 3 0 PCI-MSI 81921-edge virtio2-virtqueues
26: 0 0 0 0 PCI-MSI 65536-edge virtio1-config
27: 62 1012111617 0 0 PCI-MSI 65537-edge virtio1-input.0
28: 54 2 0 22109 PCI-MSI 65538-edge virtio1-output.0
29: 0 0 0 0 PCI-MSI 98304-edge virtio3-config
30: 0 0 9853249 0 PCI-MSI 98305-edge virtio3-req.0
31: 0 0 0 0 PCI-MSI 114688-edge virtio4-config
32: 0 0 12293598 0 PCI-MSI 114689-edge virtio4-req.0
NMI: 0 0 0 0 Non-maskable interrupts
LOC: 1217427530 1144644230 1177257177 1149689000 Local timer interrupts
SPU: 0 0 0 0 Spurious interrupts
PMI: 0 0 0 0 Performance monitoring interrupts
IWI: 153 120 264 318 IRQ work interrupts
RTR: 0 0 0 0 APIC ICR read retries
RES: 1027217904 904556924 981991984 977800420 Rescheduling interrupts
CAL: 233863698 11399907 241091628 220970613 Function call interrupts
TLB: 1487790 1520042 1474210 1505102 TLB shootdowns
TRM: 0 0 0 0 Thermal event interrupts
THR: 0 0 0 0 Threshold APIC interrupts
DFR: 0 0 0 0 Deferred Error APIC interrupts
MCE: 0 0 0 0 Machine check exceptions
MCP: 14170 14170 14170 14170 Machine check polls
HYP: 0 0 0 0 Hypervisor callback interrupts
HRE: 0 0 0 0 Hyper-V reenlightenment interrupts
HVS: 0 0 0 0 Hyper-V stimer0 interrupts
ERR: 0
MIS: 0
PIN: 0 0 0 0 Posted-interrupt notification event
NPI: 0 0 0 0 Nested posted-interrupt event
PIW: 0 0 0 0 Posted-interrupt wakeup event
参考
理解进程
几个查看进程状态的工具:
top command : Display and update sorted information about Linux processes.
atop command : Advanced System & Process Monitor for Linux.
htop command : Interactive process viewer in Linux.
pgrep command : Look up or signal processes based on name and other attributes.
pstree command : Display a tree of processes.
Show All Running Processes in Linux using ps/htop commands
参考
进程的分类
Understanding Linux Process States对Linux的进程(Process)做了很详细的介绍。
在Linux中,进程是申请资源的最小单位,每个进程有ownership、nice value、SELinux context等诸多属性。Linux中,进程分为三类:用户进程(User Process)、守护进程(Daemon Process)、内核进程(Kernel Process)。
用户进程(User Process)是普通用户创建的、运行在用户态(User Space)的进程。除非进行了特殊的权限设置,否则用户进程没有其它用户文件的权限。
守护进程(Daemon Process)是在后台一直运行的进程,应当算是用户进程中的一种,但它不随着用户的退出而终止,而是一直在系统中运行,直到被人为关闭。
内核进程(Kernel Process)只在内核态运行,它也是常驻的进程,但内核进程拥有最高权限,可以访问所有的内核数据。
这是通常提到的三种划分方法,个人感觉这种划分方法在标准上不统一,严格说,按照进程的所属和权限,进程可以分为用户进程和内核进程,按照进程的形态,可以分为守护进程和非守护进程。用户进程既可以是守护进程也可以是非守护进程,内核进程都是守护进程。
参考
进程的状态
ps -l命令输出结果的第二列是进程所处的状态,ps一共展示以下几种状态:
D uninterruptible sleep (usually IO)
R running or runnable (on run queue)
S interruptible sleep (waiting for an event to complete)
T stopped by job control signal
t stopped by debugger during the tracing
W paging (not valid since the 2.6.xx kernel)
X dead (should never be seen)
Z defunct ("zombie") process, terminated but not reaped by its parent
在man ps中可以找到更详细说明。
进程状态介绍
进程是动态的,是有状态的,正在被CPU执行的进程的状态是Running,没有被CPU执行的进程的状态是Not Running。在后面的火焰图章节中,正在运行的状态被称为On-CPU,没有在运行的状态被称为Off-CPU,一个进程要么在使用CPU,要么没有在使用CPU,在做性能分析的时候,这两段时间里发生的事情都需要关注。
每个CPU核心同一时间只能执行一个进程,对一个CPU核心来说进程就是一组指令,CPU不停地吃进指令、执行执行,不能同时吃进两个指令(在CPU中使用流水线,可以一次给CPU塞进多个指令,但这些指令还是被一条一条执行的,不过CPU异常复杂,不能一言概之,我们现在可以这样理解)。
将进程状态分为Running和Not Running是远远不够的,进程的状态取决于调度算法,调度算法的目的是在兼顾效率和公平的情况下,让有限的CPU处理远超过CPU数量、各种各样的进程。调度算法越复杂,进程的状态就越多。
现在,进程的状态主要有以下几种:
0. 刚创建,Born or forked
1. 可运行状态,Ready or Runnable
2. 运行状态,Running in User Or Running in Kernel
3. 阻塞状态,Blocked
4. 等待状态,Waiting
5. 睡眠状态,Sleeping
6. 睡眠状态又可以分为可中断( Interruptable)和不可中断( Uninterruptable )两种状态
7. 睡觉状态分为驻留在内存中和被交换到交换分区中两种状态
8. 僵尸状态、终止状态,Terminated or stopped
进程状态是Runnable,表示该进程万事具备,只缺CPU,可以随时被CPU执行。
进程状态是Sleeping,表示改进程需要的一些资源需要时间准备,调度器将原本被它占用的CPU调度给Runable状态的进程,直到进程需要的资源准备完成,重新进入Runnable状态。
用ps -l可以看到睡眠的进程停留在哪个内核函数上(WCHAN字段)(在加上参数-e可以显示所有进程):
$ ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 7042 7040 0 80 0 - 28894 wait pts/0 00:00:00 bash
0 R 0 7950 7042 0 80 0 - 34361 - pts/0 00:00:00 ps
WCHAN: name of the kernel function in which the process is sleeping, a "-" if the process is running, or a "*" if the process is multi-threaded and ps is not displaying threads.
睡眠状态的进程分为可中断的和不可中断的,两者的区别在于对信号或者事件的态度,前者在收到信号或者事件后,进程会跳出睡眠状态,后者不会,后者要等到系统调用完成后,才会感知到睡眠期间的发生事件。 不可中断的进程通常是在进行磁盘、网络I/O操作的进程,它们需要等到设备操作完成。
进程运行结束退出后,在进程表中占用的位置由它的父进程负责释放,在父进程还没有释放它占用的位置的时候,进程处于僵尸状态。
查找父进程
用pstree可以直接展示出一个进程的父进程,以及父进程的父进程,直到1号继承,-a 表示输出命令行选项、 p 表 PID、s 表示指定进程的父进程
$ pstree -aps 3084
systemd,1
└─dockerd,15006 -H fd://
└─docker-containe,15024 --config /var/run/docker/containerd/containerd.toml
└─docker-containe,3991 -namespace moby -workdir...
└─app,4009
└─(app,3084)
pstree命令位于rpm包psmisc中:
yum install -y psmisc
参考
Linux查看指定进程占用的资源
查看指定进程占用的资源。
pidstat查看进程的CPU使用率
pidstat命令可以显示每个进程的在不同CPU状态中耗费的时间的百分比(1,每秒显示一次;-p,指定进程,如果不指定,显示所有进程):
$ pidstat 1 -p 27936
Linux 3.10.0-693.11.6.el7.x86_64 (10.10.64.58) 12/04/2018 _x86_64_ (4 CPU)
05:00:59 PM UID PID %usr %system %guest %CPU CPU Command
05:01:00 PM 99 27936 0.00 0.00 0.00 0.00 0 openresty
05:01:01 PM 99 27936 0.00 0.00 0.00 0.00 0 openresty
05:01:02 PM 99 27936 0.00 0.00 0.00 0.00 0 openresty
pidstat查看进程的IO情况
pidstat,-d表示展示IO信息,1表示每秒输出一次,使用-p指定进程号,下面间隔 1 秒输出 3 组数据:
$ pidstat -d -p 4344 1 3
06:38:50 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
06:38:51 0 4344 0.00 0.00 0.00 0 app
06:38:52 0 4344 0.00 0.00 0.00 0 app
06:38:53 0 4344 0.00 0.00 0.00 0 app
pidstat查看进程的切换情况
pidstat -w -p 进程号可以显示指定进程的上下文切换情况:
$ pidstat -w 2 -p 426
Linux 4.20.12-1.el7.elrepo.x86_64 (10.10.64.58) 04/29/2019 _x86_64_ (4 CPU)
03:01:12 PM UID PID cswch/s nvcswch/s Command
03:01:14 PM 99 426 2.99 0.00 openresty
03:01:16 PM 99 426 2.50 0.00 openresty
03:01:18 PM 99 426 3.00 0.00 openresty
03:01:20 PM 99 426 2.00 0.00 openresty
-w参数的作用是显示进程切换状态,每一列的含义如下(可以在man pidstat中找到):
-w Report task switching activity (kernels 2.6.23 and later only).
The following values may be displayed:
UID
The real user identification number of the task being monitored.
USER
The name of the real user owning the task being monitored.
PID
The identification number of the task being monitored.
cswch/s
Total number of voluntary context switches the task made per second.
A voluntary context switch occurs when a task blocks because it requires
a resource that is unavailable.
nvcswch/s
Total number of non voluntary context switches the task made per second.
A involuntary context switch takes place when a task executes for the duration
of its time slice and then is forced to relinquish the processor.
Command
The command name of the task.
需要注意自愿切换(cswch/s,voluntary context switches)和非自愿切换(nvcswch/s,non voluntary context switches)的区别。前者是因为需要的资源没有准备好,主动让出CPU发生的切换,后者是进程分配的时间片已经用完,被调度器强制切换。
pidstats -w显示的是进程的状态,如果要将线程一并显示出来,需要再加一个-t参数:
$ pidstat -wt
Average: UID TGID TID cswch/s nvcswch/s Command
Average: 0 3 - 3.92 0.00 ksoftirqd/0
Average: 0 - 3 3.92 0.00 |__ksoftirqd/0
Average: 0 9 - 45.59 0.00 rcu_sched
Average: 0 - 9 45.59 0.00 |__rcu_sched
Average: 0 13 - 1.96 0.00 ksoftirqd/1
Average: 0 - 13 1.96 0.00 |__ksoftirqd/1
Average: 0 17 - 0.49 0.00 migration/2
另外pidstat还有一个-u参数,可以一并输出进程和线程(加-t)的CPU使用情况:
[[email protected] ~]# pidstat -wt -u
Linux 3.10.0-693.11.6.el7.x86_64 (10.10.64.58) 12/04/2018 _x86_64_ (4 CPU)
04:21:56 PM UID TGID TID %usr %system %guest %CPU CPU Command
04:21:56 PM 0 1 - 0.02 0.01 0.00 0.03 0 systemd
04:21:56 PM 0 - 1 0.02 0.01 0.00 0.03 0 |__systemd
04:21:56 PM 0 2 - 0.00 0.00 0.00 0.00 0 kthreadd
04:21:56 PM 0 - 2 0.00 0.00 0.00 0.00 0 |__kthreadd
04:21:56 PM UID TGID TID cswch/s nvcswch/s Command
04:21:56 PM 0 1 - 1.75 0.00 systemd
04:21:56 PM 0 - 1 1.75 0.00 |__systemd
04:21:56 PM 0 2 - 0.01 0.00 kthreadd
04:21:56 PM 0 - 2 0.01 0.00 |__kthreadd
04:21:56 PM 0 3 - 2.53 0.00 ksoftirqd/0
lsof查看进程打开的文件
lsof查看进程打开的文件,-p指定进程号,注意必须是进程号,不能是线程号:
$ lsof -p 18940
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
python 18940 root cwd DIR 0,50 4096 1549389 /
python 18940 root rtd DIR 0,50 4096 1549389 /
…
python 18940 root 2u CHR 136,0 0t0 3 /dev/pts/0
python 18940 root 3w REG 8,1 117944320 303 /tmp/logtest.txt
strace查看进程发起的系统调用
strace跟踪进程的系统调用,-f 表示跟踪子进程和子线程,-T 表示显示系统调用的时长,-tt 表示显示跟踪时间:
$ strace -f -T -tt -p 9085
[pid 9085] 14:20:16.826131 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 65, NULL, 8) = 1 <0.000055>
[pid 9085] 14:20:16.826301 read(8, "*2\r\n$3\r\nGET\r\n$41\r\nuuid:5b2e76cc-"..., 16384) = 61 <0.000071>
[pid 9085] 14:20:16.826477 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000063>
[pid 9085] 14:20:16.826645 write(8, "$3\r\nbad\r\n", 9) = 9 <0.000173>
[pid 9085] 14:20:16.826907 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 65, NULL, 8) = 1 <0.000032>
[pid 9085] 14:20:16.827030 read(8, "*2\r\n$3\r\nGET\r\n$41\r\nuuid:55862ada-"..., 16384) = 61 <0.000044>
[pid 9085] 14:20:16.827149 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000043>
[pid 9085] 14:20:16.827285 write(8, "$3\r\nbad\r\n", 9) = 9 <0.000141>
[pid 9085] 14:20:16.827514 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 64, NULL, 8) = 1 <0.000049>
[pid 9085] 14:20:16.827641 read(8, "*2\r\n$3\r\nGET\r\n$41\r\nuuid:53522908-"..., 16384) = 61 <0.000043>
[pid 9085] 14:20:16.827784 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000034>
[pid 9085] 14:20:16.827945 write(8, "$4\r\ngood\r\n", 10) = 10 <0.000288>
[pid 9085] 14:20:16.828339 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 63, NULL, 8) = 1 <0.000057>
[pid 9085] 14:20:16.828486 read(8, "*3\r\n$4\r\nSADD\r\n$4\r\ngood\r\n$36\r\n535"..., 16384) = 67 <0.000040>
[pid 9085] 14:20:16.828623 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000052>
[pid 9085] 14:20:16.828760 write(7, "*3\r\n$4\r\nSADD\r\n$4\r\ngood\r\n$36\r\n535"..., 67) = 67 <0.000060>
[pid 9085] 14:20:16.828970 fdatasync(7) = 0 <0.005415>
[pid 9085] 14:20:16.834493 write(8, ":1\r\n", 4) = 4 <0.000250>
参考
Linux的文件系统
IO问题排查过程:

IO指标与工具映射表:


参考
Linux虚拟文件系统VFS
VFS是linux实现的虚拟文件系统,规定了数据结构和接口规范。

文件系统层
VFS内部通过超级块、索引节点、逻辑块和超级块等管理文件。
超级块:文件系统整体情况,索引节点和逻辑块的使用情况。
逻辑块:磁盘扇区构成的最小存储单元。
索引节点:文件的元数据,索引到具体的文件数据。
目录项:记录文件名,以及文件和目录、目录和目录之间的关系。
需要注意的是目录项只存在于内存中,超级块、逻辑块和索引节点是磁盘中的持久化数据,目录项的内容是从磁盘中读取加载的。
通用块层
在文件系统和磁盘驱动之间还有一个块设备抽象层,该层向上提供了统一的块设备标准接口,向下兼容各种类型的磁盘,同时负责对文件系统和应用程序发送过来的I/O请求排队,用重排、合并等方式,提高磁盘读写效率,也就是I/O调度。
Linux支持四种I/O调度策略:
NONE:不调度。
NOOP:先入先出,只做基本的请求合并,常用于SSD。
CFQ:默认策略,公平调度,每个进程维护一个I/O调度队列,按照时间片均匀分布每个进程的I/O请求。
DealLine:读、写两个I/O队列,距离截止时间最近的请求被优先处理,可以提高机械磁盘的吞吐量,通常用在压力较重的场景,例如数据库。
设备层
驱动程序和物理设备,负责物理设备上最终的I/O操作。
参考
磁盘相关知识
机械磁盘,通常缩写为HDD,机械磁盘有磁道寻址的时间,随机读写是性能会变差。
固态磁盘,通常缩写为SSD,不需要寻道,随机读写和连续读写效率均较高。
磁盘接口主要有:IDE、SCSI、SAS、SATA、FC等。
在具体使用的时候,可以将磁盘作为独立磁盘用,在每个磁盘上划分逻辑分区,或者将多个独立磁盘组合成一个逻辑磁盘,譬如RAID,RAID分为RAID0、RAID1、RAID5、RAID10,或者将磁盘组合成一个存储集群,通过NFS、SMB、iSCSI等网络存储协议接入服务器。
磁盘被Linux认作是块设备,拥有主设备号和次设备号,主设备号用于区分设备类型,面向驱动程序,次设备号是同类设备的唯一编号。
磁盘数据最小读取单位
机械磁盘的最小读取单位是扇区,每个扇区一般为512字节。
固态磁盘的最小读取单位是页,通常是4KB、8KB。
磁盘数据最小管理单位
逻辑块是磁盘上连续的扇区或者页,逻辑块是磁盘数据的最小管理单位。
磁盘性能指标
使用率:磁盘处理I/O的时间占比,使用率过高超过80%,说明磁盘I/O存在性能瓶颈。
饱和度:磁盘处理I/O的繁忙程度,饱和度为100%时,磁盘已经无法接收新的I/O请求。
IOPS:每秒钟的I/O操作次数。
吞吐量:每秒的数据吞吐量。
响应时间:I/O请求发出与收到响应的间隔时间。
磁盘使用率高不等于磁盘饱和,如果每次I/O操作的数据量很少,磁盘的使用率高,但是饱和度不高,可以继续接收新的I/O请求。(感觉饱和度有点类似于带宽占比,是和吞吐量相关的)
磁盘性能测试工具
fio,测试时需要考虑不同I/O大小、随机读、顺序读、随机写、顺序写等。
参考
查看Linux文件系统状态
可用空间
可用空间,用df查看,可用inode,用df -i查看。
# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 3.9G 0 3.9G 0% /dev
tmpfs 3.9G 4.0K 3.9G 1% /dev/shm
tmpfs 3.9G 452K 3.9G 1% /run
tmpfs 3.9G 0 3.9G 0% /sys/fs/cgroup
/dev/vda1 20G 14G 6.8G 67% /
/dev/vdb 100G 64G 37G 64% /data
tmpfs 798M 0 798M 0% /run/user/0
# df -ih
Filesystem Inodes IUsed IFree IUse% Mounted on
devtmpfs 995K 360 994K 1% /dev
tmpfs 998K 2 998K 1% /dev/shm
tmpfs 998K 447 997K 1% /run
tmpfs 998K 17 998K 1% /sys/fs/cgroup
/dev/vda1 20M 231K 20M 2% /
/dev/vdb 50M 1.8M 49M 4% /data
tmpfs 998K 1 998K 1% /run/user/0
页面缓存和slab缓存
页缓存和可回收的slab缓存:
$ cat /proc/meminfo | grep -E "SReclaimable|Cached"
Cached: 748316 kB #页缓存,缓存磁盘的上的文件,不包括swap
SwapCached: 0 kB #已经被从swap召回,但是还在swap文件中的内存页
SReclaimable: 179508 kB #可回收的slab
inode和文件目录项的缓存情况
inode和文件目录项的缓存情况:
$ cat /proc/slabinfo | grep -E '^#|dentry|inode'
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
xfs_inode 0 0 960 17 4 : tunables 0 0 0 : slabdata 0 0 0
...
ext4_inode_cache 32104 34590 1088 15 4 : tunables 0 0 0 : slabdata 2306 2306 0hugetlbfs_inode_cache 13 13 624 13 2 : tunables 0 0 0 : slabdata 1 1 0
sock_inode_cache 1190 1242 704 23 4 : tunables 0 0 0 : slabdata 54 54 0
shmem_inode_cache 1622 2139 712 23 4 : tunables 0 0 0 : slabdata 93 93 0
proc_inode_cache 3560 4080 680 12 2 : tunables 0 0 0 : slabdata 340 340 0
# vfs索引节点缓存
inode_cache 25172 25818 608 13 2 : tunables 0 0 0 : slabdata 1986 1986 0
# dentry是目录项
dentry 76050 121296 192 21 1 : tunables 0 0 0 : slabdata 5776 5776 0
具体含义见man slabinfo,slabtop可以更好的展现slab状态:
Active / Total Objects (% used) : 743718 / 794177 (93.6%)
Active / Total Slabs (% used) : 26434 / 26434 (100.0%)
Active / Total Caches (% used) : 103 / 138 (74.6%)
Active / Total Size (% used) : 179223.89K / 191460.80K (93.6%)
Minimum / Average / Maximum Object : 0.01K / 0.24K / 8.00K
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
211260 205043 97% 0.19K 10060 21 40240K dentry
49344 48896 99% 0.06K 771 64 3084K anon_vma_chain
42752 42752 100% 0.02K 167 256 668K kmalloc-16
38656 30327 78% 0.03K 302 128 1208K kmalloc-32
36352 29070 79% 0.01K 71 512 284K kmalloc-8
...
磁盘分区
用parted查看磁盘分区的文件系统:
$ parted /dev/vdb
GNU Parted 3.1
Using /dev/vdb
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted) print
Model: Virtio Block Device (virtblk)
Disk /dev/vdb: 107GB
Sector size (logical/physical): 512B/512B
Partition Table: loop
Disk Flags:
Number Start End Size File system Flags
1 0.00B 107GB 107GB xfs
(parted)
参考
Linux系统中的I/O
I/O操作分为:缓冲与非缓冲I/O、直接与非直接I/O、阻塞与非阻塞I/O、同步与异步I/O。
否使用标准库缓存:缓冲与非缓冲I/O
标准库对外提供I/O操作接口,自身则是通过系统调用访问文件。标准库的实现中会使用一些缓存机制,使用了标准库缓存的I/O操作是 缓冲I/O,直接通过系统调用进行的I/O操作是 非缓冲I/O。
是否使用系统的页缓存:直接与非直接I/O
操作系统也会有缓存,跳过操作系统页缓存的I/O操作是 直接I/O,在系统调用时要指定O_DIRECT标志。
文件读写时,先经过系统页缓存、然后在通过系统调用落实到磁盘,这样的I/O操作是 非直接I/O。
在一些特殊场景中,譬如数据库,会连操作系统的文件系统一起跳过,直接读写磁盘, 这种操作通常称为 裸I/O。
程序是否阻塞自身运行:阻塞和非阻塞I/O
如果程序要等收到I/O操作结果后,才继续执行,这是 阻塞I/O。
如果程序发起I/O操作后,不等结果返回继续执行其它操作,以轮询或者事件的方式获得I/O操作结果, 这是 非阻塞I/O。
程序是否等待响应结果:同步和异步I/O
发起I/O操作,需要等整个I/O完成后才返回响应,这是 同步I/O。
发起I/O操作,不需要等整个I/O完成,I/O操作结束后,响应以事件的形式通知调用者,这是 异步I/O。
操作文件时,如果设置了O_DSYNC或者O_SYNC标志,表示同步I/O,前者要等文件写入磁盘以后才返回,后者要在前者的基础,继续等待文件的元数据写入磁盘后再返回。
操作管道或者Socket时,如果设置了O_ASYNC,表示异步I/O,当文件可读写时,内核发送SIGIO或者SIGPOLL。
参考
Linux系统的IO状态
dstat查看系统整体IO状态
dstat同时展示CPU、磁盘IO和网络IO的状态,以及系统中断、内存换页和上下文切换数量,用yum直接安装即可:
yum install -y dstat
dstat的运行效果如下,1表示每1秒输出一次,10表示一共输出10组数据:

iostat查看磁盘设备IO状态
iostat呈现的数据来自/proc/diskstats,-d -x 显示所有磁盘的I/O情况。
$ iostat -d -x 1
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 0.01 0.43 0.19 74.76 1.59 243.28 0.06 4.63 1.67 11.27 97.45 6.12
vdb 0.00 0.00 0.72 0.01 146.07 0.19 402.12 0.00 1.43 1.26 11.25 0.15 0.01
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 0.00 1.00 0.00 8.00 0.00 16.00 0.00 4.00 4.00 0.00 4.00 0.40
vdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
vdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
rrqm/s:每秒合并读请求数
r/s:每秒发送给磁盘的读请求数(合并后)
rkB/s:每秒从磁盘读取的数据量,单位KB
r_await:读响应时间,单位毫秒
wrqm/s: 合并写请求速率
w/s:每秒发送给磁盘的写请求数(合并后)
wkB/s:每秒向磁盘写入的数据量,单位KB
w_await:写响应时间,单位毫秒
avgqu-sz/aqu-sz:平均请求队列长度
svctm: 推断的处理I/O请求需要的平均时间,单位是毫秒
%util:磁盘处理I/O的时间占比,即使用率,使用率100%,说明I/O操作多(不等于磁盘饱和,饱和是不能再接收新的读写)
filetop查看读写频繁的文件
filetop是一个bcc工具箱中的一个工具(bcc系列工具见BCC系列工具),它能够动态展示文件的读写情况,由高到低排序。
在CentOS上用yum安装bcc-tools:
yum install -y bcc-tools。
需要注意的是bcc命令被安装在/usr/share/bcc/tools/目录中,该目录默认不在$PATH中。另外,如果内核版本不支持ebpf,bcc-tools中的有些命令使用的时候会报错。filetop在不支持ebpf的内核上可以工作。
$ /usr/share/bcc/tools/filetop
$ /usr/share/bcc/tools/filetop -C # 刷新数据前不清除屏幕,这样可以看到变化情况

opensnoop跟踪系统调用open
opensnoop也是bcc工具箱中的一个,用来跟踪系统调用open,显示被打开的文件:

iotop查看进程I/O排行
iotop动态显示每个线程的IO操作情况,由高到底排序:
Total DISK READ : 0.00 B/s | Total DISK WRITE : 11.28 K/s
Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
329 be/4 nobody 0.00 B/s 3.76 K/s 0.00 % 0.00 % nginx: worker process
446 be/4 root 0.00 B/s 7.52 K/s 0.00 % 0.00 % systemd-journald
12800 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % dockerd
1 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % systemd --switched-root --system --deserialize 21
2 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kthreadd]
3 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [rcu_gp]
pidstat查看进程的I/O状态
pidstat,-d表示展示IO信息,1表示每秒输出一次:
$ pidstat -d 1
13:39:51 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
13:39:52 102 916 0.00 4.00 0.00 0 rsyslogd
每秒读 每秒写 每秒取消的写 I/O延迟
单位KB 单位KB 单位KB 单位时钟周期
如果要查看具体某个进程,使用-p指定进程号,下面间隔 1 秒输出 3 组数据:
$ pidstat -d -p 4344 1 3
06:38:50 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
06:38:51 0 4344 0.00 0.00 0.00 0 app
06:38:52 0 4344 0.00 0.00 0.00 0 app
06:38:53 0 4344 0.00 0.00 0.00 0 app
参考
理解Linux的网络
Linux网络相关知识。
指标和工具映射表


报文处理流程

TCP连接状态

TCP参数调优

其它文章
Finding out if/why a server is dropping packets
需要在masquerade规则中设置flag NF_NAT_RANGE_PROTO_RANDOM_FULLY。iptables工具不支持设定这个flag,但是我们已经提交了一个小补丁增加这个特性,补丁已经合入(译者注:在iptables 1.6.2版本发布)。
我们现在使用一个修改后的打了这个补丁的flannel版本,在masquerade规则中增加了flag --ramdom-fully。我们使用一个简单的Daemonset从每一个节点上获取conntrack的统计结并发送到InfluxDB来监控conntrack表的插入错误。我们已经使用这补丁将近一个月了,整个集群中的错误的数目从每几秒一次下降到每几个小时一次。
参考
网络性能指标
带宽: 最大传输速率,单位b/s(比特/秒)。
吞吐量: 单位时间内传输的数据量,b/s或者B/s。
延时:请求发出时与对方收到时的间隔时间,不同场景下含义不同,例如TCP握手延迟,数据包往返延迟(RTT)。
PPS: 每秒传输的报文数(不论报文大小),硬件交换机通常可以达到线速,Linux服务器一般达不到。
并发连接数: tcp连接数量。
丢包率: 丢失报文占比。
重传率: 重传报文占比。
hping3检测延迟
hping3的用法:-c 表示发送3次请求,-S 表示设置TCP SYN,-p 表示端口号为80(yum安装:yum install -y hping3)。
$ hping3 -c 3 -S -p 80 baidu.com
HPING baidu.com (eth0 123.125.115.110): S set, 40 headers + 0 data bytes
len=46 ip=123.125.115.110 ttl=51 id=47908 sport=80 flags=SA seq=0 win=8192 rtt=20.9 ms
len=46 ip=123.125.115.110 ttl=51 id=6788 sport=80 flags=SA seq=1 win=8192 rtt=20.9 ms
len=46 ip=123.125.115.110 ttl=51 id=37699 sport=80 flags=SA seq=2 win=8192 rtt=20.9 ms
--- baidu.com hping statistic ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 20.9/20.9/20.9 ms
traceroute检测延迟
traceroute的用法:--tcp 表示使用 TCP 协议,-p 表示端口号,-n 表示不对结果中的 IP 地址执行反向域名解析(yum安装:yum install -y traceroute)。
$ traceroute --tcp -p 80 -n baidu.com
traceroute to baidu.com (123.125.115.110), 30 hops max, 60 byte packets
1 * * *
2 * * *
3 * * *
4 * * *
5 * * *
6 * * *
7 * * *
8 * * *
9 * * *
10 * * *
11 * * *
12 * * *
13 * * *
14 123.125.115.110 20.684 ms * 20.798 ms
pktgen发包
pktgen是内核自带的发包工具,networking/pktgen.txt,Intel提供了一个基于DPDK的同名工具The Pktgen Application。
参考
网卡状态
多种方式查看网卡信息
ifconfig、netstat(yum install -y net-tool)或者ip(yum install -y iproute2)查看网卡详情。
$ ifconfig eth0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1454
inet 192.168.7.222 netmask 255.255.0.0 broadcast 10.19.255.255
ether 52:54:00:33:70:30 txqueuelen 1000 (Ethernet)
RX packets 2973979082 bytes 1977239275436 (1.7 TiB)
RX errors 0 dropped 53 overruns 0 frame 0
TX packets 2157378511 bytes 3340384739019 (3.0 TiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
$ netstat -i
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
docker0 1426 290827246 0 0 0 309655306 0 0 0 BMRU
eth0 1454 214759910523 0 1296 0 193020803000 0 0 0 BMRU
flannel0 1426 118667062225 0 0 0 110488702382 0 6361 0 MOPRU
lo 65536 184456359 0 0 0 184456359 0 0 0 LRU
lo:1 65536 - no statistics available - LRU
vethba02 1426 74175712 0 0 0 80134415 0 0 0 BMRU
$ ip -s -d addr
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1454 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:33:70:30 brd ff:ff:ff:ff:ff:ff promiscuity 0
inet 192.168.7.222/16 brd 10.19.255.255 scope global eth0
valid_lft forever preferred_lft forever
RX: bytes packets errors dropped overrun mcast
1977612295437 2974994116 0 53 0 0
TX: bytes packets errors dropped carrier collsns
3341796453985 2158430374 0 0 0 0
运行状态: RUNNING,LOWER_UP。
MTU:1454。
地址:IP、MAC。
报文收发情况: RX是接收的报文,TX是发送的报文。
errors: 错误报文数,校验错误、帧错误等。
dropped: 丢弃的报文数,报文已经进入ring buffer,但是因为内存不足丢弃。
overruns: 超限制报文数,因ring buffer已满而丢弃的报文。
carrier: 双工模式不匹配、电缆故障等导致的错误。
collisions:冲突报文数。
用sar查看网卡吞吐
用sar查看网卡的吞吐情况,-n查看网络状态,DEV查看设备状态(除了DEV,还支持:EDEV、 NFS、 NFSD、 SOCK、 IP、 EIP、 ICMP、 EICMP、 TCP、 ETCP、 UDP、 SOCK6、 IP6、 EIP6、 ICMP6、 EICMP6、 UDP6),1每秒刷新一次:
$sar -n DEV 1
Linux 3.10.0-693.11.6.el7.x86_64 (prod-k8s-node-180-92) 04/22/2019 _x86_64_ (32 CPU)
02:04:47 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
02:04:48 PM eth0 1395.00 1186.00 545.40 1902.75 0.00 0.00 0.00
02:04:48 PM flannel0 381.00 299.00 154.24 83.22 0.00 0.00 0.00
02:04:48 PM docker0 1177.00 1336.00 1895.27 530.71 0.00 0.00 0.00
接收和发送的pps: rxpck/s、txpck/s。
接收和发送的字节数:rxkB/s、txkB/s。
接收和发送的压缩数据包数:rxcmp/s、txcmp/s。
参考
Linux的连接与协议栈状态的查看方法
netstat查看连接状态分布
用netstat查看连接状态的分布(用yum安装:yum install -y net-tools):
$ netstat -nat|awk '{print awk $NF}'|sort|uniq -c|sort -n
1 CLOSE_WAIT
1 FIN_WAIT2
1 State
1 established)
3 LAST_ACK
30 FIN_WAIT1
151 LISTEN
280 TIME_WAIT
1548 ESTABLISHED
查看本地临时端口占用情况
$ netstat -ntp |grep "11.0.110.0" |awk '{print $4}' |sort |uniq |wc
18171 18171 308907
查看本地源端口范围:
$ sysctl net.ipv4.ip_local_port_range
$ cat /proc/sys/net/ipv4/ip_local_port_range
设置本地源端口范围:
sysctl -w net.ipv4.ip_local_port_range="1024 64000"
临时端口不足时,Nginx会报下面的错误:
(99: Cannot assign requested address) while connecting to upstream, client: 192.168.0.2, server: localhost, request: "GET / HTTP/1.1", upstream: "fastcgi://127.0.0.1:9000", host: "192.168.0.30"
netstat/ss查看单个连接状态
用netstat查看详细连接,-t查看tcp连接,-u查看udp连接,-p显示对应进程:
$ netstat -ntp
Active Internet connections (w/o servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 11.0.157.1:32888 11.0.157.6:8080 TIME_WAIT -
tcp 0 0 11.0.157.1:45894 11.0.157.4:8080 TIME_WAIT -
tcp 0 0 11.0.157.1:35826 11.0.157.9:8080 TIME_WAIT -
tcp 0 0 11.0.157.1:57348 11.0.157.3:8080 TIME_WAIT -
tcp 0 0 127.0.0.1:54728 127.0.0.1:10248 TIME_WAIT -
ss命令是netstat的替代命令:
$ ss -ntp
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 0 10.19.180.92:10250 10.19.14.106:38292 users:(("kubelet",pid=15242,fd=41))
ESTAB 0 0 10.19.180.92:35154 10.19.61.146:2379 users:(("flanneld",pid=1042,fd=10))
ESTAB 0 0 10.19.180.92:45380 10.19.162.39:6443 users:(("kube-proxy",pid=14013,fd=8))
当套接字是连接状态时,Established:
Recv-Q:套接字接收队列中还没有被应用程序读取的字节数。
Send-Q:套接字发送队列中还没有被远端主机确认的字节数。
当套接字是监听状态时,Listening,显示的半连接状态,即服务端收到客户端SYN,还没有完成三次握手的TCP连接:
Recv-Q:TCP协议栈中的半连接队列长度的当前值,syn backlog当前值。
Send-Q:TCP协议栈中的半连接队列长度的最大值,syn backlog最大值。
套接字是Established状态时,如果Recv-Q和Send-Q不为零,说明接收的数据无法被应用程序及时读取,以及应用的数据无法及时发送,是异常情况。
问题:如果是UDP协议呢?Rece-Q和Send-Q的含义是什么?同Established。
netstat查看协议栈状态
netstat -s打印出整个协议栈的状态,按照协议类型分开展示:
$ netstat -s
Ip:
3635473208 total packets received
2855004908 forwarded
0 incoming packets discarded
769088666 incoming packets delivered
3701098707 requests sent out
44 dropped because of missing route
Icmp:
100236 ICMP messages received
0 input ICMP message failed.
ICMP input histogram:
destination unreachable: 995
redirects: 4
echo requests: 99229
echo replies: 8
114887 ICMP messages sent
0 ICMP messages failed
ICMP output histogram:
destination unreachable: 15658
echo replies: 99229
IcmpMsg:
InType0: 8
InType3: 995
InType5: 4
InType8: 99229
OutType0: 99229
OutType3: 15658
Tcp:
3716853 active connections openings
1228040 passive connection openings
570 failed connection attempts
610 connection resets received
17 connections established
33850465 segments received
43122661 segments send out
15575 segments retransmited
4 bad segments received.
1018 resets sent
Udp:
735086502 packets received
6 packets to unknown port received.
33475 packet receive errors
797838180 packets sent
33475 receive buffer errors
0 send buffer errors
UdpLite:
TcpExt:
28250 invalid SYN cookies received
3961 resets received for embryonic SYN_RECV sockets
21371 packets pruned from receive queue because of socket buffer overrun
72874448 TCP sockets finished time wait in fast timer
1396 packets rejects in established connections because of timestamp
6946924 delayed acks sent
128318 delayed acks further delayed because of locked socket
Quick ack mode was activated 49028 times
1292037 packets directly queued to recvmsg prequeue.
33405 bytes directly in process context from backlog
566548477 bytes directly received in process context from prequeue
420652665 packet headers predicted
1255272 packets header predicted and directly queued to user
285092354 acknowledgments not containing data payload received
...
限制半开连接
半开连接最大数量:
sysctl net.ipv4.tcp_max_syn_backlog
net.ipv4.tcp_max_syn_backlog = 256
限制半开连接建立速度:
# 限制 syn 并发数为每秒 1 次
$ iptables -A INPUT -p tcp --syn -m limit --limit 1/s -j ACCEPT
# 限制单个 IP 在 60 秒新建立的连接数为 10
$ iptables -I INPUT -p tcp --dport 80 --syn -m recent --name SYN_FLOOD --update --seconds 60 --hitcount 10 -j REJECT
启动synccookie:
sysctl -w net.ipv4.tcp_syncookies=1
net.ipv4.tcp_syncookies = 1
参考
Linux的netfilter

连接跟踪表参数
连接跟踪表tcp超时时间,默认120秒:
sysctl net.netfilter.nf_conntrack_tcp_timeout_time_wait
net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120
连接跟踪表大小设置:
$ sysctl net.netfilter.nf_conntrack_max=131072 //跟踪表的总容量
$ sysctl net.netfilter.nf_conntrack_buckets=65536 //跟踪表的桶数量
连接跟踪表内存开销计算,连接跟踪对象大小为376,链表项大小为16:
nf_conntrack_max* 连接跟踪对象大小 +nf_conntrack_buckets* 链表项大小
= 1000*376+65536*16 B
= 1.4 MB
conntrack查看连接跟踪表的内容
conntrack查看连接跟踪表的内容, -L 表示列表,-o 表示以扩展格式显示:
$ conntrack -L -o extended
ipv4 2 tcp 6 7 TIME_WAIT src=192.168.0.2 dst=192.168.0.96 sport=51744 dport=8080 src=172.17.0.2 dst=192.168.0.2 sport=8080 dport=51744 [ASSURED] mark=0 use=1
ipv4 2 tcp 6 6 TIME_WAIT src=192.168.0.2 dst=192.168.0.96 sport=51524 dport=8080 src=172.17.0.2 dst=192.168.0.2 sport=8080 dport=51524 [ASSURED] mark=0 use=1
统计总的连接跟踪数
$ conntrack -L -o extended | wc -l
14289
统计TCP协议各个状态的连接跟踪数
$ conntrack -L -o extended | awk '/^.*tcp.*$/ {sum[$6]++} END {for(i in sum) print i, sum[i]}'
SYN_RECV 4
CLOSE_WAIT 9
ESTABLISHED 2877
FIN_WAIT 3
SYN_SENT 2113
TIME_WAIT 9283
统计各个源IP的连接跟踪数
$ conntrack -L -o extended | awk '{print $7}' | cut -d "=" -f 2 | sort | uniq -c | sort -nr | head -n 10
14116 192.168.0.2
172 192.168.0.96
参考
报文追踪
用stap和perf定位丢失的报文
stap的安装方法:
yum install systemtap kernel-devel yum-utils kernel
stab-prep
用下面的脚本跟踪内核函数kfree_skb的调用位置,也就是丢弃报文的位置:
#! /usr/bin/env stap
############################################################
# Dropwatch.stp
# Author: Neil Horman <[email protected]>
# An example script to mimic the behavior of the dropwatch utility
# http://fedorahosted.org/dropwatch
############################################################
# Array to hold the list of drop points we find
global locations
# Note when we turn the monitor on and off
probe begin { printf("Monitoring for dropped packets\n") }
probe end { printf("Stopping dropped packet monitor\n") }
# increment a drop counter for every location we drop at
probe kernel.trace("kfree_skb") { locations[$location] <<< 1 }
# Every 5 seconds report our drop locations
probe timer.sec(5)
{
printf("\n")
foreach (l in locations-) {
printf("%d packets dropped at %s\n",
@count(locations[l]), symname(l))
}
delete locations
}
输出结果样式如下,下面的输出表明报文在nf_hook_slow中被丢弃:
10031 packets dropped at nf_hook_slow
676 packets dropped at tcp_v4_rcv
7284 packets dropped at nf_hook_slow
268 packets dropped at tcp_v4_rcv
用perf进一步定位,在perf report中展开内核函数nf_hook_slow:
$ perf record -a -g -- sleep 30
$ perf report -g graph,0

tcpdump捕获报文
tcpdump过滤表达式:

参考
DNS解析追踪
dig跟踪dns解析过程
dig可以跟踪dns的解析过程,+trace 表示开启跟踪查询,+nodnssec 表示禁止 DNS 安全扩展:
$ dig +trace +nodnssec time.geekbang.org
; <<>> DiG 9.11.3-1ubuntu1.3-Ubuntu <<>> +trace +nodnssec time.geekbang.org
;; global options: +cmd
. 322086 IN NS m.root-servers.net.
. 322086 IN NS a.root-servers.net.
. 322086 IN NS i.root-servers.net.
. 322086 IN NS d.root-servers.net.
. 322086 IN NS g.root-servers.net.
. 322086 IN NS l.root-servers.net.
. 322086 IN NS c.root-servers.net.
. 322086 IN NS b.root-servers.net.
. 322086 IN NS h.root-servers.net.
. 322086 IN NS e.root-servers.net.
. 322086 IN NS k.root-servers.net.
. 322086 IN NS j.root-servers.net.
. 322086 IN NS f.root-servers.net.
;; Received 239 bytes from 114.114.114.114#53(114.114.114.114) in 1340 ms
org. 172800 IN NS a0.org.afilias-nst.info.
org. 172800 IN NS a2.org.afilias-nst.info.
org. 172800 IN NS b0.org.afilias-nst.org.
org. 172800 IN NS b2.org.afilias-nst.org.
org. 172800 IN NS c0.org.afilias-nst.info.
org. 172800 IN NS d0.org.afilias-nst.org.
;; Received 448 bytes from 198.97.190.53#53(h.root-servers.net) in 708 ms
geekbang.org. 86400 IN NS dns9.hichina.com.
geekbang.org. 86400 IN NS dns10.hichina.com.
;; Received 96 bytes from 199.19.54.1#53(b0.org.afilias-nst.org) in 1833 ms
time.geekbang.org. 600 IN A 39.106.233.176
;; Received 62 bytes from 140.205.41.16#53(dns10.hichina.com) in 4 ms

参考
Linux高性能网络IO处理
单进程模式:select、poll与epoll
select和poll都是非阻塞的,监视一组文件描述的读写状态,对满足条件的文件描述符进行操作,实现单线程处理多请求。select监控的文件描述符数量有限制,32位系统默认1024个,poll对select进行了改进,只受系统文件描述符数量的限制。
select和poll采用的都是轮询文件描述符列表的方式,效率较低,并且文件描述符要在用户空间和内核空间来回传送,增加了处理成本。
epoll在内核中用红黑树管理文件描述符集合,避免了文件描述符的传递,同时使用事件驱动机制,不需要轮询文件描述符集合。
多进程模式1:主进程+多子进程
主进程初始化套接字bind()+listen()、管理子进程的生命周期,子进程通过accpet()、epoll_wait()处理相同的套接字。accept和epoll存在“惊群”问题,accept在Linux2.6中解决了,epoll在Linux4.5中,通过EPOLLEXCLUSIVE解决。
惊群: 网络I/O事件发生时,同时有多个进程被唤醒,但最终只有一个进程响应事件,其它进程被不必要的唤醒。
多进程模式2:端口复用
Linux3.9提供了SO_REUSEPORT,支持多进程复用同一个端口,内核保证将到达该端口的请求均衡分发给监听的进程。同时内核确保只有进程被唤醒,不存在惊群的问题。

绕过内核协议栈1:DPDK
DPDK直接在用户态轮询硬件网卡,绕过了内核协议栈,还通过huagepage、cpu绑定、内存对齐、流水线并发等多种机制,提高报文的处理效率:

绕过内核协议栈2:XDP
XDP(eXpress Data Path)是Linux内核(4.8以上)提供的高性能网络数据路径,在网络包进入内核协议栈之前进行处理。XDP是基于Linux内核的eBPF机制实现的:

参考
Linux性能分析常用工具
这里汇总Linux性能分析时常用的工具,内容力求简洁明了,适合作为速查手册使用。
参考
火焰图介绍
火焰图是一个非常好的分析工具,可以直观地显示每个函数耗费的时间占比。
火焰图是性能优化领域大神Brendan D. Gregg的杰作,他在Flame Graphs一文里详细介绍了火焰图的用法。 并且贡献了一个火焰生成工具FlameGraph,这个工具可以将调用栈采样数据转换成火焰图,Perf Examples中提到了它的用法。采样数据也可以用其它工具采集,比如OpenResty的作者章宜春贡献的stapxx。
Brendan D. Gregg的英文文章看起来吃力,可以参考阮一峰写的如何读懂火焰图?。
火焰图是这个样子的(它是一个动态图,右键查看图像):

横向是按照字母顺序排序的函数名,每个函数的宽度占比等于这个函数在采样中出现次数占比,也就等同于它耗费的时间比例。越宽的函数,耗费的的时间占比越大。
纵向是调用关系,上层的函数被下层的函数调用,最上层的函数是采样时正在占用CPU的函数。
如果在最上层存在很宽的函数,那么这个函数就是导致性能无法提升的罪魁祸首,需要重点分析优化。
火焰图的颜色没有特殊含义,只是为了方便查看,每个函数的颜色都是随机生成的,千万不要误以为和颜色有关,你应当关注的是函数的宽度。
任何性能工具生成的采用数据都可以用来生成火焰图:
Linux: perf, eBPF, SystemTap, and ktap
Solaris, illumos, FreeBSD: DTrace
Mac OS X: DTrace and Instruments
Windows: Xperf.exe
八卦一下:
Brendan D. Gregg在文章中写道,他是在解决MySQL的性能问题时,产生了火焰图的创意。但是他采集了很多的文本数据,不方便查看,于是研究了一下怎样将采样数据可视化。他借鉴了Neelakanth and Roch的相关研究,用采样占比取代了时间占比,只选取了暖色调的颜色,生成了火焰一般的图形。这项工作是在2011年完成。
后来火焰图的创意被Google借鉴,植入了Chrome浏览器,用来分析网页性能,在开发者工具的性能选项卡中可以看到,不过chrome中的火焰图和这里的火焰图不一样,它的x轴是时间轴,并且是倒火焰形状,上层函数调用下层函数。
在具体使用上,火焰图可以用来分析CPU占用情况、内存申请情况、未占用CPU时的情况,并且演化出“冷热(aHHot/Code)和“差异火焰图(Differential)”。
参考
用火焰图分析CPU占用情况
CPU火焰图是最常用、最好理解的火焰图,它展现的是函数对CPU的占用情况,火焰图最上层是采样时正在使用CPU的函数:

CPU火焰图展现的是在CPU上发生的事情,下图中的红色部分(蓝色部分是CPU之外的事情,用后文中的Off-CPU火焰图展现):

CPU火焰图最常用也最简单,CPU Flame Graphs介绍了几种制作方法,给出了C/C++/Jave/Node.js,以及其它语言编写的应用的CPU火焰图生成方法。
几种常用的采样工具
perf
用perf采集指定CPU上发生的事件:
perf record -F 99 -C 1,3 -g
DTrace
SystemTap
ktap
参考
用内存火焰图分析内存泄露
内存泄露已经有几种分析工具,例如通过模拟运行进行分析的Valgrind,可以统计内存堆(heap)使用情况的libtcmalloc链接库。
相比已有的工具,内存火焰图是非侵入式的旁路分析方法,不干扰目标应用的运行。制作CPU火焰图时,采样时捕捉的是正在占用CPU的函数的调用栈,制作内存火焰图时,采样时捕捉的是正在进行内存申请/释放的函数的调用栈。
进程的内存空间如下图所示,都是通过malloc()、free()等几个函数申请或释放内存:
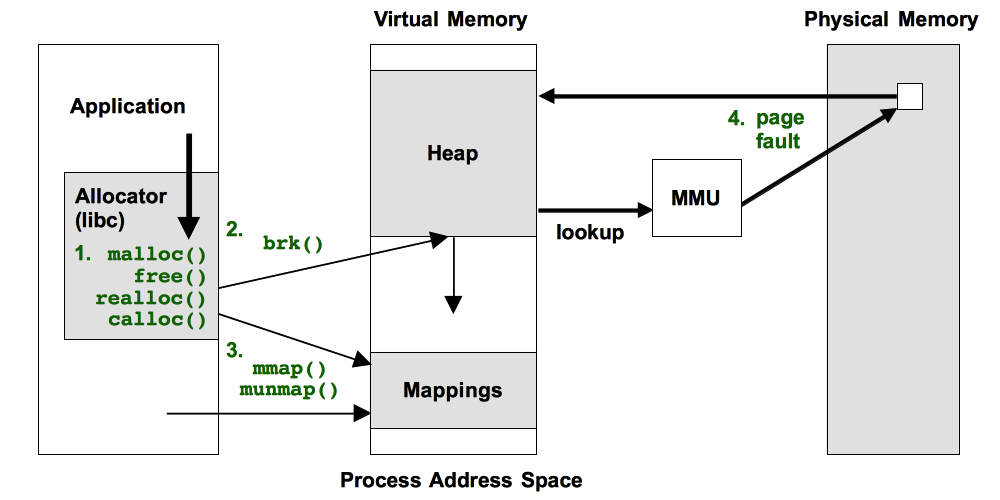
以这些内存管理函数为目标进行采样,就可以知道哪些函数正在频繁的使用这些内存管理函数,例如下图是以malloc函数为目标进程采样的结果:

火焰图的横轴依旧是按字母顺序排列的函数,宽度代表函数在采样结果中出现的比例,纵轴依然是调用栈,上层函数被下层函数调用。但是,最顶层的函数的含义发生了变化,在CPU火焰图中,最顶层的函数是正在使用CPU的函数,在内存火焰图中,最顶层的函数是正在使用指定的内存管理函数的函数。
malloc()等函数的采集
brk()函数的采集
mmap()函数的采集
缺页(Page Faults)采集
参考
用火焰图分析未占用CPU期间的情况
应用程序的效率不高,也可能是被CPU之外的资源限制卡住了。
Brendan D. Gregg在Off-CPU Analysis一文中阐述了这个想法:
Performance issues can be categorized into one of two types:
On-CPU: where threads are spending time running on-CPU.
Off-CPU: where time is spent waiting while blocked on I/O, locks, timers, paging/swapping, etc.
通常我们更容易关注On-CPU上发生的事情,容易忽略Off-CPU期间发生的事情,Off-CPU仿佛水面下的冰山(下图中的蓝色部分) :
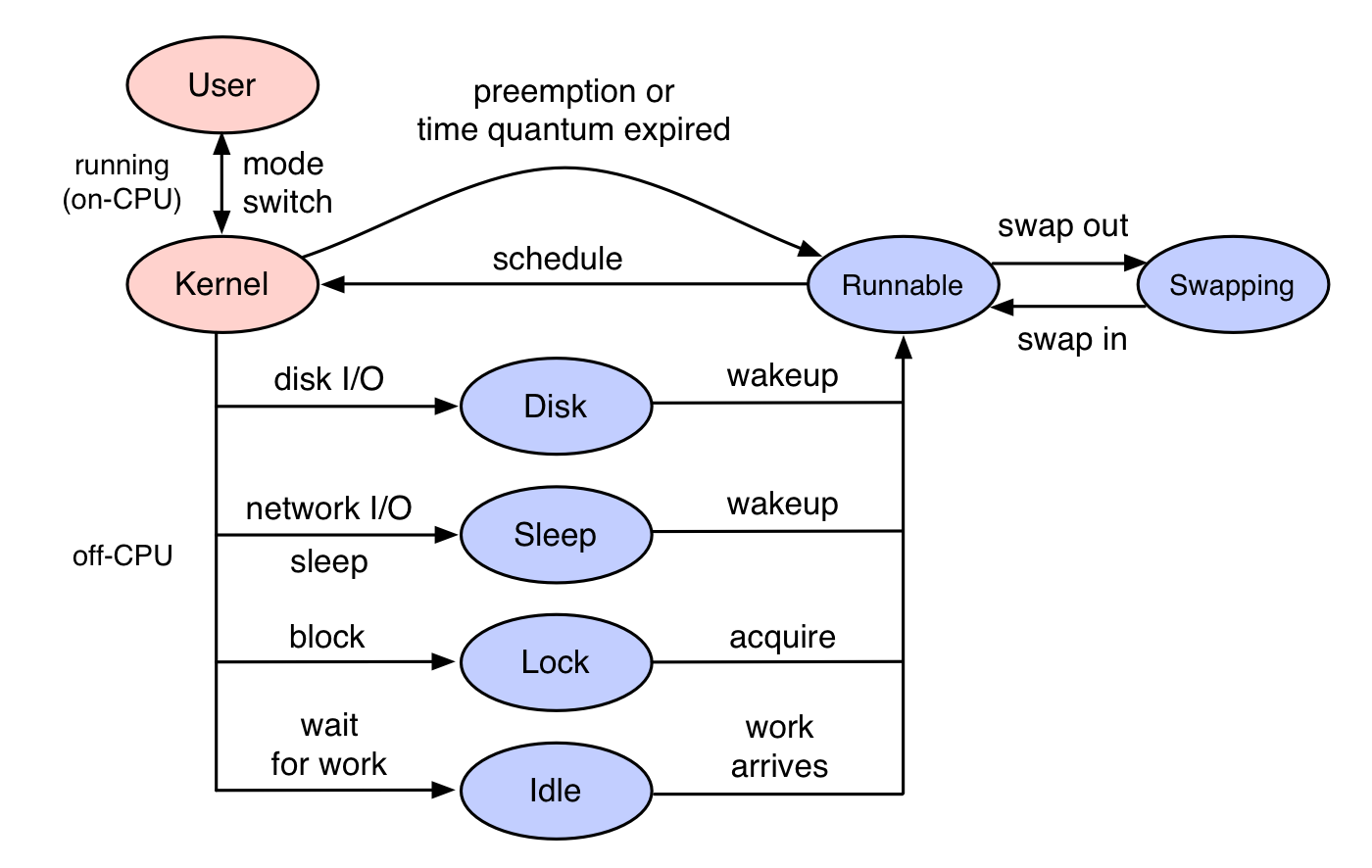
章宜春最早践行了Off-CPU的想法,在Introduction to offCPU Time Flame Graphs中生动简洁地介绍了自己的实践过程。
与内存管理函数有多个一样,Off-CPU期间是有多件事情的:

I/O期间有File I/O、Block Device I/O,通过采集进程让出CPU时调用栈,可以知道哪些函数正在频繁地等待其它事件,以至于需要让出CPU,通过采集进程被唤醒时的调用栈,可以知道哪些函数让进程等待的时间比较长。
File I/O 火焰图

Block I/O 火焰图

Off-CPU 火焰图

Wakeup 火焰图

参考
冷热火焰图:将On-CPU火焰图与Off-CPU火焰图合并
把On-CPU火焰图和Off-CPU火焰图合并在一起或许更便于分析。
独立排列
这种方式其实就是放在一起而已,勉强算是一种融合方法吧。

共享横轴
这种方式是将火焰图的横轴轴对接起来共用,纵轴上依然是泾渭分明,有明确的边界:

融合显示
这种方式是尽可能的On-CPU和Off-CPU糅合在一起:

参考
差异火焰图:展示两个火焰图之间的差异
火焰图是用来做性能分析的,通过火焰度了解了程序运行期间的情况以后,接下来是有针对性地修改调优。 调整之后,还需要在制作一个新的火焰图,通过对比调优前和调优后的火焰图,评估调整是否有效。
有时候可能发现系统升级之后,某些指标突然升高,这时候也可以对比升级前和升级后的火焰图,找到那些耗时增加的函数。
最简单的对比方式就是将修改前后两个火焰图并行排列,肉眼找不同,这样显然很不方便。Brendan Gregg想出了一招:差异火焰图(Differential Flame Graphs)。
在最近一次制作的火焰图上,耗时相比前一次增加的函数用红色,耗时减少的函数用蓝色:

参考
火焰图生成命令
火焰图的生成分为采集数据和生成图片两个过程,这两个过程中有多种工具可选。
采集数据的工具可以根据自己实际情况、喜好以及熟悉程度选取。
生成图片时,一般使用FlameGraph就足够了。
用perf采集调用栈(On CPU)
CPU Flame Graphs的Instructions章节中给出了用perf采集的方法。
pid=目标进程
perf record -p $pid -F 99 -a -g
采集的数据位于当前目录中的perf.data文件中,用perf script转换成可读格式:
perf script > perf.bt
用FlameGraph中的stackcollapse-perf.pl和flamegraph.pl生成火焰图:
./FlameGraph/stackcollapse-perf.pl perf.bt >perf.cbt
./FlameGraph/flamegraph.pl perf.cbt > perf.svg
用stapxx采集调用栈(On CPU)
注意:在采集envoy的调用栈(On CPU)时,发现perf效果更好,采集得更精细和准确。
stapxx是OpenResty作者章宜春开发的一套脚本,简化了用SystemTAP采集数据的操作。
需要事先安装SystemTAP以及kernel的debuginfo包,具体安装安装过程参考Web开发平台OpenResty(三):火焰图性能分析,这里不赘述。
安装了SystemTAP等依赖包之后,下载stapxx脚本:
git clone https://github.com/openresty/stapxx
export PATH=$PATH:`pwd`/stapxx
stapxx/samples目录中提供了很多脚本,大部分是用于openresty的,但也有很多通用的脚本,譬如sample-bt.sxx、cpu-hogs.sxx等。
$ ls stapxx/samples/
cpu-hogs.sxx ngx-lj-gc-speed.sxx ngx-rps.sxx
cpu-robbers.sxx ngx-lj-trace-exits.sxx ngx-single-req-latency.sxx
ctx-switches.sxx ngx-lua-count-timers.sxx ngx-slow-purge-reqs.sxx
epoll-et-lt.sxx ngx-lua-exec-time.sxx ngx-sr-trunc.sxx
epoll-loop-blocking-distr.sxx ngx-lua-shdict-info.sxx ngx-timeout-settings.sxx
epoll-loop-blocking.sxx ngx-lua-shdict-writes.sxx ngx-upstream-err-log.sxx
epoll-loop-blocking-vfs.sxx ngx-lua-slow-udp-query.sxx ngx-upstream-latency.sxx
func-latency-distr.sxx ngx-lua-tcp-recv-time.sxx ngx-upstream-next.sxx
lj-bucket-depth-accessed.sxx ngx-lua-tcp-total-recv-time.sxx ngx-upstream-post-conn.sxx
lj-find-str.sxx ngx-lua-udp-recv-time.sxx ngx-zlib-deflate-time.sxx
lj-gc-objs.sxx ngx-lua-udp-total-recv-time.sxx ngx-zlib-total-deflate-time.sxx
lj-gc.sxx ngx-lua-useless-cosockets.sxx openssl-handshake-diagnosis.sxx
lj-lua-bt.sxx ngx-open-file-cache-misses.sxx probe-rate.sxx
lj-lua-stacks.sxx ngx-orig-resp-body-len.sxx sample-bt-leaks.sxx
lj-str-tab.sxx ngx-pcre-dist.sxx sample-bt-leaks-wrapalloc.sxx
lj-trace-exit-rate.sxx ngx-pcre-top.sxx sample-bt.sxx
lj-vm-states.sxx ngx-req-latency-distr.sxx slow-vfs-reads.sxx
luajit21-gc64 ngx-req-pool-allocs.sxx unix-stream-socks.sxx
ngx-conn-timers.sxx ngx-req-pool-size.sxx vfs-page-cache-misses.sxx
ngx-count-conns.sxx ngx-rewrite-latency-distr.sxx zlib-deflate-chunk-size.sxx
这些脚本的用法在README中有说明,这里只演示部分脚本的用法。
采集指定进程的调用栈:
pid=目标进程
./stapxx/samples/sample-bt.sxx --arg time=20 --skip-badvars -D MAXSKIPPED=100000 -D MAXMAPENTRIES=100000 -x $pid >resty.bt
用FlameGraph中的stackcollapse-stap.pl和flamegraph.pl生成火焰图:
git clone https://github.com/brendangregg/FlameGraph.git
./FlameGraph/stackcollapse-stap.pl resty.bt >resty.cbt
./FlameGraph/flamegraph.pl resty.cbt > resty.svg
参考
BCC系列工具
使用方法见bcc Tutorial
参考
CPU使用率很高的排查方法
这是倪鹏飞的《Linux性能优化实战》中的案例,这里做了二次加工,抽取了主要过程,案例是倪鹏飞原文中的。
{kind=link}
用top查看CPU使用情况
在top中看CPU的使用率很高,达到了80%以上,但是每个进程的CPU使用率都很低:
$ top
...
%Cpu(s): 80.8 us, 15.1 sy, 0.0 ni, 2.8 id, 0.0 wa, 0.0 hi, 1.3 si, 0.0 st
...
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
6882 root 20 0 8456 5052 3884 S 2.7 0.1 0:04.78 docker-containe
6947 systemd+ 20 0 33104 3716 2340 S 2.7 0.0 0:04.92 nginx
7494 daemon 20 0 336696 15012 7332 S 2.0 0.2 0:03.55 php-fpm
7495 daemon 20 0 336696 15160 7480 S 2.0 0.2 0:03.55 php-fpm
10547 daemon 20 0 336696 16200 8520 S 2.0 0.2 0:03.13 php-fpm
10155 daemon 20 0 336696 16200 8520 S 1.7 0.2 0:03.12 php-fpm
10552 daemon 20 0 336696 16200 8520 S 1.7 0.2 0:03.12 php-fpm
15006 root 20 0 1168608 66264 37536 S 1.0 0.8 9:39.51 dockerd
4323 root 20 0 0 0 0 I 0.3 0.0 0:00.87 kworker/u4:1
...
用pidstat查看进程状态
每间隔1秒输出一组进程的状态,每个进程的CPU使用率都不高:
$ pidstat 1
...
04:36:24 UID PID %usr %system %guest %wait %CPU CPU Command
04:36:25 0 6882 1.00 3.00 0.00 0.00 4.00 0 docker-containe
04:36:25 101 6947 1.00 2.00 0.00 1.00 3.00 1 nginx
04:36:25 1 14834 1.00 1.00 0.00 1.00 2.00 0 php-fpm
04:36:25 1 14835 1.00 1.00 0.00 1.00 2.00 0 php-fpm
04:36:25 1 14845 0.00 2.00 0.00 2.00 2.00 1 php-fpm
04:36:25 1 14855 0.00 1.00 0.00 1.00 1.00 1 php-fpm
04:36:25 1 14857 1.00 2.00 0.00 1.00 3.00 0 php-fpm
04:36:25 0 15006 0.00 1.00 0.00 0.00 1.00 0 dockerd
04:36:25 0 15801 0.00 1.00 0.00 0.00 1.00 1 pidstat
04:36:25 1 17084 1.00 0.00 0.00 2.00 1.00 0 stress
04:36:25 0 31116 0.00 1.00 0.00 0.00 1.00 0 atopacctd
...
观察top中的tasks
top中显示149个task,有6个在running状态,正在运行的进程数偏高(案例中的机器上,只运行了一个php开发的web应用,用ab对其发起了5个并发的压测)。
$ top
top - 04:58:24 up 14 days, 15:47, 1 user, load average: 3.39, 3.82, 2.74
Tasks: 149 total, 6 running, 93 sleeping, 0 stopped, 0 zombie
%Cpu(s): 77.7 us, 19.3 sy, 0.0 ni, 2.0 id, 0.0 wa, 0.0 hi, 1.0 si, 0.0 st
KiB Mem : 8169348 total, 2543916 free, 457976 used, 5167456 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 7363908 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
6947 systemd+ 20 0 33104 3764 2340 S 4.0 0.0 0:32.69 nginx
6882 root 20 0 12108 8360 3884 S 2.0 0.1 0:31.40 docker-containe
15465 daemon 20 0 336696 15256 7576 S 2.0 0.2 0:00.62 php-fpm
15466 daemon 20 0 336696 15196 7516 S 2.0 0.2 0:00.62 php-fpm
15489 daemon 20 0 336696 16200 8520 S 2.0 0.2 0:00.62 php-fpm
6948 systemd+ 20 0 33104 3764 2340 S 1.0 0.0 0:00.95 nginx
15006 root 20 0 1168608 65632 37536 S 1.0 0.8 9:51.09 dockerd
15476 daemon 20 0 336696 16200 8520 S 1.0 0.2 0:00.61 php-fpm
15477 daemon 20 0 336696 16200 8520 S 1.0 0.2 0:00.61 php-fpm
24340 daemon 20 0 8184 1616 536 R 1.0 0.0 0:00.01 stress
24342 daemon 20 0 8196 1580 492 R 1.0 0.0 0:00.01 stress
24344 daemon 20 0 8188 1056 492 R 1.0 0.0 0:00.01 stress
24347 daemon 20 0 8184 1356 540 R 1.0 0.0 0:00.01 stress
...
同时,top中显示正在运行的进程是stress。
用pidstat/ps查看running状态的进程
用pidstat查看running状态的stress进程,结果没有该进程的数据:
$ pidstat -p 24344
16:14:55 UID PID %usr %system %guest %wait %CPU CPU Command
用ps查看,发现这个进程不存在:
$ ps aux | grep 24344
root 9628 0.0 0.0 14856 1096 pts/0 S+ 16:15 0:00 grep --color=auto 24344
到了关键时刻,为什么正在running的进程不存在,这些消失的进程和cpu的使用率高有没有关系?
再次用top观察running状态的进程,发现stress进程的进程号一直变化。也就是说,stress进程不停的退出, 同时又不断的新建。
用pstree查看进程的父子关系
用pstree找到创建stress进程的父进程,stress进程是php-fpm通过sh创建的:
$ pstree | grep stress
|-docker-containe-+-php-fpm-+-php-fpm---sh---stress
| |-3*[php-fpm---sh---stress---stress]
pstree安装方法:
yum install -y psmisc
检查php应用代码
检查php应用代码发现,代码中调用了stress命令,模拟I/O压力,但是用top看到的现象是cpu使用率高,这是比较奇怪的地方:。
$ cat app/index.php
<?php
// fake I/O with stress (via write()/unlink()).
$result = exec("/usr/local/bin/stress -t 1 -d 1 2>&1", $output, $status);
if (isset($_GET["verbose"]) && $_GET["verbose"]==1 && $status != 0) {
echo "Server internal error: ";
print_r($output);
} else {
echo "It works!";
}
?>
检查这部分代码的运行日志,发现stress命令没有成功,因为权限问题直接退出了:
$ curl http://192.168.0.10:10000?verbose=1
Server internal error: Array
(
[0] => stress: info: [19607] dispatching hogs: 0 cpu, 0 io, 0 vm, 1 hdd
[1] => stress: FAIL: [19608] (563) mkstemp failed: Permission denied
[2] => stress: FAIL: [19607] (394) <-- worker 19608 returned error 1
[3] => stress: WARN: [19607] (396) now reaping child worker processes
[4] => stress: FAIL: [19607] (400) kill error: No such process
[5] => stress: FAIL: [19607] (451) failed run completed in 0s
)
初步怀疑,用php调用的stress没有权限创建临时文件,导致大量的stress进程不停地创建退出,从而是CPU使用率增高,因为这些进程很快退出,在top中能看到的stress进程的CPU使用率都很低。
用perf查看15秒内的CPU性能报告
-a查看所有cpu:
perf record -ag -- sleep 15;perf report
perf report中显示,stress进程的cpu事件占比是77%,它大量调用了随机数生成函数random(),确定是它导致CPU使用率高:
小结与execsnoop
倪鹏飞设计的这个案例特别典型,问题根源特别隐蔽,导致CPU使用率高的stress进程很快退出,如果只观察进程的cpu使用率,是找不到问题根源的,需要从task中发现异常, 在用pstree厘清进程关系,从stress的父进程入手,最后用perf report坐实。
排查过程和排查思路才是重点。
另外,有一个名为execsnoop的工具,专门用来监控短时进程,用execsnoop监控的时候,会发现大量的stress进程不停的启动:
# 按 Ctrl+C 结束
$ execsnoop
PCOMM PID PPID RET ARGS
sh 30394 30393 0
stress 30396 30394 0 /usr/local/bin/stress -t 1 -d 1
sh 30398 30393 0
stress 30399 30398 0 /usr/local/bin/stress -t 1 -d 1
sh 30402 30400 0
stress 30403 30402 0 /usr/local/bin/stress -t 1 -d 1
sh 30405 30393 0
stress 30407 30405 0 /usr/local/bin/stress -t 1 -d 1
...
execsnoop安装方法
安装bcc,execsnoop是bcc中的一个工具:
yum install -y bcc
需要注意的是,execsnoop不在*/bin目录中(取决于CentOS版本):
$ ls /usr/share/bcc/tools/execsnoop
/usr/share/bcc/tools/execsnoop
如果遇到下面的错误,说明内核版本太低,不支持ebpf,需要升级到4.1以上,并安装kernel-devel:
[root@prod-k8s-node-138-127 phops]# /usr/share/bcc/tools/execsnoop
In file included from <built-in>:2:
/virtual/include/bcc/bpf.h:13:10: fatal error: 'linux/bpf_common.h' file not found
#include <linux/bpf_common.h>
^~~~~~~~~~~~~~~~~~~~
1 error generated.
Traceback (most recent call last):
File "/usr/share/bcc/tools/execsnoop", line 166, in <module>
b = BPF(text=bpf_text)
File "/usr/lib/python2.7/site-packages/bcc/__init__.py", line 318, in __init__
raise Exception("Failed to compile BPF text")
Exception: Failed to compile BPF text
参考
学校里学不到的Linux系统知识
有非常、非常多的细节是从书本上学不到,这些细节通常分散在各种古朴、难度的文档和手册中。
这些知识在不知道的时候,感觉很简单,知道以后才发现,原来有这么多的细节。
设置本地可用的tcp端口:Linux increase ip_local_port_range TCP port range
How to Enable Disk Quotas on an XFS File System
An Introduction to the ss Command
参考
Kubernetes 使用手册
部分内容来自 kubernetes 工作笔记,本手册随着工作学习的进行不断更新。
用到的 yaml 文件位于 kubernetes-yamls 中:
git clone https://github.com/introclass/kubernetes-yamls
Kubernetes 资料
Kubernetes 社区资料:Community
Kubernetes 博客:Blog
Kubernetes 开发小组:SIGs and Working Groups
Kubernetes 开发规范:Developer Guide
Kubernetes Go 版本:Go Development Environment
Kubernetes 的构建: Building Kubernetes,可以参阅 kubernetes的编译、打包、发布
Kubernetes 的 API:Kubernetes API
历史笔记
参考
Minikube 使用方法(最详细的中文手册)
用 minikube 部署开发测试环境 中记录了 minikube 的使用方法,这里重新整理一下。
手册目录在页面左侧,如果是在手机端查看,点击左上角的 符号。
什么情况下,为什么用 Minikube?
做 Kubernetes 配套开发时,用 minkube 启动一个 kubernetes 集群作为开发测试环境是非常方便的。
Minikube 可以方便地启动不同版本的 kubernetes,美中不足的是,用 minikube 部署的 kubernetes 都是单机模式,如果要做一些集群相关调试,单机的 kubernetes 就不能满足需求了,需要考虑其它的方法。
Minikube 是 kubernetes 的一个子项目(github地址),使用手册比较完善(minikube doc)。
Minikube 在 linux、windows 和 mac 中都可以使用,在 linux 上支持 baremetal 方式,即将 kubernetes 直接部署在当前系统上,在 windows 和 mac 上则是创建一个虚拟机,在虚拟机中部署 kubernetes,虚拟机的创建都是自动的。
参考
安装 Minikube
Minikube 的安装非常简单,可以用 yum、brew 等工具安装,也可以直接从 github 上下载二进制文件:

查看子命令
用 help 命令查看 minkube 支持的子命令:
$ ./minkube help
Minikube is a CLI tool that provisions and manages single-node Kubernetes clusters optimized for development workflows.
Basic Commands:
start Starts a local kubernetes cluster
status Gets the status of a local kubernetes cluster
stop Stops a running local kubernetes cluster
delete Deletes a local kubernetes cluster
dashboard Access the kubernetes dashboard running within the minikube cluster
Images Commands:
docker-env Sets up docker env variables; similar to '$(docker-machine env)'
cache Add or delete an image from the local cache.
Configuration and Management Commands:
addons Modify minikube's kubernetes addons
config Modify minikube config
...(省略)...
安装虚拟化软件
除非在 Linux 上使用 baremetal 的方式,否则需要安装虚拟化软件,使用 virtualbox、vmware 等最常用的虚拟机化软件即可。Minikube 默认虚拟化软件为 virtualbox。
安装 kubectl
要操作部署的 kubernetes,本地还需要有 kubectl 命令,可以到 kubernetes/releases 中下载。

点击 ChangeLog 文件进入下载页面:

参考
用 minikube 启动 kubernetes
Minikube 可以部署多个版本的 kubernetes,如果不指定版本默认使用最新版。
启动默认版本的 kubernetes
$ minkube start
😄 minikube v1.3.1 on Darwin 10.14
🔥 Creating virtualbox VM (CPUs=2, Memory=2000MB, Disk=20000MB) ...
🐳 Preparing Kubernetes v1.15.2 on Docker 18.09.8 ...
▪ scheduler.leader-elect-resource-lock=configmaps
▪ controller-manager.leader-elect-resource-lock=configmaps
🚜 Pulling images ...
🚀 Launching Kubernetes ...
⌛ Waiting for: apiserver proxy
💣 Wait failed: waiting for k8s-app=kube-proxy: timed out waiting for the condition
😿 Sorry that minikube crashed. If this was unexpected, we would love to hear from you:
👉 https://github.com/kubernetes/minikube/issues/new/choose
如果遇到 "Wait failed" 的情况先别急着重试,即使遇到了上面的错误,kubernetes 也可能已经启动成功了:
$ kubectl get cs
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health":"true"}
启动指定版本的 kubernetes
--kubernetes-version 指定要部署的 kubernetes 版本:
$ minikube start --kubernetes-version v1.12.0
😄 minikube v1.3.1 on Darwin 10.14
💡 Tip: Use 'minikube start -p <name>' to create a new cluster, or 'minikube delete' to delete this one.
🔄 Starting existing virtualbox VM for "minikube" ...
虚拟化软件默认为 virtualbox,如果要用其他的虚拟机化,用 --vm-driver 指定。
支持的参数在 minkube help start 中可以看到:
$ ./minkube help start
Starts a local kubernetes cluster
Options:
--apiserver-ips=[]: A set of apiserver IP Addresses which are used in the generated certificate for kubernetes.
This can be used if you want to make the apiserver available from outside the machine
--apiserver-name='minikubeCA': The apiserver name which is used in the generated certificate for kubernetes. This
...省略...
关闭 kubernetes
$ minikube stop
✋ Stopping "minikube" in virtualbox ...
🛑 "minikube" stopped.
删除
$ minikube delete
参考
进入 minikube 虚拟机以及进行其它精细操作
minkube 自带了不少子命令,可以用来查看、修改各种细节。
进入 minikube 虚拟机
./minkube-v1.3.1 ssh
_ _
_ _ ( ) ( )
___ ___ (_) ___ (_)| |/') _ _ | |_ __
/' _ ` _ `\| |/' _ `\| || , < ( ) ( )| '_`\ /'__`\
| ( ) ( ) || || ( ) || || |\`\ | (_) || |_) )( ___/
(_) (_) (_)(_)(_) (_)(_)(_) (_)`\___/'(_,__/'`\____)
$ pwd
/home/docker
参考
Minikube 部署时,修改 kubernetes 的组件参数
minikube 支持修改每个组件的参数,用 --extra-config 中,格式如下:
$ ./minkube-v1.3.1 start --extra-config=scheduler.leader-elect-resource-lock=configmaps --extra-config=controller-manager.leader-elect-resource-lock=configmaps
😄 minikube v1.3.1 on Darwin 10.14
💡 Tip: Use 'minikube start -p <name>' to create a new cluster, or 'minikube delete' to delete this one.
🏃 Using the running virtualbox "minikube" VM ...
⌛ Waiting for the host to be provisioned ...
🐳 Preparing Kubernetes v1.15.2 on Docker 18.09.8 ...
▪ scheduler.leader-elect-resource-lock=configmaps
▪ controller-manager.leader-elect-resource-lock=configmaps
🔄 Relaunching Kubernetes using kubeadm ...
⌛ Waiting for: apiserver proxy etcd scheduler controller dns
🏄 Done! kubectl is now configured to use "minikube"
上面参数的含义是将 scheduler 的参数 LeaderElection.ResourceLock 设置为 configmaps。
支持参数设置的组件:kubelet、apiserver、proxy、controller-manager、etcd、scheduler。
参考
操作用 minikube 启动的 kubernetes
Minikube 在启动 kubernetes 时会设置 ~/.kube/config 文件,在其中增加了访问凭证:
...省略...
users:
- name: minikube
user:
client-certificate: /Users/lijiao/.minikube/client.crt
client-key: /Users/lijiao/.minikube/client.key
...省略...
所以在当前机器上可以用 kubectl 直接操作 kubernetes:
$ kubectl get ns
NAME STATUS AGE
kube-node-lease Active 7d19h
kube-public Active 7d19h
kube-system Active 7d19h
参考
访问 minikube 启动的 kubernetes 中的服务
Kubernetes 在本地虚拟机中运行,如果要访问部署其中的服务,需要通过 node port。
通过 node port 访问
在 kubernetes 中设置了使用 node port 的 service 后,命令 minikube service list 会列出这些服务的本地访问地址:
$ minkube service list
|---------------|-------------------|--------------------------------|
| NAMESPACE | NAME | URL |
|---------------|-------------------|--------------------------------|
| default | kubernetes | No node port |
| demo-echo | echo | http://192.168.99.100:30801 |
| | | http://192.168.99.100:30263 |
| demo-webshell | webshell | No node port |
| demo-webshell | webshell-nodeport | http://192.168.99.100:32635 |
| | | http://192.168.99.100:32454 |
| kube-system | kube-dns | No node port |
|---------------|-------------------|--------------------------------|
参考
Kubernetes 的用户交互 API
用户可以向 kubernetes 提交各种类型的任务和数据,我们把 kubernetes 接受的任务或数据类型称为 API。经过这几年的飞速发展,API 的种类非常丰富。
API 完整列表:api-index。
在 kubernetes 项目中,API 的定义代码位于 staging/src/k8s.io/api,staging/src/k8s.io/api 已经作为独立项目发布,通过 k8s.io/api 引用。
API 的版本与作用域
Resource 是有版本的:
apiVersion: v1
kind: Namespace
...
apiVersion: extensions/v1beta1
kind: DaemonSet
有一些 resource 是 cluster 级别的,不属于任何 namespace,全局有效,后面的 cluster apis。
CLUSTER APIS
APIService v1 apiregistration.k8s.io
AuditSink v1alpha1 auditregistration.k8s.io
Binding v1 core
CertificateSigningRequest v1beta1 certificates.k8s.io
ClusterRoleBinding v1 rbac.authorization.k8s.io
ComponentStatus v1 core
Lease v1 coordination.k8s.io
LocalSubjectAccessReview v1 authorization.k8s.io
Namespace v1 core
Node v1 core
PersistentVolume v1 core
ResourceQuota v1 core
Role v1 rbac.authorization.k8s.io
RoleBinding v1 rbac.authorization.k8s.io
RuntimeClass v1beta1 node.k8s.io
SelfSubjectAccessReview v1 authorization.k8s.io
SelfSubjectRulesReview v1 authorization.k8s.io
ServiceAccount v1 core
SubjectAccessReview v1 authorization.k8s.io
TokenRequest v1 authentication.k8s.io
TokenReview v1 authentication.k8s.io
NetworkPolicy v1 networking.k8s.io
WORKLOADS APIS
Container v1 core
CronJob v1beta1 batch
DaemonSet v1 apps
Deployment v1 apps
Job v1 batch
Pod v1 core
ReplicaSet v1 apps
ReplicationController v1 core
StatefulSet v1 apps
SERVICE APIS
Endpoints v1 core
EndpointSlice v1alpha1 discovery.k8s.io
Ingress v1beta1 networking.k8s.io
Service v1 core
CONFIG AND STORAGE APIS
ConfigMap v1 core
CSIDriver v1beta1 storage.k8s.io
CSINode v1beta1 storage.k8s.io
Secret v1 core
PersistentVolumeClaim v1 core
StorageClass v1 storage.k8s.io
Volume v1 core
VolumeAttachment v1 storage.k8s.io
METADATA APIS
ControllerRevision v1 apps
CustomResourceDefinition v1 apiextensions.k8s.io
Event v1 core
LimitRange v1 core
HorizontalPodAutoscaler v1 autoscaling
MutatingWebhookConfiguration v1 admissionregistration.k8s.io
ValidatingWebhookConfiguration v1 admissionregistration.k8s.io
PodTemplate v1 core
PodDisruptionBudget v1beta1 policy
PriorityClass v1 scheduling.k8s.io
PodPreset v1alpha1 settings.k8s.io
PodSecurityPolicy v1beta1 policy
参考
Kubernetes 源代码阅读指引
独立发布的代码
kubernetes/staging/ 位于 kubernetes 项目中,但是其中的代码发布到独立的 repo:
api 定义代码
api 定义代码位于 kubernetes/staging/src/k8s.io/api。
需要注意 kubernetes 主项目中还有三个名为 api/apis 的目录:
kubernetes/api: 不符合规范、但是还没去处的 api 列表
kuberntes/pkg/api: 简单的操作函数
kuberntes/pkg/apis: deepcopy、版本转换等工具代码
参考
Kubernetes 导入外部服务
本文使用的 yaml 文件:
git clone https://github.com/introclass/kubernetes-yamls
cd kubernetes-yamls/ingress-nginx/05-1-external-svc
启动一个外部服务
启动一个位于集群外部的服务:
./start-github-oauth2-proxy.sh
这里的服务地址为 192.168.99.1:4180,将这个服务导入到 kubernetes 中。
导入到 kubernetes 中
为外部服务创建 Service 和一个与 Service 同名的 endpoint,endpoint 中填入外部服务的 IP。
名为 external-github-oauth-proxy 的 Service:
kind: Service
apiVersion: v1
metadata:
name: external-github-oauth-proxy
spec:
type: ClusterIP
ports:
- port: 4180
targetPort: 4180
同名的 endpoint:
kind: Endpoints
apiVersion: v1
metadata:
name: external-github-oauth-proxy
subsets:
- addresses:
- ip: 192.168.99.1
ports:
- port: 4180
创建:
$ kubectl -n demo-echo create -f external-github-oauth2-proxy.yaml
导入效果
导入后可以像使用其它服务一样使用外部服务,譬如在 ingress 中配置外部服务:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: github-oauth2-proxy
spec:
rules:
- host: github-oauth2.example
http:
paths:
- backend:
serviceName: github-oauth2-proxy
servicePort: 4180
path: /
创建:
$ kubectl -n demo-echo create github-oauth-proxy.yaml
参考
Kubernetes 的 Pod 操作技巧
Pod 的信息以环境变量的方式注入容器
参考 Expose Pod Information to Containers Through Environment Variables。
env:
- name: PODIP
valueFrom:
fieldRef:
fieldPath: status.podIP
在 Pod 内用 ServcieAccount 访问 APIServer
KUBE_TOKEN=$(cat /var/run/secrets/kubernetes.io/serviceaccount/token)
curl -sSk -H "Authorization: Bearer $KUBE_TOKEN" https://kubernetes.default.svc/api/v1/nodes/172.29.128.12/proxy/metrics/cadvisor
参考
ingress-nginx 的使用方法
ingress-nginx 是 NGINX Ingress Controller for Kubernetes,它能做的事情越来越多,NGINX Ingress Controller Examples 列出了 ingress-nginx 能做的事情。
获取后面要使用的 yaml 文件:
$ git clone https://github.com/introclass/kubernetes-yamls
$ cd kubernetes-yamls/ingress-nginx
$ ls
01-tls 05-1-external-svc 08-ratelimit
02-auth-basic 05-2-auth-oauth-ext ingress-nginx-0.25.1.yaml
03-auth-cert 06-rewrite
04-auth-basic-ext 07-mirror
试验环境
Kubernetes 是用 minikube 部署的单机版,见 Minikube 使用手册,版本如下:
$ kubectl version
Client Version: version.Info{Major:"1", Minor:"15", GitVersion:"v1.15.3", GitCommit:"2d3c76f9091b6bec110a5e63777c332469e0cba2", GitTreeState:"clean", BuildDate:"2019-08-19T12:36:28Z", GoVersion:"go1.12.9", Compiler:"gc", Platform:"darwin/amd64"}
Server Version: version.Info{Major:"1", Minor:"15", GitVersion:"v1.15.2", GitCommit:"f6278300bebbb750328ac16ee6dd3aa7d3549568", GitTreeState:"clean", BuildDate:"2019-08-05T09:15:22Z", GoVersion:"go1.12.5", Compiler:"gc", Platform:"linux/amd64"}
安装 ingress-nginx
创建 namespace、configmap,设置 role,部署 deployment(deployment 用到镜像要翻 Q 获取):
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/nginx-0.25.1/deploy/static/mandatory.yaml
如果不能翻Q,用下面的 yaml:
$ kubectl apply -f https://raw.githubusercontent.com/introclass/kubernetes-yamls/master/ingress-nginx/ingress-nginx-0.25.1.yaml
以 nodeport 的方式暴露 ingress-nginx:
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/nginx-0.25.1/deploy/static/provider/baremetal/service-nodeport.yaml
30933 端口是 http 的映射端口,30358 是 https 协议的映射端口:
$ kubectl -n ingress-nginx get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx NodePort 10.106.78.115 <none> 80:30933/TCP,443:30358/TCP 5d4h
部署目标服务
部署目标服务 echo,echo 服务的用途见 用 echoserver 观察代理/转发效果,通过 ingress-nginx 访问该目标服务:
$ kubectl apply -f https://raw.githubusercontent.com/introclass/kubernetes-yamls/master/all-in-one/echo-all-in-one.yaml
在名为 demo-echo 的 namespace 中创建了 echo 服务,以 nodeport 方式暴露 echo 服务:
$ kubectl -n demo-echo get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
echo NodePort 10.111.29.87 <none> 80:30411/TCP,22:31867/TCP 42d app=echo
同时通过 ingress 暴露 echo 服务(用于和 ingress 代理返回的结果对比):
$ kubectl -n demo-echo get ingress
NAME HOSTS ADDRESS PORTS AGE
ingress-echo echo.example 80 42d
验证环境
通过 nodeport 访问 echo 服务:
$ curl http://192.168.99.100:30411
Hostname: echo-597d89dcd9-4dp6f
Pod Information:
-no pod information available-
Server values:
server_version=nginx: 1.13.3 - lua: 10008
...
通过 ingress-nginx 访问 echo 服务:
$ curl http://192.168.99.100:30933 -H "Host: echo.example"
Hostname: echo-597d89dcd9-4dp6f
Pod Information:
-no pod information available-
Server values:
server_version=nginx: 1.13.3 - lua: 10008
Request Information:
client_address=172.17.0.18
method=GET
real path=/
query=
request_version=1.1
request_uri=http://echo.example:8080/
...
参考
ingress-nginx 设置 https 证书
ingress-nginx 设置 https 证书的方式特别简单,将目标服务的 tls 证书以 secret 的方式存放到 kubernetes 后,在对应的 ingress 的 tls 设置中引用证书即可。
$ cd 01-tls
准备证书
目标服务的正式证书要通过 CA 机构签署,试验该功能时可以先用自签署的证书:
echo "生成自签署的 ca 证书"
openssl req -x509 -sha256 -newkey rsa:4096 -keyout ca.key -out ca.crt -days 3560 -nodes -subj '/CN=My Cert Authority'
echo "生成用上述 ca 签署的 server 证书"
openssl req -new -newkey rsa:4096 -keyout server.key -out server.csr -nodes -subj '/CN=tls.echo.example'
openssl x509 -req -sha256 -days 3650 -in server.csr -CA ca.crt -CAkey ca.key -set_serial 01 -out server.crt
上面的 CN= 是目标服务要使用的域名。
生成证书:
./01-create-cert.sh
将 server 证书上传到 kubernetes,(如果只是启用 tls 加密, ca 证书不需要上传):
$ kubectl -n demo-echo create secret generic tls-echo-exmaple-secret --from-file=tls.crt=server.crt --from-file=tls.key=server.key
配置 ingress
ignress 中的 host 一定要与证书的 CN 相同,在 tls 配置中引用前面创建的 secret:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-echo-with-tls
spec:
rules:
- host: tls.echo.example
http:
paths:
- path: /
backend:
serviceName: echo
servicePort: 80
tls:
- hosts:
- tls.echo.example
secretName: tls-echo-exmaple-secret
创建:
$ kubectl -n demo-echo create -f tls-echo-example-ingress.yaml
效果
这里的 ingress-nginx 的 IP 地址是 192.168.99.100,https 端口是 30358,在本地配置 hosts 后访问:
# /etc/hosts
192.168.99.100 tls.echo.example
因为是自签署的证书,浏览器会提示证书不可信,使用 CA 机构签署证书不会有这个问题:

支持多个域名
可以在一个 ingress 中为多个域名设置 tls 加密,例如:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: foo-tls
namespace: default
spec:
tls:
- hosts:
- foo.bar.com
# This secret must exist beforehand
# The cert must also contain the subj-name foo.bar.com
# https://github.com/kubernetes/ingress-nginx/blob/master/docs/examples/PREREQUISITES.md#tls-certificates
secretName: foobar
- hosts:
- bar.baz.com
# This secret must exist beforehand
# The cert must also contain the subj-name bar.baz.com
# https://github.com/kubernetes/ingress-nginx/blob/master/docs/examples/PREREQUISITES.md#tls-certificates
secretName: barbaz
rules:
- host: foo.bar.com
http:
paths:
- backend:
serviceName: http-svc
servicePort: 80
path: /
- host: bar.baz.com
http:
paths:
- backend:
serviceName: nginx
servicePort: 80
path: /
参考
ingress-nginx 的认证功能使用示例
Basic Authentication (HTTP 认证)
Basic Authentication 是最简单的 http 认证方式,采用用户名和密码的方式,用户名和密码以 secret 的方式存放在 kubernetes 中。
cd 02-auth-basic
创建用户,设置密码
用下面的三个操作,创建 basic-auth 用户 foo,密码 123456,将用户信息提交到 kubernetes:
$ htpasswd -c auth foo
$ kubectl -n demo-echo create secret generic basic-auth --from-file=auth
secret 与目标服务 echo 在同一个 namespace 中。
执行效果如下:
$ ./01-create-user.sh
New password: 123456
Re-type new password: 123456
Adding password for user foo
...
为目标服务设置 ingress
为目标服务创建一个启用了 basic-auth 的 ingress:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-echo-with-auth-basic
annotations:
# type of authentication
nginx.ingress.kubernetes.io/auth-type: basic
# name of the secret that contains the user/password definitions
nginx.ingress.kubernetes.io/auth-secret: basic-auth
# message to display with an appropriate context why the authentication is required
nginx.ingress.kubernetes.io/auth-realm: 'Authentication Required - foo'
spec:
rules:
- host: auth-basic.echo.example
http:
paths:
- path: /
backend:
serviceName: echo
servicePort: 80
执行:
$ kubectl -n demo-echo apply -f auth-basic-ingress.yaml
$ kubectl -n demo-echo get ingress
NAME HOSTS ADDRESS PORTS AGE
ingress-echo echo.example 80 42d
ingress-echo-with-auth-basic auth-basic.echo.example 80 6s
使用效果
通过开启了认证功能的 ingress 访问,不带用户名和密码时,返回 401:
$ curl -H "Host: auth-basic.echo.example" 192.168.99.100:30933
<html>
<head><title>401 Authorization Required</title></head>
<body>
<center><h1>401 Authorization Required</h1></center>
<hr><center>openresty/1.15.8.1</center>
</body>
</html>
用户名或密码错误时:
$ curl -H "Host: auth-basic.echo.example" 192.168.99.100:30933 -u 'foo:bar'
<html>
<head><title>401 Authorization Required</title></head>
<body>
<center><h1>401 Authorization Required</h1></center>
<hr><center>openresty/1.15.8.1</center>
</body>
用户名和密码正确时:
$ curl -H "Host: auth-basic.echo.example" 192.168.99.100:30933 -u 'foo:123456'
Hostname: echo-597d89dcd9-4dp6f
Pod Information:
-no pod information available-
Server values:
server_version=nginx: 1.13.3 - lua: 10008
Client Certificate Authentication(客户端证书认证)
Client Certificate Authentication,进行客户端证书认证需要提供 客户端证书 、 服务端证书 和能够验证客户端证书的 ca 证书。启用客户端证书必须使用 tls 加密,所以服务端证书是必须的。
操作过程中,遇到了两个低级错误引发的问题,供参考:
cd 03-auth-cert
生成证书
用下面的命令生成证书:
echo "生成自签署的 ca 证书"
openssl req -x509 -sha256 -newkey rsa:4096 -keyout ca.key -out ca.crt -days 3560 -nodes -subj '/CN=My Cert Authority'
echo "生成用上述 ca 签署的 server 证书"
openssl req -new -newkey rsa:4096 -keyout server.key -out server.csr -nodes -subj '/CN=auth-cert.echo.example'
openssl x509 -req -sha256 -days 3650 -in server.csr -CA ca.crt -CAkey ca.key -set_serial 01 -out server.crt
echo "生成用上述 ca 签署的 client 证书"
openssl req -new -newkey rsa:4096 -keyout client.key -out client.csr -nodes -subj '/CN=My Client'
openssl x509 -req -sha256 -days 3650 -in client.csr -CA ca.crt -CAkey ca.key -set_serial 02 -out client.crt
执行:
$ ./01-create-cert.sh
生成下面的文件:
client.crt server.crt
ca.crt client.csr server.csr
ca.key client.key server.key
上传证书
将 ca 证书和服务端证书上传到目标服务 echo 所在的 namespace:
$ kubectl -n demo-echo create secret generic ca-secret --from-file=ca.crt=ca.crt
$ kubectl -n demo-echo create secret generic tls-secret --from-file=tls.crt=server.crt --from-file=tls.key=server.key
创建对应的 ingress
创建配置了 tls 认证的 ingress,auth-tls-secret 是服务端验证客户端证书时使用的证书:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-echo-with-auth-cert
annotations:
# Enable client certificate authentication
nginx.ingress.kubernetes.io/auth-tls-verify-client: "on"
# Create the secret containing the trusted ca certificates
nginx.ingress.kubernetes.io/auth-tls-secret: "demo-echo/ca-secret"
# Specify the verification depth in the client certificates chain
nginx.ingress.kubernetes.io/auth-tls-verify-depth: "1"
# Specify an error page to be redirected to verification errors
nginx.ingress.kubernetes.io/auth-tls-error-page: "http://auth-cert.echo.example/error-cert.html"
# Specify if certificates are passed to upstream server
nginx.ingress.kubernetes.io/auth-tls-pass-certificate-to-upstream: "true"
spec:
rules:
- host: auth-cert.echo.example
http:
paths:
- path: /
backend:
serviceName: echo
servicePort: 80
tls:
- hosts:
- auth-cert.echo.example
secretName: tls-secret
执行:
$ kubectl -n demo-echo apply -f auth-cert-ingress.yaml
$ kubectl -n demo-echo get ingress
NAME HOSTS ADDRESS PORTS AGE
ingress-echo echo.example 80 42d
ingress-echo-with-auth-basic auth-basic.echo.example 80 3s
ingress-echo-with-auth-cert auth-cert.echo.example 80 81s
使用效果
使用 http 协议访问时,308 跳转到 https 网址:
$ curl -v -H "Host: auth-cert.echo.example" 192.168.99.100:30933
* Rebuilt URL to: 192.168.99.100:30933/
* Trying 192.168.99.100...
* TCP_NODELAY set
* Connected to 192.168.99.100 (192.168.99.100) port 30933 (#0)
> GET / HTTP/1.1
> Host: auth-cert.echo.example
> User-Agent: curl/7.54.0
> Accept: */*
>
< HTTP/1.1 308 Permanent Redirect
< Server: openresty/1.15.8.1
< Date: Fri, 11 Oct 2019 11:34:57 GMT
< Content-Type: text/html
< Content-Length: 177
< Connection: keep-alive
< Location: https://auth-cert.echo.example/
使用 https 协议访问(使用 https 时必须使用域名),客户端没有使用证书时,被重定向:
$ curl --cacert ca.crt https://auth-cert.echo.example:30358/
...
< HTTP/2 302
< server: openresty/1.15.8.1
< date: Sat, 12 Oct 2019 06:44:11 GMT
< content-type: text/html
< content-length: 151
< location: http://auth-cert.echo.example/error-cert.html
<
...
<html>
<head><title>302 Found</title></head>
<body>
<center><h1>302 Found</h1></center>
<hr><center>openresty/1.15.8.1</center>
</body>
</html>
重定向地址在 annotation 中设置:
nginx.ingress.kubernetes.io/auth-tls-error-page: "http://auth-cert.echo.example/error-cert.html"
使用客户端证书认证:
$ curl --cacert ca.crt --cert client.crt --key client.key https://auth-cert.echo.example:30358/
Hostname: echo-597d89dcd9-4dp6f
Pod Information:
-no pod information available-
Server values:
server_version=nginx: 1.13.3 - lua: 10008
...
参考
- 李佶澳的博客
- Basic Authentication
- Client Certificate Authentication
- CONNECT_CR_SRVR_HELLO:wrong version number
- unable to get local issuer certificate
ingress-nginx 对接外部的认证服务
ingress-nginx 自带认证功能,也支持对接外部的认证服务。
对接外部的 Basic Auth
cd 04-auth-basic-ext/
准备外部 basic auth 服务
准备一个外部的 Basic Auth,https://httpbin.org/ 是一个很好的选择。
httbin.org 有一个接口 https://httpbin.org/basic-auth/{user}/{passwd},这是一个认证地址,用户名就是 url 中的 user,密码就是 passwd,如下:
$ curl -u user1:passwd1 https://httpbin.org/basic-auth/user1/passwd1
{
"authenticated": true,
"user": "user1"
}
创建使用外部认证的 ingress
auth-url 是外部认证地址:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-echo-with-auth-basic-ext
annotations:
nginx.ingress.kubernetes.io/auth-url: "https://httpbin.org/basic-auth/user1/passwd1"
spec:
rules:
- host: auth-basic-ext.echo.example
http:
paths:
- path: /
backend:
serviceName: echo
servicePort: 80
执行:
$ kubectl -n demo-echo create -f auth-basic-ext-ingress.yaml
$ kubectl -n demo-echo get ingress -o wide
NAME HOSTS ADDRESS PORTS AGE
ingress-echo echo.example 80 45d
ingress-echo-with-auth-basic auth-basic.echo.example 80 2d20h
ingress-echo-with-auth-basic-ext auth-basic-ext.echo.example 80 21s
ingress-echo-with-auth-cert auth-cert.echo.example 80, 443 2d1h
使用效果
不提供用户名和密码:
$ curl -H "Host: auth-basic-ext.echo.example" 192.168.99.100:30933
<html>
<head><title>401 Authorization Required</title></head>
<body>
<center><h1>401 Authorization Required</h1></center>
<hr><center>openresty/1.15.8.1</center>
</body>
</html>
提供错误的用户名或密码:
$ curl -u user:nopass -H "Host: auth-basic-ext.echo.example" 192.168.99.100:30933
<html>
<head><title>401 Authorization Required</title></head>
<body>
<center><h1>401 Authorization Required</h1></center>
<hr><center>openresty/1.15.8.1</center>
</body>
</html>
提供正确的用户名和密码:
$ curl -u user1:passwd1 -H "Host: auth-basic-ext.echo.example" 192.168.99.100:30933
Hostname: echo-597d89dcd9-4dp6f
Pod Information:
-no pod information available-
对接外部的 OAuth2 服务
OAuth2 服务的地址同样在 annotation 中设置,为了避免额外的折腾,这里全部使用 https,否则需要调整 lijiaocn/oauth2_proxy:v4.0.0 的启动参数。
cd 05-2-auth-oauth-ext
准备外部 OAuth2 服务
Github 支持 OAuth2 认证,通过地址 https://github.com/settings/applications/new 注册使用 github OAuth2 的应用:

创建之后获得 Client ID 和 Client Secret:

启动容器 github_oauth2_proxy,该容器用于代理到 github 的 OAuth2 认证,用 github 分配的 client id 和 client secret 启动:
$ ./github-oauth-proxy.sh
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b9fc2924b9eb lijiaocn/oauth2_proxy:v4.0.0 "/bin/oauth2_proxy -…" 5 seconds ago Up 4 seconds 0.0.0.0:4180->4180/tcp github_oauth2_proxy
这里的 github_oauth2_proxy 服务地址为 192.168.99.1:4180,需要确保两件事:
- 能够用浏览器打开这个地址;
- ingress-nginx 容器能够访问该地址:

如果当前没有登录 github,点击 Sign in with Github 会弹出 github 登录页面。 现在还没有配置 auth-oauth2-ext.echo.example 的 ingress,登录后的回调页面打不开,且会报 url 不一致的 OAuth2 认证错误。
github_oauth2_proxy 位于 kubernetes 外部, 按照 Kubernetes 导入外部服务 的做法导入:
$ kubectl -n demo-echo apply -f external-github-oauth2-proxy.yaml
配置目标应用的 Ingress
为目标应用创建 tls 证书,保存在名为 oauth2-tls-secret 的 secret 中:
echo "生成自签署的 ca 证书"
openssl req -x509 -sha256 -newkey rsa:4096 -keyout ca.key -out ca.crt -days 3560 -nodes -subj '/CN=My Cert Authority'
echo "生成用上述 ca 签署的 server 证书"
openssl req -new -newkey rsa:4096 -keyout server.key -out server.csr -nodes -subj '/CN=auth-oauth2-ext.echo.example'
openssl x509 -req -sha256 -days 3650 -in server.csr -CA ca.crt -CAkey ca.key -set_serial 01 -out server.crt
执行:
$ ./01-create-cert.sh
$ kubectl -n demo-echo create secret generic oauth2-tls-secret --from-file=tls.crt=server.crt --from-file=tls.key=server.key
为目标应用创建 ingress:
- 需要创建两个 ingress,一个指向目标应用,一个指向 github_oauth2_proxy;
- 两个 ingress 使用同样的 host,注意, 必须是两个 ingress ;
- 指向 github_oauth2_proxy 的ingress 的 path 、在 github 中注册的 callback 地址、指向目标应用的 ingress 中的 auth-signin ,三者要一致。
下面是指向目标应用的 ingress,auth-url 是 oauth 认证地址,auth-signin 是未认证或认证失败时的重定向地址,重定向地址是指向 github_oauth2_proxy 的 ingress 的 path:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-echo-with-auth-oauth2-ext
annotations:
# 如果 ingress-nginx 容器能够访问 auth-oauth2-ext.echo.example,写域名也可以,见后面的原理说明
nginx.ingress.kubernetes.io/auth-url: "http://192.168.99.1:4180/oauth2/auth"
nginx.ingress.kubernetes.io/auth-signin: "https://auth-oauth2-ext.echo.example:30358/oauth2/start?rd=$escaped_request_uri"
spec:
rules:
- host: auth-oauth2-ext.echo.example
http:
paths:
- path: /
backend:
serviceName: echo
servicePort: 80
tls:
- hosts:
- auth-oauth2-ext.echo.example
secretName: secret/oauth2-tls-secret
下面是指向 github_oauth2_proxy 的 ingress ,需要和上面的 ingress 使用同一个域名,否则会因为 url 不匹配而认证失败,上面的 ingress 中的 auth-signin 指定的 path 在这里配置( /oauth2 ):
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-echo-with-auth-oauth2-ext-proxy
spec:
rules:
- host: auth-oauth2-ext.echo.example
http:
paths:
- path: /oauth2
backend:
serviceName: external-github-oauth-proxy
servicePort: 4180
tls:
- hosts:
- auth-oauth2-ext.echo.example
secretName: secret/oauth2-tls-secret
创建:
$ kubectl -n demo-echo create -f auth-oauth2-ext-ingress.yaml
使用效果
访问 https://auth-oauth2-ext.echo.example:30358 时,弹出 github 登录界面(未登录的时候):

登录 github 后,客户端会被设置一个名 _oauth2_proxy 的 cookie,后续访问不需要登录 github:

原理说明
访问目标应用时候,ingress-nginx 容器会向 auth-url 发起认证,该认证由 ingress-nginx 容器发起,所以 ingress-nginx 容器必须能够访问 auth-url。
如果认证没有通过,ingress-nginx 容器将客户端重定向到 auth-signin。auth-signin 是目标应用的 oauth2 登录页面,这里是用 github_oauth2_proxy 容器实现的。 auth-signin 地址是客户端要访问的,ingress-nginx 容器能否访问没有影响。
客户端被重定向到 oauth2 登录页面后,点击登录,进入 github 的登录页面。
用户登录 github 后,github 再将客户端重定向到在 github 中配置的回调地址(即 github_oauth2_proxy 的 path),该回调地址由客户端访问,github 能否访问没有影响:

客户端访问回调地址后,github_oauth2_proxy 在客户端设置 cookie,并将客户端重定向到最初的访问地址。
带有 cookie 的客户端再次访问目标应用时,通过了 auth-url 的认证,访问到目标服务。
参考
Ingress-nginx 的 uri 改写功能(rewrite)
ingress-nginx 支持 uri 改写,并且支持正则捕获。
cd 06-rewrite
配置目标应用的 ingress
创建一个 ingress,path 匹配规则为 /rewrite/(.*),rewrite-target 中可以使用 path 中的正则匹配:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-echo-with-rewrite
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /$1
spec:
rules:
- host: rewrite.echo.example
http:
paths:
- path: /rewrite/(.*)
backend:
serviceName: echo
servicePort: 80
需要注意 rewrite-target 对 ingress 中的所有 path 有效。
创建:
$ kubectl -n demo-echo create -f rewrite-echo-example-ingress.yaml
效果
访问 /rewrite/abc,服务端看到的是改写后的 /abc:
$ curl -H "Host: rewrite.echo.example" 192.168.99.100:30933/rewrite/abc
Hostname: echo-597d89dcd9-4dp6f
Pod Information:
-no pod information available-
Server values:
server_version=nginx: 1.13.3 - lua: 10008
Request Information:
client_address=172.17.0.11
method=GET
real path=/abc #<--改写后的 path
query=
参考
ingress-nginx 的请求复制功能
ingress-nginx 支持请求复制功能,将同一域名下指定 path 上的请求复制到另一个 path。
cd 07-mirror
部署接收复制请求的服务
创建一个名为 http-record 的服务,用来接收复制的请求:
$ kubectl -n demo-echo apply -f http-record.yaml
namespace/demo-echo unchanged
service/http-record created
deployment.apps/http-record created
$ kubectl -n demo-echo get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
echo NodePort 10.111.29.87 <none> 80:30411/TCP,22:31867/TCP 47d
http-record NodePort 10.106.66.216 <none> 80:31734/TCP,22:32324/TCP 29s
配置被复制的服务的 ingress
需要创建两个 ingress,两个 ingress 使用相同的 host。
第一个 ingress 用来接收复制的请求,指向 http-record 服务:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-echo-with-mirror-backend
spec:
rules:
- host: mirror.echo.example
http:
paths:
- path: /echo
backend:
serviceName: http-record
servicePort: 80
第二个 ingress 配置要被复制的请求,指向目标服务。mirror-uri 接收复制的请求的地址,对 ingress 中所有 path 有效:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-echo-with-mirror
annotations:
nginx.ingress.kubernetes.io/mirror-uri: "/echo"
spec:
rules:
- host: mirror.echo.example
http:
paths:
- path: /
backend:
serviceName: echo
servicePort: 80
默认将请求的 body 一同复制,如果不想复制 body,在第二个 ingress 中用下面的注解关闭:
nginx.ingress.kubernetes.io/mirror-request-body: "off"
请求复制效果
发起请求:
$ curl -X POST -d "111111" -H "Host: mirror.echo.example" "192.168.99.100:30933/aaaaaa/bbbb?c=a"
Hostname: echo-597d89dcd9-m84tq
Pod Information:
-no pod information available-
...
上面的请求将被复制一份到 http-record 容器,http-record 容器的回应被 ingress 忽略,在 http-record 的日志中可以看到复制来的请求:
$ kubectl -n demo-echo logs -f http-record-66478bdbb7-xslzg
http-record 容器收到的请求信息,注意原始的 uri 使用 header 传递的 —— X-Original-Uri:
{
"RemoteAddr": "172.17.0.11:59784",
"Method": "POST",
"Host": "mirror.echo.example",
"RequestURI": "/echo?c=a",
"Header": {
"Accept": [
"*/*"
],
"Content-Length": [
"6"
],
"Content-Type": [
"application/x-www-form-urlencoded"
],
"User-Agent": [
"curl/7.54.0"
],
"X-Forwarded-For": [
"172.17.0.1"
],
"X-Forwarded-Host": [
"mirror.echo.example"
],
"X-Forwarded-Port": [
"80"
],
"X-Forwarded-Proto": [
"http"
],
"X-Original-Uri": [
"/aaaaaa/bbbb?c=a"
],
"X-Real-Ip": [
"172.17.0.1"
],
"X-Request-Id": [
"86e25adfcd7f2a673925d9a17769272a"
],
"X-Scheme": [
"http"
]
},
"Body": "1111"
复制原始的 uri
上面的复制效果,复制后的请求的 uri 为 /echo,不是原始的 uri。在下面的文章中探讨了这个问题:
现在发现了一个更好的解决方法,直接在接收复制流量的 ingress 中加一个 rewrite 就可以了,如下:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
annotations:
# 使用原始的 uri
nginx.ingress.kubernetes.io/rewrite-target: $request_uri
name: ingress-echo-with-mirror-backend
spec:
rules:
- host: mirror.echo.example
http:
paths:
- path: /echo
backend:
serviceName: http-record
servicePort: 80
这时候访问:
$ curl -H "Host: mirror.echo.example" "192.168.99.100:30933/dddd?a=1&b=2"
复制端看到的请求的 uri 是 dddd?a=1&b=2 :
{
"RemoteAddr": "172.17.0.27:39254",
"Method": "GET",
"Host": "mirror.echo.example",
"RequestURI": "/dddd%3Fa=1\u0026b=2?a=1\u0026b=2",
...省略...
}
补充:另一种实现方法,可以按比例复制
阿里云提供的一种实现方法,详情见 通过K8S Ingress Controller来实现应用的流量复制。
在 ingress-nginx 使用的 configmap nginx-configuration 中添加配置,通过 http-snippet 添加全局配置,设置复制的流量的去处。流量的去处可以是 IP 地址或者域名,下面将使用 http-record 服务的 cluster ip:
$ kubectl -n demo-echo get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
echo NodePort 10.100.105.128 <none> 80:32110/TCP,22:32561/TCP 33d
http-record NodePort 10.106.66.216 <none> 80:31734/TCP,22:32324/TCP 29d
在 configmap nginx-configuration 中添加的配置,这个配置是全局的,会被注入到 nginx.conf:
http-snippet: |
split_clients "$date_gmt" $mirror_echo_to_http_record {
50% 10.106.66.216; # 可以是域名、IP,100% 是复制比例
* "";
}
split_clients 指令的用途见 nginx 的 A/B 测试功能,这个指令的强大之处是可以按 hash 值的分布区间设置变量值。hash 算法的输入字符串自行指定,这里是 $date_gmt,使用源IP、request_uri 等 nginx 支持的变量都是可以的。
在需要被复制的 ingress 中用 configuration-snippet 和 server-snippet 注入配置,这些配置会 原封不动 的合并到最终的 nginx.conf 中, 不要有错误:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-echo-with-mirror2
annotations:
nginx.ingress.kubernetes.io/configuration-snippet: |
mirror /mirror334556; # 配置多次该项则可放大N倍流量
nginx.ingress.kubernetes.io/server-snippet: |
location = /mirror334556 {
internal;
access_log off; # 关闭mirror请求日志
if ($mirror_echo_to_http_record) {
set $proxy_host $host; # 是否更改 host
#set $proxy_host $mirror_echo_to_http_record; # 是否更改 host
proxy_pass http://$mirror_echo_to_http_record$request_uri;
}
}
spec:
rules:
- host: mirror2.echo.example
http:
paths:
- path: /
backend:
serviceName: echo
servicePort: 80
注意 $mirror_echo_to_http_record 要和 configmap nginx-configuration 中配置的配对,mirror 指定的 /mirror334556 和同名的 location 对应。
访问 mirror2.echo.example,会看到请求被复制到 http-record:
$ curl -H "Host: mirror2.echo.example" 192.168.99.100:30933/1234
Hostname: echo-597d89dcd9-m84tq
Pod Information:
-no pod information available-
http-record 收到的复制请求:
/go/src/Server/echo.go:46: {
"RemoteAddr": "10.0.2.15:39222",
"Method": "GET",
"Host": "mirror2.echo.example",
"RequestURI": "/1234",
"Header": {
"Accept": [
"*/*"
],
"Connection": [
"close"
],
"User-Agent": [
"curl/7.54.0"
]
},
"Body": ""
}
这种方法相比第一种方式,功能更强大,是一种更巧妙更简洁的做法,工作原理:
如果不要求按比例复制,实现方式更简单:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-echo-with-mirror3
annotations:
nginx.ingress.kubernetes.io/configuration-snippet: |
mirror /mirror334556; # 配置多次该项则可放大N倍流量
nginx.ingress.kubernetes.io/server-snippet: |
location = /mirror334556 {
internal;
#access_log off; # 关闭mirror请求日志
set $target 10.106.66.216;
set $proxy_host $target; # 是否更改 host
#set $proxy_host $host; # 是否更改 host
proxy_pass http://$target$request_uri;
}
spec:
rules:
- host: mirror3.echo.example
http:
paths:
- path: /
backend:
serviceName: echo
servicePort: 80
参考
- 李佶澳的博客
- mirror
- kubernetes ingress-nginx http 请求复制功能与 nginx mirror 的行为差异
- 通过K8S Ingress Controller来实现应用的流量复制
ingress-nginx 针对源 IP 限速
ingress-nginx 可以限制源 IP 的最大连接数、每秒请求数、每分钟请求数、每秒发送的数据量、限速白名单。超过上限的客户端会收到 ingress-nginx 返回的 503。
cd 08-ratelimit
配置 ingress
优先级: limit-connections > limit-rpm > limit-rps。
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-echo-with-ratelimit
annotations:
# 每个源 IP 可以建立最大连接数
nginx.ingress.kubernetes.io/limit-connections: 2
# 每个源 IP 每分钟最大请求次数
nginx.ingress.kubernetes.io/limit-rpm: "5"
# 每个源 IP 每秒最大请求次数
nginx.ingress.kubernetes.io/limit-rps: "1"
spec:
rules:
- host: ratelimit.echo.example
http:
paths:
- path: /
backend:
serviceName: echo
servicePort: 80
执行:
$ kubectl -n demo-echo apply -f ratelimit-echo-example-ingress.yaml
限速效果
连续访问超速后,ingress-nginx 返回 503:
$ curl -v -H "Host: ratelimit.echo.example" "192.168.99.100:30933/"
* Trying 192.168.99.100...
* TCP_NODELAY set
* Connected to 192.168.99.100 (192.168.99.100) port 30933 (#0)
> GET / HTTP/1.1
> Host: ratelimit.echo.example
> User-Agent: curl/7.54.0
> Accept: */*
>
< HTTP/1.1 503 Service Temporarily Unavailable
< Server: openresty/1.15.8.1
< Date: Wed, 16 Oct 2019 10:37:41 GMT
< Content-Type: text/html
< Content-Length: 203
< Connection: keep-alive
其它相关配置
Configmap 中还有其他相关配置,例如超速时的返回代码:limit-req-status-code。
细节研究
参考
ingress-nginx 的金丝雀(canary)发布功能
之前有过一篇笔记(kubernetes ingress-nginx 的金丝雀(canary)/灰度发布功能的使用方法),这里重新整理下。什么是金丝雀、什么是蓝绿、什么是灰度,见 蓝绿部署、金丝雀发布(灰度发布)、A/B测试的准确定义。
原有的 ingress 不需要改变
使用 canary 功能时,主版本 ingress 保持原状,不需要任何改动。
这里使用下面 ingress 作为主版本 ingress:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-echo-with-canary-master
spec:
rules:
- host: canary.echo.example
http:
paths:
- path: /
backend:
serviceName: echo
servicePort: 80
执行:
kubectl -n demo-echo create -f canary-master-echo-example-ingress.yaml
创建 canary (金丝雀)ingress
金丝雀 ingress 和主 ingress 使用相同的 host 和 path,区别在于多出了一些 annotation:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-echo-with-canary-version
annotations:
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-by-header: "version"
nginx.ingress.kubernetes.io/canary-by-header-value: "canary"
nginx.ingress.kubernetes.io/canary-by-cookie: "canary-cookie"
nginx.ingress.kubernetes.io/canary-weight: "50"
spec:
rules:
- host: canary.echo.example
http:
paths:
- path: /
backend:
serviceName: http-record
servicePort: 80
执行:
kubectl -n demo-echo create -f canary-version-echo-example-ingress.yaml
nginx.ingress.kubernetes.io/canary: true 是启用 canary,其余几个 annotation 分别是设置导向 cannary 的条件、权重。
金丝雀效果
使用下面的方式时,50% 的请求转发到金丝雀服务(对应设置 canary-weight):
$ curl -H "Host: canary.echo.example" 192.168.99.100:30933/
带有 "version: canary" 头的请求,转发到金丝雀服务(对应设置 canary-by-header 和 canary-by-header-value):
$ curl -H "Host: canary.echo.example" -H "version: canary" 192.168.99.100:30933/
带有 canary-cookie 且 cookie 值为 always 的请求,转发到金丝雀服务(对应设置 canary-by-cookie):
$ curl -H "Host: canary.echo.example" -b canary-cookie=always 192.168.99.100:30933/
带有 canary-cookie 且 cookie 值为 always 的请求,转发到主服务(对应设置 canary-by-cookie):
$ curl -H "Host: canary.echo.example" -b canary-cookie=never 192.168.99.100:30933/
header、cookie、weight 的优先级:canary-by-header -> canary-by-cookie -> canary-weight。
参考
ingress-nginx 的常用注解
Annotations 中列出了 ingress-nginx 支持的 annotation,
后端超时设置
nginx.ingress.kubernetes.io/proxy-connect-timeout # 后端连接超时,默认 60 秒
nginx.ingress.kubernetes.io/proxy-send-timeout # 后端发送超时,默认 120 秒
nginx.ingress.kubernetes.io/proxy-read-timeout # 后端读取超时,默认 120 秒
后端重试设置
重试条件设置:
nginx.ingress.kubernetes.io/proxy-next-upstream # 默认 "error timeout"
proxy-next-upstream 是 nginx 的 标准指令,它定义了将请求转发另一个 upstream 的情况,支持以下的值,可以同时使用:
error
timeout
invalid_header
http_500
http_502
http_503
http_504
http_403
http_404
http_429
non_idempotent
off
重试超时设置:
nginx.ingress.kubernetes.io/proxy-next-upstream-timeout # 超时时间,默认 0 秒
nginx.ingress.kubernetes.io/proxy-next-upstream-tries # 重试次数,默认 3 次
请求缓存:
nginx.ingress.kubernetes.io/proxy-request-buffering # 缓存请求,默认 on
开启请求缓存时,ingress 暂存收到的客户端的请求,请求数据全部收齐后,再将请求转发给 upstream。
缓存区设置
请求缓冲区大小,默认为两个内存页面,通常是 8k 和 16k,超过的请求被写入临时文件暂存:
nginx.ingress.kubernetes.io/client-body-buffer-size "1000" # 默认 8k
客户端请求最大长度:
nginx.ingress.kubernetes.io/proxy-body-size # 默认 8m
响应数据缓冲区大小(从响应头读取的第一块数据大小),默认为 1 个页面,通常是 4k 和 8k:
nginx.ingress.kubernetes.io/proxy-buffer-size # 默认 4k
参考
ingress-nginx 的相关笔记汇总
参考
istio 使用手册
了解 istio 的使用方法,学习借鉴 istio 的实现思路。
从这里开始: istio 部署环境准备
相关笔记
参考
istio 的部署
在 Kubernetes 集群中部署 istio 是最方便的,参考 Installing on Kubernetes。
- 单纯了解学习,部署 istio 预览版
- 生产使用,部署 istio 生产版
无论采用哪种方式部署,都需要下载 istio 部署文件,准备一个 kubernetes 集群。部署文件到 github 下载,Kubernetes 集群可以使用 minikube 部署一个单机版的 kubernetes。
本手册中部署的 istio 版本是 1.2.5:
Istio 1.2 has been tested with these Kubernetes releases: 1.12, 1.13, 1.14.
准备 kubernetes 集群
单机版 Kubernetes 集群创建:minkube 使用手册。
多机版 Kubernetes 集群参考(下面三份文档比较老,以后会更新):
- 《Kubernetes1.12从零开始(三):用kubeadm部署多节点集群》
- 《Kubernetes1.12从零开始(五):自己动手部署kubernetes》
- 《Kubernetes1.12从零开始(六):从代码编译到自动部署》
下载 istio 部署文件
从 github 的 release 页面下载 istio,例如:
wget https://github.com/istio/istio/releases/download/1.2.5/istio-1.2.5-linux.tar.gz
本手册的操作环境是 mac + minikube,下载的是 istio-1.2.5-osx.tar.gz:
wget https://github.com/istio/istio/releases/download/1.2.5/istio-1.2.5-osx.tar.gz
解压后得到 istio-1.2.5,里面有安装文件和操作命令(bin/istioctl):
$ tree -L 1 istio-1.2.5
istio-1.2.5
├── LICENSE
├── README.md
├── bin
├── install
├── istio.VERSION
├── samples
└── tools
或者直接 clone 整个 istio 项目,然后切换到要使用的版本,这种方式需要自己编译 istio,编写部署文件:
git clone https://github.com/istio/istio.git
git checkout 1.2.5 -b 1.2.5
源码目录 install/kubernetes 中提供了一些部署文件:
➜ istio git:(1.2.5) ✗ tree install/kubernetes -L 3
install/kubernetes
├── README.md
├── ansible
│ ├── OWNERS
│ ├── README.md
│ ├── ansible.cfg
│ ├── istio
│ │ ├── defaults
│ │ ├── meta
│ │ ├── tasks
│ │ └── vars
│ └── main.yml
├── global-default-sidecar-scope.yaml
├── helm
│ ├── README.md
│ ├── helm-service-account.yaml
│ ├── istio
│ │ ├── Chart.yaml
│ │ ├── LICENSE
│ │ ├── README.md
│ │ ├── charts
│ │ ├── example-values
│ │ ├── files
│ │ ├── requirements.yaml
│ │ ├── templates
│ │ ├── test-values
│ │ ├── values-istio-demo-auth.yaml
│ │ ├── values-istio-demo-common.yaml
│ │ ├── values-istio-demo.yaml
│ │ ├── values-istio-minimal.yaml
│ │ ├── values-istio-remote.yaml
│ │ ├── values-istio-sds-auth.yaml
│ │ └── values.yaml
│ └── istio-init
│ ├── Chart.yaml
│ ├── LICENSE
│ ├── README.md
│ ├── files
│ ├── templates
│ └── values.yaml
├── mesh-expansion.yaml
└── namespace.yaml
部署操作见后面的章节。
参考
istio 预览版部署
在 kubernetes 集群中部署 istio 最方便,istio 在快速迭代更新阶段,部署方法也在变,老版本使用的安装方法,对新版本可能不适用,建议经常查看 istio 的 Installation Guides。
这篇文档最早使用 yaml 文件部署的 istio 1.2.5,后来用 helm 的方式 重新部署了 istio 1.4.0,没有采用 istioctl的方式,是因为 1.4.0 的 istioctl upgrade 还在试验特性,不想踩后续版本升级的坑。
以后的主流部署方式肯定是 istioctl 方式。
版本升级
istio 提供了 几种 升级方法:
- 通过 kubernetes rolling update 升级
- 通过 istioctl upgrade (试验阶段,1.3.3 开始支持)
kubernetes rolling update 现在只支持 helm 的方式,详细操作过程见 upgrade using Helm。
istio 1.4.0 部署——Helm 方式
参考文档 Customizable Install with Helm,添加 helm repp:
helm repo add istio.io https://storage.googleapis.com/istio-release/releases/1.4.0/charts/
从 istio/releases 页面下载 1.4.0 的部署文件
wget https://github.com/istio/istio/releases/download/1.4.0/istio-1.4.0-linux.tar.gz
tar -xvf istio-1.4.0-linux
cd istio-1.4.0
安装前准备,这里用 nodeport 的方式暴露 istio 服务(添加了命令行参数 --set gateways.istio-ingressgateway.type=NodePort)默认情况是 LoadBalancer 方式:
$ kubectl create namespace istio-system
$ helm template install/kubernetes/helm/istio-init \
--name istio-init \
--namespace istio-system \
--set gateways.istio-ingressgateway.type=NodePort \
| kubectl apply -f -
$ kubectl -n istio-system wait --for=condition=complete job --all
上面的命令显示下面的结果后,再继续往下操作:
$ kubectl -n istio-system wait --for=condition=complete job --all
job.batch/istio-init-crd-10-1.4.0 condition met
job.batch/istio-init-crd-11-1.4.0 condition met
job.batch/istio-init-crd-14-1.4.0 condition met
最后安装 istio,Customizable Install with Helm 给出了多个配置版本,因为环境资源有限,这里选用 demo 版本:
$ helm template install/kubernetes/helm/istio --name istio --namespace istio-system \
--values install/kubernetes/helm/istio/values-istio-demo.yaml | kubectl apply -f -
Pod 启动完成后,部署结束:
$ kubectl -n istio-system get pod
NAME READY STATUS RESTARTS AGE
grafana-584949b9c6-w8w8t 1/1 Running 0 21m
istio-citadel-8575bd45c6-69lts 1/1 Running 0 20m
istio-egressgateway-79d56c9f58-sd8xb 1/1 Running 0 17m
istio-galley-7f8b95bff6-9q8pk 1/1 Running 0 21m
istio-grafana-post-install-1.4.0-m7lnb 0/1 Completed 0 21m
istio-ingressgateway-75d6d5fd99-m2jnf 1/1 Running 0 21m
istio-init-crd-10-1.4.0-7fh25 0/1 Completed 0 26m
istio-init-crd-11-1.4.0-jbcpd 0/1 Completed 0 26m
istio-init-crd-14-1.4.0-v7rkw 0/1 Completed 0 26m
istio-pilot-785bc88559-jjzvl 2/2 Running 3 20m
istio-policy-6ddfd68f86-shj5l 2/2 Running 6 20m
istio-security-post-install-1.4.0-96bs5 0/1 Completed 0 21m
istio-sidecar-injector-6c9d6cd87c-x586r 1/1 Running 0 20m
istio-telemetry-598988779b-4zst5 2/2 Running 7 20m
istio-tracing-795c9c64c4-8wdns 1/1 Running 0 20m
kiali-7d4cf866cc-qmkc6 1/1 Running 0 21m
prometheus-8685f659f-xmvlp 1/1 Running 0 20m
如果 kubernetes 用的 minikube,用下面的命令查看 istio 的服务:
$ ./minkube service -n istio-system list
|--------------|------------------------|--------------------------------|
| NAMESPACE | NAME | URL |
|--------------|------------------------|--------------------------------|
| istio-system | grafana | No node port |
| istio-system | istio-citadel | No node port |
| istio-system | istio-egressgateway | No node port |
| istio-system | istio-galley | No node port |
| istio-system | istio-ingressgateway | http://192.168.99.100:30506 |
| | | http://192.168.99.100:31380 |
| | | http://192.168.99.100:31390 |
| | | http://192.168.99.100:31400 |
| | | http://192.168.99.100:31976 |
| | | http://192.168.99.100:31433 |
| | | http://192.168.99.100:32546 |
| | | http://192.168.99.100:32230 |
| | | http://192.168.99.100:30693 |
| istio-system | istio-pilot | No node port |
| istio-system | istio-policy | No node port |
| istio-system | istio-sidecar-injector | No node port |
| istio-system | istio-telemetry | No node port |
| istio-system | jaeger-agent | No node port |
| istio-system | jaeger-collector | No node port |
| istio-system | jaeger-query | No node port |
| istio-system | kiali | No node port |
| istio-system | prometheus | No node port |
| istio-system | tracing | No node port |
| istio-system | zipkin | No node port |
|--------------|------------------------|--------------------------------|
如果之前部署有使用 istio 的容器,用下面的命令重启:
$ kubectl rollout restart deployment --namespace default
istio 1.2.5 部署
这里介绍 istio demo 的部署方法,用这种方式部署的 istio 不能用于生产,只用来了解 istio 的用法和特性,参考 Quick Start Evaluation Install。
这里会使用前面下载 istio 的部署文件(见 下载 istio)。
创建 istio 的 crd
Istio 使用了大量的 CRD,用下面的命令在 kubernetes 集群中创建这些 CRD:
$ for i in install/kubernetes/helm/istio-init/files/crd*yaml; do kubectl apply -f $i; done
customresourcedefinition.apiextensions.k8s.io/virtualservices.networking.istio.io created
customresourcedefinition.apiextensions.k8s.io/destinationrules.networking.istio.io created
customresourcedefinition.apiextensions.k8s.io/serviceentries.networking.istio.io created
customresourcedefinition.apiextensions.k8s.io/gateways.networking.istio.io created
customresourcedefinition.apiextensions.k8s.io/envoyfilters.networking.istio.io created
customresourcedefinition.apiextensions.k8s.io/clusterrbacconfigs.rbac.istio.io created
customresourcedefinition.apiextensions.k8s.io/policies.authentication.istio.io created
customresourcedefinition.apiextensions.k8s.io/meshpolicies.authentication.istio.io created
customresourcedefinition.apiextensions.k8s.io/httpapispecbindings.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/httpapispecs.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/quotaspecbindings.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/quotaspecs.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/rules.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/attributemanifests.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/rbacconfigs.rbac.istio.io created
customresourcedefinition.apiextensions.k8s.io/serviceroles.rbac.istio.io created
customresourcedefinition.apiextensions.k8s.io/servicerolebindings.rbac.istio.io created
customresourcedefinition.apiextensions.k8s.io/adapters.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/instances.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/templates.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/handlers.config.istio.io created
customresourcedefinition.apiextensions.k8s.io/sidecars.networking.istio.io created
customresourcedefinition.apiextensions.k8s.io/authorizationpolicies.rbac.istio.io created
customresourcedefinition.apiextensions.k8s.io/clusterissuers.certmanager.k8s.io created
customresourcedefinition.apiextensions.k8s.io/issuers.certmanager.k8s.io created
customresourcedefinition.apiextensions.k8s.io/certificates.certmanager.k8s.io created
customresourcedefinition.apiextensions.k8s.io/orders.certmanager.k8s.io created
customresourcedefinition.apiextensions.k8s.io/challenges.certmanager.k8s.io created
部署 istio
这里用到的 istio-demo.yaml/istio-demo-auth.yaml,istio 项目代码是没有的,它们在 istio 的 release 文件中,到 istio/releases 页面下载对应版本的 release 文件:
$ wget https://github.com/istio/istio/releases/download/1.2.5/istio-1.2.5-linux.tar.gz
$ tar -xvf istio-1.2.5-linux.tar.gz
$ ls istio-1.2.5/install/kubernetes/istio-demo*
istio-1.2.5/install/kubernetes/istio-demo-auth.yaml
istio-1.2.5/install/kubernetes/istio-demo.yaml
istio-demo.yaml 和 istio-demo-auth.yaml 是两种部署配置,后者强制加密 client 与 server 之间的通信。文件内容是 istio 的 deployment、config、crd 等,这两个文件巨大无比,接近两万行!
用下面的命令创建,可以看到在 kubernetes 中创建了大量的资源:
$ kubectl create -f istio-1.2.5/install/kubernetes/istio-demo.yaml
namespace/istio-system created
secret/kiali created
configmap/istio-galley-configuration created
configmap/istio-grafana-custom-resources created
configmap/istio-grafana-configuration-dashboards-galley-dashboard created
configmap/istio-grafana-configuration-dashboards-istio-mesh-dashboard created
configmap/istio-grafana-configuration-dashboards-istio-performance-dashboard created
configmap/istio-grafana-configuration-dashboards-istio-service-dashboard created
configmap/istio-grafana-configuration-dashboards-istio-workload-dashboard created
....省略...
部署完成
当 istio-system 中的所有 pod 都是 Running 状态时,部署完成:
$ kubectl get pods -n istio-system
NAME READY STATUS RESTARTS AGE
grafana-6575997f54-d8ltw 1/1 Running 1 32m
istio-citadel-555dbdfd6b-kfd86 1/1 Running 1 32m
istio-cleanup-secrets-1.2.5-kv7jf 0/1 Completed 0 32m
istio-egressgateway-79f5b5b958-vr5hf 0/1 Running 1 32m
istio-galley-6855ffd77f-glwtd 1/1 Running 0 47s
istio-grafana-post-install-1.2.5-894k2 0/1 Completed 0 32m
istio-ingressgateway-585b9b66b8-9mwzs 0/1 Running 1 32m
istio-pilot-6d4dcbd54b-8p2fs 1/2 Running 2 32m
istio-policy-56588bf46d-8ft9v 2/2 Running 7 6m58s
istio-security-post-install-1.2.5-wzbkd 0/1 Completed 0 32m
istio-sidecar-injector-74f597fb84-p5n5p 1/1 Running 3 6m58s
istio-telemetry-76c5645cd9-k2r7n 2/2 Running 6 6m58s
istio-tracing-555cf644d-kcwll 1/1 Running 2 32m
kiali-6cd6f9dfb5-rvqg2 1/1 Running 1 32m
prometheus-7d7b9f7844-hngc6 1/1 Running 4 32m
如果使用的 minikube 创建的 kubernetes ,可以用 minikube 查看 istio 服务地址:
$ minkube service list
|---------------|------------------------|--------------------------------|
| NAMESPACE | NAME | URL |
|---------------|------------------------|--------------------------------|
| istio-system | grafana | No node port |
| istio-system | istio-citadel | No node port |
| istio-system | istio-egressgateway | No node port |
| istio-system | istio-galley | No node port |
| istio-system | istio-ingressgateway | http://192.168.99.100:31270 |
| | | http://192.168.99.100:31380 |
| | | http://192.168.99.100:31390 |
| | | http://192.168.99.100:31400 |
| | | http://192.168.99.100:31248 |
| | | http://192.168.99.100:30079 |
| | | http://192.168.99.100:30269 |
| | | http://192.168.99.100:30249 |
| | | http://192.168.99.100:31829 |
| istio-system | istio-pilot | No node port |
| istio-system | istio-policy | No node port |
| istio-system | istio-sidecar-injector | No node port |
| istio-system | istio-telemetry | No node port |
| istio-system | jaeger-agent | No node port |
| istio-system | jaeger-collector | No node port |
| istio-system | jaeger-query | No node port |
| istio-system | kiali | No node port |
| istio-system | prometheus | No node port |
| istio-system | tracing | No node port |
| istio-system | zipkin | No node port |
| kube-system | kube-dns | No node port |
|---------------|------------------------|--------------------------------|
卸载
反向操作即可:
$ kubectl delete -f install/kubernetes/istio-demo.yaml
$ for i in install/kubernetes/helm/istio-init/files/crd*yaml; do kubectl delete -f $i; done
参考
istio 操作命令
istioctl 是 istio 的管理命令,用来部署、管理、调试、诊断。istioctl 管理的是部署在 kubernetes 中的 istio,它通过读取本地的 kubeconfig context,获取的 kubernetes 的地址以及操作权限。
istioctl 命令位于 istio-1.4.0/bin 中,有多个子命令:
--context <string> The name of the kubeconfig context to use (default ``)
--istioNamespace <string> -i Istio system namespace (default `istio-system`)
...
istio 提供的 Web 页面
istio 内置了一些 web 页面,可以用 istioctl dashboard 命令打开。
$ ./istioctl help dashboard
Access to Istio web UIs
Usage:
istioctl dashboard [flags]
istioctl dashboard [command]
Aliases:
dashboard, dash, d
Available Commands:
kiali Open Kiali web UI
controlz Open ControlZ web UI
envoy Open Envoy admin web UI
jaeger Open Jaeger web UI
prometheus Open Prometheus web UI
grafana Open Grafana web UI
zipkin Open Zipkin web UI
kiali,可视化页面
kiali 是 istio 内置的可视化页面:
$ ./istioctl d kiali
http://localhost:50005/kiali

controlz,配置文件
打开配置页面,istio 的配置用 pilot 组件管理的,打开配置页面时,需要指定 pilot 容器:
$ ./istioctl dashboard controlz istio-pilot-785bc88559-jjzvl -n istio-system

envoy,打开指定 envoy 的管理页面
istio 为网格内的每个容器注入了一个 envoy 容器,同时提供打开每个 envoy 的 admin 页面方法:
$ ./istioctl d envoy ratings-v1-779cf974b6-fxmk8
http://localhost:51927
我们可以通过 envoy 的 admin 页面查看 envoy 中规则,envoy 用法参考 envoy 使用手册。

jaejer,调用链
istio 支持 jaejer 和 zipkin。
$ ./istioctl d jaeger
http://localhost:50887

prometheus,监控数据
打开 prometheus 页面:
$ ./istioctl d prometheus
http://localhost:49226

grafana,监控数据
打开 grafana 页面:
$ ./istioctl d grafana
http://localhost:49645

参考
istio 的配置参数
istio 的配置参数非常非常多!
部署时调整参数的方法
用 helm 部署时,通过 --set 设置,如下:
$ kubectl create namespace istio-system
$ helm template install/kubernetes/helm/istio-init \
--name istio-init \
--namespace istio-system \
--set gateways.istio-ingressgateway.type=NodePort \
| kubectl apply -f -
istioctl 查看要使用的部署文件和配置参数:
$ ./istioctl manifest generate
$ ./istioctl profile dump demo # 查看 demo 模式的配置
istioctl 部署时修改参数的方法:
$ istioctl manifest apply --set values.global.mtls.enabled=true \
--set values.global.controlPlaneSecurityEnabled=true
istioctl 支持多种 profile,在部署时用 profile 指定:
# istioctl 支持的 profile
$ ./istioctl profile list
Istio configuration profiles:
default
demo
minimal
remote
sds
# istioctl 部署时指定 demo 模式
$ ./istioctl manifest apply --set profile=demo
istioctl 的更多用法见 istioctl usage。
运行中调整参数的方法
要在运行中调整运行参数,先要知道 istio 的配置参数存放在哪里。istio 的文档中没有明确说明,通过上下文以及相关操作命令判断,istio 的配置参数都在 configmap 中:
$ kubectl -n istio-system get configmap
NAME DATA AGE
istio 2 3d23h
istio-crd-10 1 3d23h
istio-crd-11 1 3d23h
istio-crd-14 1 3d23h
istio-galley-configuration 1 3d23h
istio-grafana 2 3d23h
istio-grafana-configuration-dashboards-citadel-dashboard 1 3d23h
istio-grafana-configuration-dashboards-galley-dashboard 1 3d23h
istio-grafana-configuration-dashboards-istio-mesh-dashboard 1 3d23h
istio-grafana-configuration-dashboards-istio-performance-dashboard 1 3d23h
istio-grafana-configuration-dashboards-istio-service-dashboard 1 3d23h
istio-grafana-configuration-dashboards-istio-workload-dashboard 1 3d23h
istio-grafana-configuration-dashboards-mixer-dashboard 1 3d23h
istio-grafana-configuration-dashboards-pilot-dashboard 1 3d23h
istio-grafana-custom-resources 2 3d23h
istio-security 1 3d23h
istio-security-custom-resources 2 3d23h
istio-sidecar-injector 2 3d23h
kiali 1 3d23h
prometheus 1 3d23h
istioctl 命令可以操作 configmap,例如 istio enabling-policy 中的操作:
# 查看当前配置项
$ kubectl -n istio-system get cm istio -o jsonpath="{@.data.mesh}" | grep disablePolicyChecks
disablePolicyChecks: true
# 修改配置项
$ istioctl manifest apply --set values.global.disablePolicyChecks=false
configmap "istio" replaced
# 查看修改后的配置项
$ kubectl -n istio-system get cm istio -o jsonpath="{@.data.mesh}" | grep disablePolicyChecks
disablePolicyChecks: false
配置参数的含义
这个让人头大,istio 的组件多、配置参数多!
还好 configmap 中有注释,除了逐个研究,没有其它方法:

参考
istio 的功能类别和基本概念
istio 的功能类别
istio 的功能分为四类:
- 流量管理,Traffic Management
- 认证加密,Security
- 访问策略,Policies
- 全局监控,Observability

istio 的基本概念
istio 的规则配置主要围绕下面的概念进行:
- VirtualService, 转发规则
- DestinationRule,均衡策略
- Gateway,对外服务
- ServiceEntry,封装外部服务
- Engress Control, 一种管控外出请求的方法
如果非要类比的话:
- VirtualService 相当于 nginx 中的 Server
- DestinationRule 相当于 nginx 中的 upstream
- Gateway 和 ServiceEntry 相当于 kubernetes 中的 ingress 和 endpoints
istio 的配置模型
istio 定义了大量的 CRD,除了上面的 VirtualService、DestinationRule、Gateway、ServiceEntry,还有指标采集 、日志收集、访问限制、请求改写 中用到的 handler、instance、rule。
Mixer Configuration Model 介绍了 istio 的控制策略和监测度量的配置模型,就是 handler、instance、rule。
handler 和 adapter
handler 主要的用途是配置 adapter,adapters 是一堆适配器,用来对接 prometheus、fluentd 等其它系统,或者实现名单、标准输出等特殊功能。
istio 内置了很多 adapters,adapter 有各自的配置参数:

指标采集 使用的对接 prometheus 的 handler,封装了 adpater prometheus:
# Configuration for a Prometheus handler
apiVersion: config.istio.io/v1alpha2
kind: handler
metadata:
name: doublehandler
namespace: istio-system
spec:
compiledAdapter: prometheus
params:
metrics:
- name: double_request_count # Prometheus metric name
instance_name: doublerequestcount.instance.istio-system # Mixer instance name (fully-qualified)
kind: COUNTER
label_names:
- reporter
- source
- destination
- message
访问限制 使用了 adapter list:
apiVersion: config.istio.io/v1alpha2
kind: handler
metadata:
name: whitelistip
spec:
compiledAdapter: listchecker
params:
# providerUrl: ordinarily black and white lists are maintained
# externally and fetched asynchronously using the providerUrl.
overrides: ["10.57.0.0/16"] # overrides provide a static list
blacklist: false
entryType: IP_ADDRESSES
instance 和 template
instance 的用途是将 mixer 获取的各种属性转换成 apdater 的输入,这个过程需要 templates 介入:
istio 内置了很多 templates:

指标采集 中用到了 template metric:
# Configuration for metric instances
apiVersion: config.istio.io/v1alpha2
kind: instance
metadata:
name: doublerequestcount
namespace: istio-system
spec:
compiledTemplate: metric
params:
value: "2" # count each request twice
dimensions:
reporter: conditional((context.reporter.kind | "inbound") == "outbound", "client", "server")
source: source.workload.name | "unknown"
destination: destination.workload.name | "unknown"
message: '"twice the fun!"'
monitored_resource_type: '"UNSPECIFIED"'
rule:连接 handler 和 instance
rule 设置 handler 的作用范围,并指定为 handler 提供输入的 instance,将 handler 和 instance 配对。
以 按标签设置黑白名单 中的 rule 为例:
apiVersion: "config.istio.io/v1alpha2"
kind: rule
metadata:
name: denyproductpage
spec:
match: destination.labels["app"] == "http-record" && destination.labels["version"] == "v2" && source.labels["app"]=="productpage"
actions:
- handler: denyproductpagehandler
instances: [ denyproductpagerequest ]
上面的配置限定只为从 productpage 到 http-record:v1 的请求,通过 denyproductpagerequest 模板生成状态数据, 作为 denyproductpagehandler 的输入。
instance 和 handler 的定义如下:
---
apiVersion: "config.istio.io/v1alpha2"
kind: handler
metadata:
name: denyproductpagehandler
spec:
compiledAdapter: denier
params:
status:
code: 7
message: Not allowed
---
apiVersion: "config.istio.io/v1alpha2"
kind: instance
metadata:
name: denyproductpagerequest
spec:
compiledTemplate: checknothing
adapter 和 template 的配对
通过 tempalte 生成的状态数据不能用于所有的 adapter,tempalte 和 adapter 之间有配对关系。
template 适用的 adpaters,点击查看最新:

adapter 支持的 templates,点击查看最新:

instance 和 rule 可以使用的属性和属性表达式
[Attributes][15] 是 istio 的核心概念之一。instance 和 rule 都用到了属性和属性表达式,instance 通过属性表达式生成 handler 的输入,rule 通过属性表达式限定 handler 的作用范围。
istio 支持的所有属性:
- [Attributes Vocabulary][16]
istio 属性表达式语法:
- [Expression Language][17]。
自定义 adpater 和 template
istio 请求改写 中使用了自定义的 adpater 和 template。
参考
[14]: https://istio.io/docs/reference/config/policy-and-telemetry/mixer-overview/#rules "Rules' [15]: https://istio.io/docs/reference/config/policy-and-telemetry/mixer-overview/#attributes "Attributes" [16]: https://istio.io/docs/reference/config/policy-and-telemetry/attribute-vocabulary/ "Attribute Vocabulary" [17]: https://istio.io/docs/reference/config/policy-and-telemetry/expression-language/ "Expression Language"
istio 的基本概念:VirtualService
VirtualService 是 istio 的核心概念,它包含一组 route ,定义了请求转发规则,参考 VirtualService。 VirtualService 的配置格式如下:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: my-namespace
spec:
hosts:
- my-namespace.com
http:
- match:
- uri:
prefix: /svc-1
route:
- destination:
host: svc-1.my-namespace.svc.cluster.local
- match:
- uri:
prefix: /svc-2
route:
- destination:
host: svc-2.my-namespace.svc.cluster.local
hosts 是域名匹配规则,限定了 virtualservice 的作用范围,即 virtualservice 中的规则只影响与 hosts 匹配的请求。hosts 匹配规则可以使用通配符。
host(注意和 hosts 字段区分开)是转发目标,符号要求的请求被转发给到 host 中配置的域名。域名既可以是 kubernetes 中的域名(可以跨 namespace),也可以是外部服务的域名。
VirtualService 还可以绑定 gateway(即只处理特定 gateway 的流量),它联结了 DestinationRule、Gateways 和 ServiceEntry,后面章节中会频繁用到 VirtualService。
参考
istio 的基本概念: DestinationRule
DestinationRule 是转发策略,在 route 规则之后起作用,相当于 nginx 中的负载均衡策略。它作用于 VirtualService 的 destination 中的同名的 host。
将 Pod 按照 label 分组,分别设置转发策略
下面的 DestinationRule 作用于 my-svc,影响到 my-svc 的请求的分配策略。
设置了全局的转发策略(subsets 以外的配置),同时将 my-svc 的 pod 按照 label 分成了三组,单独设置了每组的转发策略(subnets 内的配置):
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: my-destination-rule
spec:
host: my-svc
trafficPolicy:
loadBalancer:
simple: RANDOM
subsets:
- name: v1
labels:
version: v1
- name: v2
labels:
version: v2
trafficPolicy:
loadBalancer:
simple: ROUND_ROBIN
- name: v3
labels:
version: v3
- host 指定作用的服务,与 VirtualService 的 Destination 中的 host 配对
- subsets 中的的转发策略覆前面 subsets 外的同名配置
- subsets 中没有的配置,使用 subsets 外的配置
subsets 中 labels 的作用是筛选 pod,上面的配置将 my-svc 的 pod 按照 label 分成了 v1、v2、v3 三组,为每组单独设置转发策略。
将请求按照端口分组,分别设置转发策略
除了按照 pod 分组,还可以按目的端口分组,为每个端口设置转发策略:
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: bookinfo-ratings-port
spec:
host: ratings.prod.svc.cluster.local
trafficPolicy: # Apply to all ports
portLevelSettings:
- port:
number: 80
loadBalancer:
simple: LEAST_CONN
- port:
number: 9080
loadBalancer:
simple: ROUND_ROBIN
Destination Rule 的详情见 Destination Rule。
在 VirtualService 中使用 DestinationRule
在 VirtualService 中指定 destination 时,引用 destination 中的 subset,如下:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: reviews-route
namespace: foo
spec:
hosts:
- reviews # interpreted as reviews.foo.svc.cluster.local
http:
- match:
- uri:
prefix: "/wpcatalog"
- uri:
prefix: "/consumercatalog"
rewrite:
uri: "/newcatalog"
route:
- destination:
host: reviews # interpreted as reviews.foo.svc.cluster.local
subset: v2
- route:
- destination:
host: reviews # interpreted as reviews.foo.svc.cluster.local
subset: v1
参考
istio 的基本概念: Gateways
Gateways 管理南北向流量,也就是从外部流入网格,和从网格流出到外部的流量。它影响网格边界的 envoy ,边界 envoy 通常被分成两组:
- 一组处理外部流入网格的流量,称为 ingress gateway
- 一组处理网格流向外部的流量,称为 egress gateway

Gateway 详细内容见 Envoy Gateway Detail。
允许外部访问集群内服务
下面的配置会被转换成边界 envoy(带有 app: my-gateway-controller 标签的 envoy pod)中的配置:允许访问集群内的 ext-host。
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: ext-host-gwy
spec:
selector:
app: my-gateway-controller
servers:
- port:
number: 443
name: https
protocol: HTTPS
hosts:
- ext-host
tls:
mode: SIMPLE
serverCertificate: /tmp/tls.crt
privateKey: /tmp/tls.key
selector 筛选要作用的 envoy pod,上面的配置的意思是:指示带有 app: my-gateway-controller 标签的 envoy pod (通常是 ingress gateway 的 pod)监听 443端口,放行 host 为 ext-host 的请求。
更复杂的配置
Envoy Gateway Detail 中给出了一个更复杂的示例,同时监听多个端口,每个端口放行不同的请求:
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: my-gateway
namespace: some-config-namespace
spec:
selector:
app: my-gateway-controller
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- uk.bookinfo.com
- eu.bookinfo.com
tls:
httpsRedirect: true # sends 301 redirect for http requests
- port:
number: 443
name: https-443
protocol: HTTPS
hosts:
- uk.bookinfo.com
- eu.bookinfo.com
tls:
mode: SIMPLE # enables HTTPS on this port
serverCertificate: /etc/certs/servercert.pem
privateKey: /etc/certs/privatekey.pem
- port:
number: 9443
name: https-9443
protocol: HTTPS
hosts:
- "bookinfo-namespace/*.bookinfo.com"
tls:
mode: SIMPLE # enables HTTPS on this port
credentialName: bookinfo-secret # fetches certs from Kubernetes secret
- port:
number: 9080
name: http-wildcard
protocol: HTTP
hosts:
- "*"
- port:
number: 2379 # to expose internal service via external port 2379
name: mongo
protocol: MONGO
hosts:
- "*"
在 VirtualService 中使用 Gateway
Gateway 指示边界 envoy 监听端口、放行请求,但是没有告诉边界 envoy 如何转发这些从外部进来的请求,转发规则在 VirtualService 中定义。
Gateway 只有被 VirtualService 引用了,才知道将流入的请求转发到哪里,VirtualService 通过 gateways 字段绑定 Gateway.
将从 some-config-namespace/my-gateway 进来的、目地端口为 27017 的流量转发到 mongo.prod.svc.cluster.local:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: bookinfo-Mongo
namespace: bookinfo-namespace
spec:
hosts:
- mongosvr.prod.svc.cluster.local # name of internal Mongo service
gateways:
- some-config-namespace/my-gateway # can omit the namespace if gateway is in same
# namespace as virtual service.
tcp:
- match:
- port: 27017
route:
- destination:
host: mongo.prod.svc.cluster.local
port:
number: 5555
VirtualService 可以绑定多个 gateway,例如绑定 some-config-namespace/my-gateway 和网格内部(mesh):
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: bookinfo-rule
namespace: bookinfo-namespace
spec:
hosts:
- reviews.prod.svc.cluster.local
- uk.bookinfo.com
- eu.bookinfo.com
gateways:
- some-config-namespace/my-gateway
- mesh # applies to all the sidecars in the mesh
http:
- match:
- headers:
cookie:
exact: "user=dev-123"
route:
- destination:
port:
number: 7777
host: reviews.qa.svc.cluster.local
- match:
- uri:
prefix: /reviews/
route:
- destination:
port:
number: 9080 # can be omitted if it's the only port for reviews
host: reviews.prod.svc.cluster.local
weight: 80
- destination:
host: reviews.qa.svc.cluster.local
weight: 20
这里的 mesh 是一个特殊的存在,它是代表整个网格。
限定 Gateway 的引用范围
如果在 Gateway 中设置了 hosts,那么只能被包含同样的 host 的 VirtualService 绑定:
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: my-gateway
namespace: some-config-namespace
spec:
selector:
app: my-gateway-controller
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- "ns1/*"
- "ns2/foo.bar.com"
ns1/*:名为 ns1 的 namespace 中的所有 VirtualService 都可以绑定 my-gateway。ns2/foo.bar.com:名为 ns2 的namespace 中包含 foo.bar.com 的 VirtualService 可以绑定 my-gateway。
参考
istio 的基本概念:ServiceEntry
ServiceEntry 用来将外部的服务封装成 istio 网格中的服务,为网格内和网格外的服务的统一管理提供基础,详情见 Service Entry Detail。
外部服务被封装为 ServiceEntry,可以像 kubernetes 内部的服务一样使用。
封装外部的域名
外部服务是域名或 IP,下面是域名的例子:
apiVersion: networking.istio.io/v1alpha3
kind: ServiceEntry
metadata:
name: external-svc-https
spec:
hosts:
- api.dropboxapi.com
- www.googleapis.com
- api.facebook.com
location: MESH_EXTERNAL
ports:
- number: 443
name: https
protocol: TLS
resolution: DNS
hosts 是外部服务在网格内的名称,它可以与外部服务的域名相同,可以不同,取决网格内要使用的域名。上面的例子,没有配置外部服务的原始域名,默认原始域名与 hosts 中的域名相同。
如果外部服务在网格内的域名和网格外的域名不同,在 endpoints 中配置原始域名:
apiVersion: networking.istio.io/v1alpha3
kind: ServiceEntry
metadata:
name: external-svc-dns
spec:
hosts:
- foo.bar.com
location: MESH_EXTERNAL
ports:
- number: 80
name: http
protocol: HTTP
resolution: DNS
endpoints:
- address: us.foo.bar.com
ports:
https: 8080
- address: uk.foo.bar.com
ports:
https: 9080
- address: in.foo.bar.com
ports:
https: 7080
resolution 指定解析方式为 DNS。
封装 unix domain socket
unix domain socket 地址也可以封装到网格内:
apiVersion: networking.istio.io/v1alpha3
kind: ServiceEntry
metadata:
name: unix-domain-socket-example
spec:
hosts:
- "example.unix.local"
location: MESH_EXTERNAL
ports:
- number: 80
name: http
protocol: HTTP
resolution: STATIC
endpoints:
- address: unix:///var/run/example/socket
为外部服务配置 vip
将外部服务的多个 ip 封装成名为 mymongodb.somedomain 的网格内服务,并设置网格内 vip:
apiVersion: networking.istio.io/v1alpha3
kind: ServiceEntry
metadata:
name: external-svc-mongocluster
spec:
hosts:
- mymongodb.somedomain # not used
addresses:
- 192.192.192.192/24 # VIPs
ports:
- number: 27018
name: mongodb
protocol: MONGO
location: MESH_INTERNAL
resolution: STATIC
endpoints:
- address: 2.2.2.2
- address: 3.3.3.3
设置外部服务的转发策略
外部服务转发策略的设置方法和内部服务相同,用 DestinationRule 设置,下例子中的 mymongodb.somedomain 是外部服务在网格内的名称:
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: mtls-mongocluster
spec:
host: mymongodb.somedomain
trafficPolicy:
tls:
mode: MUTUAL
clientCertificate: /etc/certs/myclientcert.pem
privateKey: /etc/certs/client_private_key.pem
caCertificates: /etc/certs/rootcacerts.pem
参考
istio 的流出流量管控
Engress Control 不是 istio 的基本概念,而是一种用法。
istio 不仅能够管控从外部流入的流量(通过 Service Entry,也可以管控流出的流量。流出流量的管控复杂一些,同时用到 VirtualService、ServiceEntry 和 Gateway。
基本思路:
- 将外部的服务封装成一个 ServiceEntry
- 创建一个 Gateway,绑定 engress envoy
- 创建一个 VirtualService,将网格内对外部服务请求的转发到 engress envoy
- engress envoy 将收到的请求转发到 ServiceEntry(即外部服务)
将外部服务封装成 ServiceEntry
封装后的外部服务在网格内的名称是 httpbin.com:
apiVersion: networking.istio.io/v1alpha3
kind: ServiceEntry
metadata:
name: external-svc-httpbin
namespace : egress
spec:
hosts:
- httpbin.com
exportTo:
- "."
location: MESH_EXTERNAL
ports:
- number: 80
name: http
protocol: HTTP
resolution: DNS
外部服务的封装方法有多中,见 ServiceEntry)。
创建接收外出流量的 Gateway
创建 Gateway,指示边界的 engress envoy 监听 80 端口,这里选定带有 "istio: egressgateway" 标签的边界 envoy,与接收外部请求的 envoy 区分开:
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: istio-egressgateway
namespace: istio-system
spec:
selector:
istio: egressgateway
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- "*"
创建包含转发规则的 VirtualService
创建 hosts 为 httpbin.com 的 VirtualService,绑定 mesh 和前面创建的 istio-egressgateway:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: gateway-routing
namespace: egress
spec:
hosts:
- httpbin.com
exportTo:
- "*"
gateways:
- mesh
- istio-egressgateway
http:
- match:
- port: 80
gateways:
- mesh
route:
- destination:
host: istio-egressgateway.istio-system.svc.cluster.local
- match:
- port: 80
gateways:
- istio-egressgateway
route:
- destination:
host: httpbin.com
http 中的 两个 match 对应两个转发规则,针对的都是 host 为 httpbin.com 的请求:
-
第一个规则:网格内发起的请求(绑定了 mesh),转发到 istio-egressgateway.istio-system.svc.cluster.local,这个域名是 istio-egressgateway 选择的边界 envoy 在 kubernetes 中的地址,发送到这个地址就是发送到 istio-egressgateway。
-
第二个规则:istio-egressgateway 的 80 端口收到的请求 ,即边界 envoy 接收到的请求(第一个规则设置的从网格内部转来的流量),转发给外部服务 httpbin.com。
在上面两个规则的作用下,从网格内发起的请求先转发给边界 envoy,再由边界 envoy 将转发给外部的 httpbin.com,实现了对 外出流量 的流量集中管控,engress envoy 相当于一个代理服务器。
参考
Istio 的应用示例拆解
Istio 的代码目录和 release 文件中提供多个 应用示例:
$ tree -L 1 istio-1.2.5-linux/samples
istio-1.2.5-linux/samples
├── README.md
├── bookinfo
├── certs
├── custom-bootstrap
├── external
├── fortio
├── health-check
├── helloworld
├── httpbin
├── https
├── kubernetes-blog
├── rawvm
├── sleep
├── tcp-echo
└── websockets
examples 中有简单的介绍,已经拆解的示例:
参考
在 istio 中部署回显 http 请求的 http-record 服务
这是本手册设计的一个服务示例,http-record 的功能特别简单,将收到的请求原封不断回显,同时在标准输出中打印。它和 echoserver 服务的功能类似,但是多了在标准输出中打印的功能,在观察流量复制效果时特别有用。
http-record 容器的用法见 常用工具-HTTP协议相关。
为目标 namespace 打上 label
仅仅在安装了 istio 的 kubernetes 创建应用是不行的,需要在带有 istio-injection=enabled 标签的 namespace 中创建才可以。
这里要在 default 中部署 http-record ,为 default namespace 上打标签:
kubectl label namespace default istio-injection=enabled
Bookinfo Application 对此步操作有更详细的解释。
部署 http-record
用下面的 yaml 创建 http-record 的 Deployment 和 Service:
apiVersion: v1
kind: Service
metadata:
name: http-record
labels:
app: http-record
spec:
ports:
- name: http
port: 8000
targetPort: 8080
selector:
app: http-record
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: http-record-v1
spec:
replicas: 1
template:
metadata:
labels:
app: http-record
version: v1
spec:
containers:
- image: lijiaocn/http-record:0.0.1
imagePullPolicy: IfNotPresent
name: http-record
ports:
- containerPort: 8080
配置 http-record 的 istio 策略
用下面的 yaml 创建 http-record 的 istio 策略:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: http-record
spec:
gateways:
- http-record-gateway
hosts:
- http-record.example
http:
- route:
- destination:
host: http-record
subset: v1
weight: 100
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: http-record
spec:
host: http-record
subsets:
- name: v1
labels:
version: v1
- name: v2
labels:
version: v2
---
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: http-record-gateway
namespace: default
spec:
selector:
istio: ingressgateway
servers:
- hosts:
- 'http-record.example'
port:
name: http
number: 80
protocol: HTTP
效果
通过 istio 的 ingressgateway 访问 http-record 服务,域名为 http-record.example:
$ curl -H "Host: http-record.example" 192.168.99.100:31380
{
"RemoteAddr": "127.0.0.1:52454",
"Method": "GET",
"Host": "http-record.example",
"RequestURI": "/",
"Header": {
"Accept": [
"*/*"
],
"Content-Length": [
"0"
],
"User-Agent": [
"curl/7.54.0"
],
"X-B3-Parentspanid": [
"afc976737b24ece3"
],
"X-B3-Sampled": [
"1"
],
...省略...
参考
istio 的 Bookinfo Application 示例拆解
Istio 文档中给出了一个 Bookinfo Application 示例,这里拆解它的实现。
Bookinfo APP 组成
Bookinfo APP 由四个子系统组成,分别是:
- productpage,产品页,展示图书信息,依赖 details 和 reviews
- details,图书详情查询
- reviews,用户评论查询,依赖 ratings
- ratings,图书排行榜查询
这些子系统分别用 python、ruby、java、node 开发,其中 reviews 系统有三个版本:v1、v2、v3。

示例中把上述四个系统部署在 Kubernetes 中,每个系统由 Service、ServiceAccount、Deployment 组成。reviews 有三个版本,对应三个 Deployment。
部署到 istio 网格
要把 Bookinfo Application 部署在 istio 网格中,仅仅在安装了 istio 的 kubernetes 创建应用是不行的,需要在带有 istio-injection=enabled 标签的 namespace 中创建才可以。
所以 文档 中的第一步操作在目标 namespace 上打标签:
kubectl label namespace default istio-injection=enabled
然后在打了标签的 namespace 中创建应用:
kubectl apply -f samples/bookinfo/platform/kube/bookinfo.yaml
如果不想给 namesapce 打标签,可以用下面的命令调整 yaml 文件:
kubectl apply -f <(istioctl kube-inject -f samples/bookinfo/platform/kube/bookinfo.yaml)
验证 Productpage
部署完成后,验证 productpage,在集群内用它的 cluster ip 或者 pod ip 访问:
$ kubectl get svc productpage -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
productpage ClusterIP 10.110.29.37 <none> 9080/TCP 76d app=productpage
$ curl 10.110.29.37:9080
...省略...
</body>
</html>
或者在 Productpage 等容器内安装 curl,用 curl 验证:
$ kubectl exec -it productpage-v1-667bc85676-sgbqp /bin/sh
$ apt-get update
$ apt-get install -y curl
$ curl http://productpage:9080
...省略...
</body>
</html>
Productpage 是 bookinfo app 的入口,使用 python 开发,从代码中找到另外几个服务的接口:
$ kubectl exec -it productpage-v1-8554d58bff-wlkg7 cat productpage.py >/tmp/productpage.py
查看代码得知其它几个服务的 http 接口,后面将使用这些接口验证服务:
details: http://details:9080/details/0
ratings: http://ratings:9080/ratings/0
reviews: http://reviews:9080/reviews/0
Productpage service 部署 yaml:
apiVersion: v1
kind: Service
metadata:
name: productpage
labels:
app: productpage
service: productpage
spec:
ports:
- port: 9080
name: http
selector:
app: productpage
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: bookinfo-productpage
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: productpage-v1
labels:
app: productpage
version: v1
spec:
replicas: 1
selector:
matchLabels:
app: productpage
version: v1
template:
metadata:
labels:
app: productpage
version: v1
spec:
serviceAccountName: bookinfo-productpage
containers:
- name: productpage
image: docker.io/istio/examples-bookinfo-productpage-v1:1.15.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9080
验证 Detail
完成部署后,验证 details 服务:
$ kubectl get svc details -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
details ClusterIP 10.107.162.106 <none> 9080/TCP 76d app=details
$ curl http://10.107.162.106:9080/details/0
{"id":0,"author":"William Shakespeare","year":1595,"type":"paperback","pages":200,"publisher...省略...
details 服务的部署文件:
##################################################################################
# Details service
###################################################################################
apiVersion: v1
kind: Service
metadata:
name: details
labels:
app: details
service: details
spec:
ports:
- port: 9080
name: http
selector:
app: details
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: bookinfo-details
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: details-v1
labels:
app: details
version: v1
spec:
replicas: 1
selector:
matchLabels:
app: details
version: v1
template:
metadata:
labels:
app: details
version: v1
spec:
serviceAccountName: bookinfo-details
containers:
- name: details
image: docker.io/istio/examples-bookinfo-details-v1:1.15.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9080
---
验证 Ratings
完成部署后,验证 ratings 服务:
$ kubectl get svc ratings -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
ratings ClusterIP 10.107.67.216 <none> 9080/TCP 76d app=ratings
$ curl http://10.107.67.216:9080/ratings/0
{"id":0,"ratings":{"Reviewer1":5,"Reviewer2":4}}$
ratings 服务的部署文件:
###################################################################################
# Ratings service
##################################################################################
apiVersion: v1
kind: Service
metadata:
name: ratings
labels:
app: ratings
service: ratings
spec:
ports:
- port: 9080
name: http
selector:
app: ratings
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: bookinfo-ratings
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: ratings-v1
labels:
app: ratings
version: v1
spec:
replicas: 1
selector:
matchLabels:
app: ratings
version: v1
template:
metadata:
labels:
app: ratings
version: v1
spec:
serviceAccountName: bookinfo-ratings
containers:
- name: ratings
image: docker.io/istio/examples-bookinfo-ratings-v1:1.15.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9080
验证 Reviews
完成部署后,验证 reviews 服务:
$ kubectl get svc reviews -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
reviews ClusterIP 10.100.249.106 <none> 9080/TCP 76d app=reviews
$ curl http://10.100.249.106:9080/reviews/0
{"id": "0","reviews": [{ "reviewer": "Reviewer1", "text": "An extremely entertaining play by Shakespeare....省略...
Reviews 有三个版本,对应三个 Deployment,隶属于同一个 Service:
###################################################################################
# Reviews service
###################################################################################
apiVersion: v1
kind: Service
metadata:
name: reviews
labels:
app: reviews
service: reviews
spec:
ports:
- port: 9080
name: http
selector:
app: reviews
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: bookinfo-reviews
三个版本的 deployment:
V1:
apiVersion: apps/v1
kind: Deployment
metadata:
name: reviews-v1
labels:
app: reviews
version: v1
spec:
replicas: 1
selector:
matchLabels:
app: reviews
version: v1
template:
metadata:
labels:
app: reviews
version: v1
spec:
serviceAccountName: bookinfo-reviews
containers:
- name: reviews
image: docker.io/istio/examples-bookinfo-reviews-v1:1.15.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9080
V2:
apiVersion: apps/v1
kind: Deployment
metadata:
name: reviews-v2
labels:
app: reviews
version: v2
spec:
replicas: 1
selector:
matchLabels:
app: reviews
version: v2
template:
metadata:
labels:
app: reviews
version: v2
spec:
serviceAccountName: bookinfo-reviews
containers:
- name: reviews
image: docker.io/istio/examples-bookinfo-reviews-v2:1.15.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9080
V3:
apiVersion: apps/v1
kind: Deployment
metadata:
name: reviews-v3
labels:
app: reviews
version: v3
spec:
replicas: 1
selector:
matchLabels:
app: reviews
version: v3
template:
metadata:
labels:
app: reviews
version: v3
spec:
serviceAccountName: bookinfo-reviews
containers:
- name: reviews
image: docker.io/istio/examples-bookinfo-reviews-v3:1.15.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9080
创建 Gateway,ingress envoy 开始监听
创建 Gateway,指示边界 envoy 监听 80 端口,允许通过 ingress envoy 的 80 端口访问 Bookinfo:
$ kubectl apply -f samples/bookinfo/networking/bookinfo-gateway.yaml
Gateway 定义:
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: bookinfo-gateway
spec:
selector:
istio: ingressgateway # use istio default controller
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- "*"
如果这时候还没有创建 VirtualService,ingress envoy 还不知道要转发到哪里。
创建 VirtualService,转发请求
创建 VirtualService,指示 ingress envoy 将外部到来的请求转发到 productpage :
$ kubectl apply -f samples/bookinfo/networking/bookinfo-gateway.yaml
VirtualService 定义:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: bookinfo
spec:
hosts:
- "*"
gateways:
- bookinfo-gateway
http:
- match:
- uri:
exact: /productpage
- uri:
prefix: /static
- uri:
exact: /login
- uri:
exact: /logout
- uri:
prefix: /api/v1/products
route:
- destination:
host: productpage
port:
number: 9080
这时可以通过边界 envoy 访问 bookinfo。这里的 hosts 配置是 *,可以根据需要改成具体的域名。
通过边界 envoy 访问应用
边界 envoy 是 istio 的组件之一,由两个服务组成:
$ kubectl -n istio-system get deployment | grep gateway
istio-egressgateway 1/1 1 1 45h
istio-ingressgateway 1/1 1 1 45h
一个负责从外部流入网格的流量(ingress),一个负责从网格流向外部的流量(egress)。
约定 istio-ingressgateway 处理外部进入网格的流量,istio-egressgateway 处理网格流向外部的流量,离开网格的流量的处理参考 Engress Control。
通过 kubernetes 提供的方式访问 istio-ingressgateway:
$ kubectl -n istio-system get service | grep gateway
istio-egressgateway ClusterIP 10.111.134.223 <none> 80/TCP,443/TCP,15443/TCP
istio-ingressgateway LoadBalancer 10.101.187.91 <pending> 15020:31270/TCP,80:31380/TCP,
443:31390/TCP,31400:31400/TCP,
15029:31248/TCP,15030:30079/TCP,
15031:30269/TCP,15032:30249/TCP,
15443:31829/TCP
可以看到 istio-ingressgateway 使用 LoadBalancer 模式,它的 80 端口对应的映射端口是 31380。
如果是用 minikube 部署的 kubernetes,可以用下面的方式获取 istio-ingressgateway 的访问地址:
$ minikube service list
|---------------|------------------------|--------------------------------|
| NAMESPACE | NAME | URL |
|---------------|------------------------|--------------------------------|
| istio-system | istio-ingressgateway | http://192.168.99.100:31270 |
| | | http://192.168.99.100:31380 |
| | | http://192.168.99.100:31390 |
| | | http://192.168.99.100:31400 |
| | | http://192.168.99.100:31248 |
| | | http://192.168.99.100:30079 |
| | | http://192.168.99.100:30269 |
| | | http://192.168.99.100:30249 |
| | | http://192.168.99.100:31829 |
|---------------|------------------------|--------------------------------|
这里使用了 minikube,用下面的 url 访问 bookinfo,path 为 productpage,与 VirtualService 中的配置一致:
http://192.168.99.100:31380/productpage

虽然可以通过边界 envoy 访问应用,但是因为没有设置转发策略,四个子系统之间的互相访问和通过 kubernetes 中的 svc 访问效果相同。
刷新页面会看到页面在变化:

这是因为 reviews 服务有 v1、v2、v3 三个版本,访问 productpage 时,productpage 随机从 reviews 的三个版本的 pod 中获取用户评论数据,所以会看到不同的页面。
可以为每个服务创建一个 VirtualService 和 Destination,精细管控每个服务的转发策略。
设置网格内的转发策略:DestinationRule
为每个服务创建一个 DestinationRule,设置转发策略:
$ kubectl apply -f samples/bookinfo/networking/destination-rule-all.yaml
这里在 DestinationRule 中将 Pod 按照 Label 进行了分组,拆分成多个 subnet:
productpage:
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: productpage
spec:
host: productpage
subsets:
- name: v1
labels:
version: v1
ratings:
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: ratings
spec:
host: ratings
subsets:
- name: v1
labels:
version: v1
- name: v2
labels:
version: v2
- name: v2-mysql
labels:
version: v2-mysql
- name: v2-mysql-vm
labels:
version: v2-mysql-vm
details:
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: details
spec:
host: details
subsets:
- name: v1
labels:
version: v1
- name: v2
labels:
version: v2
reviews:
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: reviews
spec:
host: reviews
subsets:
- name: v1
labels:
version: v1
- name: v2
labels:
version: v2
- name: v3
labels:
version: v3
转发策略被 VirtualService 引用后才生效,参考 Apply a virtual service,还需要为每个服务创建一个 VirtualService,在 VirtualService 中引用 DestinationRule 中的 subset:
$ kubectl apply -f samples/bookinfo/networking/virtual-service-all-v1.yaml
productpage 的 VirtualService:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: productpage
spec:
hosts:
- productpage
http:
- route:
- destination:
host: productpage
subset: v1
details 的 VirtualService:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: details
spec:
hosts:
- details
http:
- route:
- destination:
host: details
subset: v1
ratings 的 VirtualService:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: ratings
spec:
hosts:
- ratings
http:
- route:
- destination:
host: ratings
subset: v1
reviews 的 VirtualService:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: reviews
spec:
hosts:
- reviews
http:
- route:
- destination:
host: reviews
subset: v1
reviews 的 VirtualService 绑定了 reviews 的 subset: v1,这时候访问 bookinfo,页面不再变化。

按照用户转发
更新 reviews 的 VirtualService,将 jason 用户的请求转发到 v2 版本:
$ kubectl apply -f samples/bookinfo/networking/virtual-service-reviews-test-v2.yaml
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: reviews
spec:
hosts:
- reviews
http:
- match:
- headers:
end-user:
exact: jason
route:
- destination:
host: reviews
subset: v2
- route:
- destination:
host: reviews
subset: v1
点击界面右上角的 login,以用户 jason 的身份登录(密码为空),然后刷新页面,会发现页面变成了 v2 版本:

退出 jason 账号后,页面又回到了 v1 版本。
更多操作
Traffic Management 中有更多示范操作,譬如按照 user 转发、错误注入、流量整形、断路器、流量复制等,这些内容放在后面单独整理。
参考
istio 的转发功能使用方法
示例拆解中的 Bookinfo Application 包含了转发功能,这里简单复述下。
转发策略通过 VirtualService 设置,设置 hostname、uri 和目标服务的对应关系,目标服务可以是域名或 IP,对于同一个 namespace 内的服务,可以使用服务名称。
匹配条件中的 hosts,可以是应用的对外域名,实现对外域名到集群内服务的映射。也可以是目标服务自身,实现服务到自身的映射。
下面操作在 Bookinfo Application 的基础上进行。
外部域名到集群内服务的映射
外部域名到集群内服务的映射:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: bookinfo
spec:
hosts:
- "*"
- "bookinfo.xxx.com"
gateways:
- bookinfo-gateway
http:
- match:
- uri:
exact: /productpage
- uri:
prefix: /static
- uri:
exact: /login
- uri:
exact: /logout
- uri:
prefix: /api/v1/products
route:
- destination:
host: productpage
port:
number: 9080
集群内 Service 到自身的映射
集群内 Service 到自身的映射,下面的 hosts 和 host 的值都是 reviews:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: reviews
spec:
hosts:
- reviews
http:
- route:
- destination:
host: reviews
subset: v1
这样可以为 reviews 设置负载均衡策略,上面的 v1 来自于 reivews 服务的 Destination:
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: reviews
spec:
host: reviews
subsets:
- name: v1
labels:
version: v1
- name: v2
labels:
version: v2
- name: v3
labels:
version: v3
VirtualService 支持的匹配规则
VirtualService 支持以下匹配规则:
譬如匹配 headers:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: reviews
spec:
hosts:
- reviews
http:
- match:
- headers:
end-user:
exact: jason
route:
- destination:
host: reviews
subset: v2
- route:
- destination:
host: reviews
subset: v1
参考
istio 的流量切换功能(类似于灰度发布)
istio 好像没有金丝雀以及国内常说的灰度发布概念,它的 Traffic Shifting 可以实现同样的效果,实现思路是在 VirtualService 中配置多个 destination,通过设置每个 destination 的权重,影响流量的分配。
下面操作在 Bookinfo Application 的基础上进行。
HTTP 请求的切换
编辑名为 reviews 的 VirtualService,为默认的 route 设置两个 destination,权重都是 50%:
$ kubectl edit vs reviews
....省略...
- route:
- destination:
host: reviews
subset: v1
weight: 50
- destination:
host: reviews
subset: v3
weight: 50
然后重复刷新页面,会发现页面的 reviews 部分在两个版本之间切换。
TCP 请求的切分
TCP 请求可以按照 destination 的权重分配,设置方法类似,见 TCP Traffic Shifting。
更多配置
参考
istio 错误注入功能的使用方法
Fault Injection 让目标服务以一定的比例返回错误码后者延迟回应,用来测试业务系统的容错能力。
错误注入在 VirtualService 中配置,VirtualService 支持的注入类型,可以在 HTTPFaultInjection 中找到。
下面操作在 Bookinfo Application 的基础上进行。
返回一定的比例的错误码
injecting-an-http-abort-fault 演示如何返回一定比例的错误码。
编辑前面创建的名为 reviews 的 VirtualService,在 http 中添加 fault 配置:
$ kubectl edit vs ratings
...省略...
spec:
hosts:
- ratings
http:
- route:
- destination:
host: ratings
subset: v1
# 添加的 fault 注入,以 100% 的比例返回 500 错误码
- fault:
abort:
httpStatus: 500
percentage:
value: 100
match:
- headers:
end-user:
exact: jason
route:
- destination:
host: ratings
subset: v1
上面配置的 fault 注入只对 jason 用户有效(fault 的 match 中配置的匹配条件,带有 end-user: jason 请求头)。
在 productpage 容器中,用 curl 访问 ratings 服务,带有匹配的 header 时,返回 500:
$ apt-get install curl
$ curl -H "end-user: jason" http://ratings:9080/ratings/0
...省略...
< HTTP/1.1 500 Internal Server Error
< content-length: 18
< content-type: text/plain
< date: Thu, 21 Nov 2019 07:18:51 GMT
< server: envoy
<
* Curl_http_done: called premature == 0
* Connection #0 to host ratings left intact
Productpage 页面会显示 Ratings service is currently unavailable:

通过错误注入,可以非常方便的验证当一个微服务发生故障时,整个应用的运行状态。
注入响应延迟
除了注入错误码,还可以延迟响应,制造超时的场景:injecting-an-http-delay-fault。
更多注入类型
参考
istio 的请求超时时间设置
这里的 Request Timeouts 是等待目标服务响应的超时时间,如果目标服务的响应时间超过了设置,代理本次请求的 envoy 不在等待,直接向请求端返回失败。超时时间在 VirtualService 中设置。
下面操作在 Bookinfo Application 的基础上进行。
设置请求超时时间
编辑名为 reviews 的 VirtualService,在 route 中添加一个超时时间:
$ kubectl edit vs reviews
... 省略 ...
- match:
- headers:
end-user:
exact: jason
route:
- destination:
host: reviews
subset: v2
timeout: 0.5s
... 省略 ...
上面设置的超时时间只对带有 "end-user: jason" 的请求有效。
为了验证超时效果,用 错误注入 功能为 reviews 服务依赖的 ratings 服务注入超过 2s 的超时:
$ kubectl edit vs ratings
...省略...
http:
- fault:
delay:
percent: 100
fixedDelay: 2s
match:
- headers:
end-user:
exact: jason
route:
- destination:
host: ratings
subset: v1
- route:
- destination:
host: ratings
subset: v1
...省略...
只对带有 "end-user: jason" 的请求注入超时。注入超时后,ratings 接口的响应时间超过 2 秒:
$ time curl -H "end-user: jason" http://ratings:9080/ratings/0
{"id":0,"ratings":{"Reviewer1":5,"Reviewer2":4}}
real 0m2.043s
user 0m0.008s
sys 0m0.019s
reviews 服务依赖 ratings 服务,接口响应时间会同时被拉长,继而触发前面设置的 0.5s 超时:
$ curl -H "end-user: jason" http://reviews:9080/reviews/0
upstream request timeout

参考
istio 的流量策略(负载均衡策略)
istio 的流量策略在 DestinationRule 的 TrafficPolicy 中设置,负载均衡是流量策略中的一种。
下面操作在 Bookinfo Application 的基础上进行。
断路保护
istio 的 Circuit Breaking 目前(2019-11-21 19:26:57)相当弱,就是控制一下请求数和并发数,感觉没有 ingress-nginx 的限速功能 实用。
限制 TCP 连接数和单连接请求数
编辑名为 details 的 DestinationRule,添加 trafficPolicy:
$ kubectl edit destinationrules details
...省略...
host: details
trafficPolicy:
connectionPool:
http:
http1MaxPendingRequests: 1
maxRequestsPerConnection: 1
tcp:
maxConnections: 1
...省略...
部署 istio 提供的 fortio client:
$ kubectl apply -f samples/httpbin/sample-client/fortio-deploy.yaml
4 并发测试,会发现部分请求被拒绝(503 错误):
$ FORTIO_POD=$(kubectl get pod | grep fortio | awk '{ print $1 }')
$ kubectl exec -it $FORTIO_POD -c fortio /usr/bin/fortio -- load -c 4 -qps 0 -n 20 -loglevel Warning http://details:9080/details/0
...省略...
Sockets used: 14 (for perfect keepalive, would be 4)
Code 200 : 8 (40.0 %)
Code 503 : 12 (60.0 %)
Response Header Sizes : count 20 avg 63.45 +/- 77.71 min 0 max 159 sum 1269
Response Body/Total Sizes : count 20 avg 281 +/- 46.03 min 241 max 337 sum 5620
All done 20 calls (plus 0 warmup) 39.719 ms avg, 87.7 qps
更多配置
参考
istio 的流量复制功能
istio 的流量复制在 VirtualService 中设置,istio 1.4.x 开始支持。
创建接收复制流量的服务
接收正常请求的服务是前面部署的 http-record v1 。我们准备把这个服务的流量复制同名的 v2 版本的服务。
用下面的 yaml 文件创建 http-record v2,只需要创建 deployment:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: http-record-v2
spec:
replicas: 1
template:
metadata:
labels:
app: http-record
version: v2
spec:
containers:
- image: lijiaocn/http-record:0.0.1
imagePullPolicy: IfNotPresent
name: http-record
ports:
- containerPort: 8080
设置镜像复制策略
编辑之前创建的名为 http-record 的 VirtualService,设置流量复制策略:
$ kubectl edit vs http-record
hosts:
- http-record
http:
- mirror:
host: http-record
subset: v2
mirror_percent: 100
route:
- destination:
host: http-record
subset: v1
weight: 100
上面的配置将 100% 的流量复制到 v2。
复制效果
在任意容器内或者通过 ingressgateway 访问 http-record:
$ curl http-record:8000
同时查看 v1 和 v2 的日志:
$ kubectl logs -f http-record-v1-5f9c95b7cf-t9tzx http-record
$ kubectl logs -f http-record-v2-d697c886-lqpsw http-record
会发现 http-record-v1 和 http-record-v2 的 pod 同时收到了相同的请求。
似乎不支持复制到另一个服务
尝试将到达 Bookinfo Application 的 productpage 的请求复制到 http-record,结果不成功,似乎不支持跨域名复制。
尝试的 yaml 如下:
$ kubectl edit vs productpage
...省略...
hosts:
- productpage
http:
- mirror:
host: http-record
subset: v1
mirror_percent: 100
route:
- destination:
host: productpage
subset: v1
...省略...
访问 productpage:
$ curl productpage:9080
http-record:v1 没有收到复制的请求,istio 不支持跨服务复制吗?(2019-11-22 18:16:01)。
参考
istio 的链路跟踪(调用链)
istio 自动为 pod 发出的 http 请求添加追踪 headers,要实现完整的 链路跟踪,收到请求的应用程序在访问依赖的服务时,需要把请求头中的 headers 带到下一个请求中。
istio 注入的 headers:
x-request-id
x-b3-traceid
x-b3-spanid
x-b3-parentspanid
x-b3-sampled
x-b3-flags
x-ot-span-context
追踪 headers
istio 自动为 pod 发出的 http 请求添加追踪 headers:
$ curl 10.101.26.165:8000
{
"RemoteAddr": "127.0.0.1:54854",
"Method": "GET",
"Host": "10.101.26.165:8000",
"RequestURI": "/",
"Header": {
"Accept": [
"*/*"
],
"Content-Length": [
"0"
],
"User-Agent": [
"curl/7.61.1"
],
"X-B3-Sampled": [
"1"
],
"X-B3-Spanid": [
"cf8b6544e0a1b64c"
],
"X-B3-Traceid": [
"3775c9f1d6b7442acf8b6544e0a1b64c"
],
"X-Forwarded-Proto": [
"http"
],
"X-Request-Id": [
"81360a15-3ac5-9b9c-89ad-4baada513160"
]
},
"Body": ""
怎样把这些 headers 带到下一个请求,取决于应用程序的开发语言,例如 java 可以这样做:
@GET
@Path("/reviews/{productId}")
public Response bookReviewsById(@PathParam("productId") int productId,
@HeaderParam("end-user") String user,
@HeaderParam("x-request-id") String xreq,
@HeaderParam("x-b3-traceid") String xtraceid,
@HeaderParam("x-b3-spanid") String xspanid,
@HeaderParam("x-b3-parentspanid") String xparentspanid,
@HeaderParam("x-b3-sampled") String xsampled,
@HeaderParam("x-b3-flags") String xflags,
@HeaderParam("x-ot-span-context") String xotspan) {
if (ratings_enabled) {
JsonObject ratingsResponse = getRatings(Integer.toString(productId), user, xreq, xtraceid, xspanid, xparentspanid, xsampled, xflags, xotspan);
设置采样频率
istio 支持调用链的抽检,调用链采样频率在 istio-pilot 中设置,默认是 100%:
$ kubectl -n istio-system edit deploy istio-pilot
...
- name: PILOT_TRACE_SAMPLING
value: "100"
...
查看调用链
用 istio 操作命令 中的方法查看:
$ ./istioctl d jaeger
http://localhost:50887
参考
istio 服务运行指标的采集和查看
服务的运行指标要先配置然后才能生成。首先在 istio 中定义一个指标、然后定义指标的收集方式,最后定义指标的收集规则,之后就可以在 istio 中看到采集的指标,参考 Collecting Metrics。
下面操作在 Bookinfo Application 的基础上进行。
创建指标并收集
metrics.yaml 包含了所有需要的配置:
$ kubectl apply -f samples/bookinfo/telemetry/metrics.yaml
instance.config.istio.io/doublerequestcount created
handler.config.istio.io/doublehandler created
rule.config.istio.io/doubleprom created
指标数据生成方法
定义名为 doublerequestcount 的指标,instance 规定了指标的生成方法,dimensions 是生成的指标的属性和属性值:
属性值中可以引用 envoy 和 mixer 生成的属性,见 istio的配置模型,使用了名为 metric 的 template,见 instance 和 template。
# Configuration for metric instances
apiVersion: config.istio.io/v1alpha2
kind: instance
metadata:
name: doublerequestcount
namespace: istio-system
spec:
compiledTemplate: metric
params:
value: "2" # count each request twice
dimensions:
reporter: conditional((context.reporter.kind | "inbound") == "outbound", "client", "server")
source: source.workload.name | "unknown"
destination: destination.workload.name | "unknown"
message: '"twice the fun!"'
monitored_resource_type: '"UNSPECIFIED"'
doublerequestcount 有个四个属性:reporter、source、destination 和 message。
value 是指标的值,这里固定为 2,每次请求都会生成一个带有四个属性、值为 2 的指标。
配置接收指标数据的 adpater
istio 支持多种 adapter,这里使用的是 prometheus,通过配置参数控制向 prometheus 中写入的数据,见 handler 和 adapter。
# Configuration for a Prometheus handler
apiVersion: config.istio.io/v1alpha2
kind: handler
metadata:
name: doublehandler
namespace: istio-system
spec:
compiledAdapter: prometheus
params:
metrics:
- name: double_request_count # Prometheus metric name
instance_name: doublerequestcount.instance.istio-system # Mixer instance name (fully-qualified)
kind: COUNTER
label_names:
- reporter
- source
- destination
- message
上面的配置的意思是在 prometheus 中存放 double_request_count 指标,把指标的四个属性设置为 prometheus 中的 label,把 doublerequestcount 指标的值累加(COUNTER 类型)。
结合前面的指标定义, double_request_count 的指标值固定位 2,每产生一个请求就累加 2,所以这个指标的含义就是“请求发生次数 * 2”。
设置 handler 的作用范围
最后是设置 handler 的作用范围,指定 handler 的输入:
# Rule to send metric instances to a Prometheus handler
apiVersion: config.istio.io/v1alpha2
kind: rule
metadata:
name: doubleprom
namespace: istio-system
spec:
actions:
- handler: doublehandler
instances: [ doublerequestcount ]
上面配置的意思是:把 doublerequestcount 指标存放到 doublehandler,因为只配置了 actions 没有配置 match,所以该规则对所有的请求有效。
采集效果
用 istio操作命令 提供的方法打开 prometheus:
$ ./istioctl d prometheus
http://localhost:49226
刷新几次 bookinfo 网页后,就能在 Prometheus 查询前面创建的指标,名称为 istio_double_request_count,istio_ 是默认前缀:
istio 默认设置的指标
istio 内置了一些指标,指标名称和标签含义见 Default Metrics。
istio 内置的默认指标也是通过 instance、handler 和 rule 设置的。
$ kubectl -n istio-system get instance
NAME AGE
accesslog 7d4h
attributes 7d4h
doublerequestcount 2d4h
keyval 44h
newlog 2d
requestcount 7d4h
requestduration 7d4h
requestsize 7d4h
responsesize 7d4h
tcpaccesslog 7d4h
tcpbytereceived 7d4h
tcpbytesent 7d4h
tcpconnectionsclosed 7d4h
tcpconnectionsopened 7d4h
$ kubectl -n istio-system get handler
NAME AGE
doublehandler 2d4h
keyval 44h
kubernetesenv 7d4h
newloghandler 2d
prometheus 7d4h
stdio 7d4h
$ kubectl -n istio-system get rule
NAME AGE
doubleprom 2d4h
kubeattrgenrulerule 7d4h
newlogstdio 2d
promhttp 7d4h
promtcp 7d4h
promtcpconnectionclosed 7d4h
promtcpconnectionopen 7d4h
stdio 7d4h
stdiotcp 7d4h
tcpkubeattrgenrulerule 7d4h
参考
istio 的日志收集方法
istio 为每个 pod 注入 envoy 容器后,envoy 能够记录每个 pod 的请求。
原始访问日志
是否记录访问日志以及访问日志的存放位置,通过 accessLogFile 设置:
# $ kubectl -n istio-system get configmap istio -o yaml |grep accessLogFile
# Set accessLogFile to empty string to disable access log.
accessLogFile: "/dev/stdout"
默认显示到标准输出,可以用下面的方式查看:
$ kubectl logs -f productpage-v1-667bc85676-sgbqp -c istio-proxy
[2019-11-27T06:45:55.152Z] "GET /reviews/0 HTTP/1.1" 200 - "-" "-" 0 379 74 74 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36" "105f2059-fbc8-9446-8bbb-b9c1a37019bd" "reviews:9080" "172.17.0.32:9080" outbound|9080|v2|reviews.default.svc.cluster.local - 10.100.249.106:9080 172.17.0.27:40612 - -
[2019-11-27T06:45:55.121Z] "GET /productpage HTTP/1.1" 200 - "-" "-" 0 5286 110 103 "172.17.0.1" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36" "105f2059-fbc8-9446-8bbb-b9c1a37019bd" "192.168.99.100:31380" "127.0.0.1:9080" inbound|9080|http|productpage.default.svc.cluster.local - 172.17.0.27:9080 172.17.0.1:0 - default
...
生成并收集日志
istio 支持自定义日志格式,并将统一收集到指定位置。这一步操作和 指标采集 类似,通过 instance、handler 和 route 三个 CRD 设置。
log-entry.yaml 定义了日志 newlog,并收集到 mixer 的标准输出:
$ kubectl apply -f samples/bookinfo/telemetry/log-entry.yaml
instance 定义的日志格式,名称为 newlog,在 params 中设置了级别、时间戳以及属性组成:
# Configuration for logentry instances
apiVersion: config.istio.io/v1alpha2
kind: instance
metadata:
name: newlog
namespace: istio-system
spec:
compiledTemplate: logentry
params:
severity: '"warning"'
timestamp: request.time
variables:
source: source.labels["app"] | source.workload.name | "unknown"
user: source.user | "unknown"
destination: destination.labels["app"] | destination.workload.name | "unknown"
responseCode: response.code | 0
responseSize: response.size | 0
latency: response.duration | "0ms"
monitored_resource_type: '"UNSPECIFIED"'
handler 定义了采集器,名称为 newloghandler,直接打印到 stdio,输出格式为 json:
# Configuration for a stdio handler
apiVersion: config.istio.io/v1alpha2
kind: handler
metadata:
name: newloghandler
namespace: istio-system
spec:
compiledAdapter: stdio
params:
severity_levels:
warning: 1 # Params.Level.WARNING
outputAsJson: true
rule 定义了采集动作,将 newlog 日志收集到 newloghandler:
# Rule to send logentry instances to a stdio handler
apiVersion: config.istio.io/v1alpha2
kind: rule
metadata:
name: newlogstdio
namespace: istio-system
spec:
match: "true" # match for all requests
actions:
- handler: newloghandler
instances:
- newlog
采集效果
上面定义的 newlog 采集规则,将日志输出到标准输出,这里的标准输出是 telemetry 的标准输出:
$ kubectl logs -f -n istio-system -l istio-mixer-type=telemetry -c mixer
{"level":"warn","time":"2019-11-27T08:24:05.706343Z","instance":"newlog.instance.istio-system","destination":"productpage","latency":"1.072931146s","responseCode":200,"responseSize":4183,"source":"istio-ingressgateway","user":"unknown"}
{"level":"warn","time":"2019-11-27T08:24:05.188835Z","instance":"newlog.instance.istio-system","destination":"productpage","latency":"1.654626443s","responseCode":200,"responseSize":4183,"source":"istio-ingressgateway","user":"unknown"}
将日志收集到 es
handler 可以指向多种日志收集系统,例如 通过flutentd收集:
# Configuration for a Fluentd handler
apiVersion: config.istio.io/v1alpha2
kind: handler
metadata:
name: handler
namespace: istio-system
spec:
compiledAdapter: fluentd
params:
address: "fluentd-es.logging:24224"
参考
istio 的访问策略
istio 提供了限速、按 header 路由等访问控制策略。
istio 黑白名单
istio 基于 mixer 获取的属性设置黑白名单,黑白名单也是通过 instance、handler 和 rule 设置。
按标签设置黑白名单
下面三条规则禁止 productpage 访问 http-record v2:
apiVersion: "config.istio.io/v1alpha2"
kind: handler
metadata:
name: denyproductpagehandler
spec:
compiledAdapter: denier
params:
status:
code: 7
message: Not allowed
---
apiVersion: "config.istio.io/v1alpha2"
kind: instance
metadata:
name: denyproductpagerequest
spec:
compiledTemplate: checknothing
---
apiVersion: "config.istio.io/v1alpha2"
kind: rule
metadata:
name: denyproductpage
spec:
match: destination.labels["app"] == "http-record" && destination.labels["version"] == "v2" && source.labels["app"]=="productpage"
actions:
- handler: denyproductpagehandler
instances: [ denyproductpagerequest ]
按标签禁止访问
http-record v1 和 http-record v2 的 ip 地址如下:
$ kubectl get pod --show-labels |grep http-record
http-record-v1-5f9c95b7cf-t9tzx 2/2 Running 0 5d23h 172.17.0.16 app=http-record,pod-template-hash=5f9c95b7cf,security.istio.io/tlsMode=istio,version=v1
http-record-v2-d697c886-lqpsw 2/2 Running 0 5d23h 172.17.0.4 app=http-record,pod-template-hash=d697c886,security.istio.io/tlsMode=istio,version=v2
在 productpage 中访问 http-record v1:
$ curl 172.17.0.16:8080
{
"RemoteAddr": "127.0.0.1:52814",
"Method": "GET",
"Host": "172.17.0.16:8080",
"RequestURI": "/",
"Header": {
...省略...
在 productpage 中访问 http-record v2:
$ curl -v 172.17.0.4:8080
* Rebuilt URL to: 172.17.0.4:8080/
* Trying 172.17.0.4...
* TCP_NODELAY set
* Connected to 172.17.0.4 (172.17.0.4) port 8080 (#0)
> GET / HTTP/1.1
> Host: 172.17.0.4:8080
> User-Agent: curl/7.52.1
> Accept: */*
>
< HTTP/1.1 403 Forbidden
< content-length: 60
< content-type: text/plain
< date: Thu, 28 Nov 2019 06:27:39 GMT
< server: envoy
< x-envoy-upstream-service-time: 4
<
* Curl_http_done: called premature == 0
* Connection #0 to host 172.17.0.4 left intact
PERMISSION_DENIED:denyproductpagehandler.default:Not allowed
通过这个例子我们同时得知,istio 的黑白名单是基于 pod 的,禁止的是 pod 到 pod 的访问。
不过网络层依旧是可达的,网络层不在 istio 的管控范围内:
$ ping 172.17.0.4
PING 172.17.0.4 (172.17.0.4) 56(84) bytes of data.
64 bytes from 172.17.0.4: icmp_seq=1 ttl=64 time=0.367 ms
64 bytes from 172.17.0.4: icmp_seq=2 ttl=64 time=0.046 ms
按 IP 设置黑白名单
这是一个 ip 白名单的例子,只允许特定网段的 client 通过 ingressgateway 访问:
$ kubectl apply -f samples/bookinfo/policy/mixer-rule-deny-ip.yaml
通过下面三项配置,只允许 10.57.0.0/16 网段内的 ingressgateway 的访问:
apiVersion: config.istio.io/v1alpha2
kind: handler
metadata:
name: whitelistip
spec:
compiledAdapter: listchecker
params:
# providerUrl: ordinarily black and white lists are maintained
# externally and fetched asynchronously using the providerUrl.
overrides: ["10.57.0.0/16"] # overrides provide a static list
blacklist: false
entryType: IP_ADDRESSES
---
apiVersion: config.istio.io/v1alpha2
kind: instance
metadata:
name: sourceip
spec:
compiledTemplate: listentry
params:
value: source.ip | ip("0.0.0.0")
---
apiVersion: config.istio.io/v1alpha2
kind: rule
metadata:
name: checkip
spec:
match: source.labels["istio"] == "ingressgateway"
actions:
- handler: whitelistip
instances: [ sourceip ]
这个规则需要说明一下,rule 限定只作用于 ingressgateway,会检查 ingressgateway 的源 IP 是否在白名单内,如果不在就拒绝访问。
我这里的 ingressgateway 的 IP 是 172.17.0.19,不在白名单内:
$ kubectl -n istio-system get pod -o wide |grep ingressgateway
istio-ingressgateway-75d6d5fd99-m2jnf 1/1 Running 1 6d2h 172.17.0.19
通过该 ingressgateway 访问服务会被禁止:

编辑 handler whitelistip,将 172.17 网段加入白名单后,就可以访问了:
$ kubectl edit handler whitelistip
...省略...
spec:
compiledAdapter: listchecker
params:
blacklist: false
entryType: IP_ADDRESSES
overrides:
- 10.57.0.0/16
- 172.17.0.0/16
...
istio 限速策略
istio 的 限速功能 用起来相当繁琐,用到 handler、instance、QuotaSpec、QuotaSpecBinding 和 rule 总共 5 个 CRD。(这么繁琐,想吐槽... 2019-11-27 18:36:29)
$ kubectl apply -f samples/bookinfo/policy/mixer-rule-productpage-ratelimit.yaml
instance 定义了度量的维度,后面的 handler 会使用这些维度属性:
apiVersion: config.istio.io/v1alpha2
kind: instance
metadata:
name: requestcountquota
namespace: istio-system
spec:
compiledTemplate: quota
params:
dimensions:
source: request.headers["x-forwarded-for"] | "unknown"
destination: destination.labels["app"] | destination.service.name | "unknown"
destinationVersion: destination.labels["version"] | "unknown"
handler 定义了基于内存的请求配额管理策略(memquota,众多配额管理器中的一种),设置了限速规则:
apiVersion: config.istio.io/v1alpha2
kind: handler
metadata:
name: quotahandler
namespace: istio-system
spec:
compiledAdapter: memquota
params:
quotas:
- name: requestcountquota.instance.istio-system
maxAmount: 500
validDuration: 1s
# The first matching override is applied.
# A requestcount instance is checked against override dimensions.
overrides:
# The following override applies to 'reviews' regardless
# of the source.
- dimensions:
destination: reviews
maxAmount: 1
validDuration: 5s
# The following override applies to 'productpage' when
# the source is a specific ip address.
- dimensions:
destination: productpage
source: "10.28.11.20"
maxAmount: 500
validDuration: 1s
# The following override applies to 'productpage' regardless
# of the source.
- dimensions:
destination: productpage
maxAmount: 2
validDuration: 5s
rule 设置了限速的范围,对符合条件的请求启用限速:
apiVersion: config.istio.io/v1alpha2
kind: rule
metadata:
name: quota
namespace: istio-system
spec:
# quota only applies if you are not logged in.
# match: match(request.headers["cookie"], "user=*") == false
actions:
- handler: quotahandler
instances:
- requestcountquota
QuotaSpec 是分配的限速配额,它将被绑定到要被限速的服务:
apiVersion: config.istio.io/v1alpha2
kind: QuotaSpec
metadata:
name: request-count
namespace: istio-system
spec:
rules:
- quotas:
- charge: 1
quota: requestcountquota
QuotaSpecBinding 将限速配额与目标服务绑定:
apiVersion: config.istio.io/v1alpha2
kind: QuotaSpecBinding
metadata:
name: request-count
namespace: istio-system
spec:
quotaSpecs:
- name: request-count
namespace: istio-system
services:
- name: productpage
namespace: default
# - service: '*' # Uncomment this to bind *all* services to request-count
这些配置的最终效果是:
productpage 的访问频率限制为 5 秒 2 次,如源头 IP 是 10.28.11.20,访问限速为 500次/s。
reviews 的访问频率限制为 5 秒 1 次。
其它服务的访问频率限制为 500 次/s
参考
istio 的请求改写功能
istio 可以按照用户的定义改写请求,譬如增加请求头、改写 uri、请求重定向等。
Control Headers and Routing 演示了改写请求的方法同时也演示了 istio 的 adpater 的用法。
启动 adpater
keyval adpater 是一个 key:value 服务,输入 key 返回 value,如果 key 不存在返回 NOT_FOUND。
启动 keyval 容器:
$ kubectl run keyval --image=gcr.io/istio-testing/keyval:release-1.1 --namespace istio-system --port 9070 --expose
确定 keyval 创建成功:
$ kubectl -n istio-system get pod |grep keyval
keyval-57f7c4b4cc-t5xw7 1/1 Running 0 2m51s
把 keyval 封装成 istio 的 adapter:
$ kubectl apply -f samples/httpbin/policy/keyval-template.yaml
$ kubectl apply -f samples/httpbin/policy/keyval.yaml
keyval-template.yaml 的类型是 template,keyval.yaml 的类型是 adapter, 现在只能判断这就是在 handler 中使用的 adapter。
adapter 的运行、衔接机制现在还不清楚(2019-11-27 19:25:30)。adapter 显然是 istio 的重点特性,istio 的灵活性很大一部分来自于 apdater。
创建 handler
handler 引用了前面的创建的 adpater,并设置了 params(一个 K-V 查找表)
$ kubectl apply -f - <<EOF
apiVersion: config.istio.io/v1alpha2
kind: handler
metadata:
name: keyval
namespace: istio-system
spec:
adapter: keyval
connection:
address: keyval:9070
params:
table:
jason: admin
EOF
创建 instance
instance 引用了前面创建的 template:
$ kubectl apply -f - <<EOF
apiVersion: config.istio.io/v1alpha2
kind: instance
metadata:
name: keyval
namespace: istio-system
spec:
template: keyval
params:
key: request.headers["user"] | ""
EOF
这个 instance 的含义使用请求头中的 user 头的值作为 key,从 keyval 获取价值。
前面的 adpater 中设置的 jason 对应的只为 admin,后面会用到这个 key。
创建 rule
rule 将前面创建的 handler 和 instance 绑定,设置了处理动作(注入 user-group header):
$ kubectl apply -f - <<EOF
apiVersion: config.istio.io/v1alpha2
kind: rule
metadata:
name: keyval
namespace: istio-system
spec:
actions:
- handler: keyval.istio-system
instances: [ keyval ]
name: x
requestHeaderOperations:
- name: user-group
values: [ x.output.value ]
EOF
这个 handler 的含义是读取前面创建的 instance 的值(x),然后在请求头中添加一个 user-group header,字段值为 instaces 的值。
http 头改写效果
带上 user:jason 请求头,访问 http-record 服务(一个回显请求的 http 服务):
curl -H "user:jason" 10.101.26.165:8000
{
"RemoteAddr": "127.0.0.1:41098",
"Method": "GET",
"Host": "10.101.26.165:8000",
"RequestURI": "/",
"Header": {
"Accept": [
"*/*"
],
"Content-Length": [
"0"
],
"User": [
"jason"
],
"User-Agent": [
"curl/7.61.1"
],
"User-Group": [
"admin"
],
"X-B3-Sampled": [
"1"
],
"X-B3-Spanid": [
"51eb9b405f2c1207"
],
"X-B3-Traceid": [
"a63afc71120d234051eb9b405f2c1207"
],
"X-Forwarded-Proto": [
"http"
],
"X-Request-Id": [
"877e616c-7abc-93f4-913d-7dea33b3144e"
]
},
"Body": ""
}
可以看到服务端接收的请求头中多了一个 "User-Group”。
修改 uri
修改 uri 的操作和注入请求头类似:
$ kubectl apply -f - <<EOF
apiVersion: config.istio.io/v1alpha2
kind: rule
metadata:
name: keyval
namespace: istio-system
spec:
match: source.labels["istio"] == "ingressgateway"
actions:
- handler: keyval.istio-system
instances: [ keyval ]
requestHeaderOperations:
- name: :path
values: [ '"/status/418"' ]
EOF
上面的定义中使用了 match,只影响到 ingressgateway 的请求,通过 ingressgateway 访问,uri 被改写:
$ curl -H "user: jason" -H "Host: http-record.example" 192.168.99.100:31380
{
"RemoteAddr": "127.0.0.1:50684",
"Method": "GET",
"Host": "http-record.example",
"RequestURI": "/status/418",
...省略...
参考
Envoy
初次了解 Envoy 时做过一些笔记,这里是再次学习时,对原先笔记的进一步整理。
这本手册的内容会根据实际工作的需要进行扩展,比较贴近实际。
手册目录在页面左侧,如果是在手机端查看,点击左上角的 符号。
视频讲解:Envoy手把手入门视频讲解
环境和素材准备
docker pull envoyproxy/envoy:v1.11.0
git clone https://github.com/introclass/go-code-example.git
历史文章收录
下面是 以前的 笔记,内容相对杂乱,不如当前手册条理、清晰,仅供参考:
- 《Envoy Proxy使用介绍教程(一):新型L3~L7层访问代理软件Envoy的使用》
- 《Envoy Proxy使用介绍教程(二):envoy源代码阅读、集成开发环境(IDE)》
- 《Envoy Proxy使用介绍教程(三):envoy设计思路、配置文件和功能特性概览》
- 《Envoy Proxy使用介绍教程(四):envoy源代码走读&启动过程分析》
- 《Envoy Proxy使用介绍教程(五):envoy的配置文件完全展开介绍》
- 《Envoy Proxy使用介绍教程(六):envoy一些简单功能/基础配置的使用方法》
- 《Envoy Proxy使用介绍教程(七):envoy动态配置xDS的使用方法》
- 《Envoy Proxy使用介绍教程(八):envoy动态配置-聚合发现ADS的使用方法》
- 《Envoy Proxy使用介绍教程(九):envoy的应用方法与使用约束》
参考
视频讲解:Envoy手把手入门视频讲解
Envoy 安装运行
Envoy 以 docker 镜像的方式分发,社区提供的镜像位于 envoyproxy 中,常用的有:
- envoyproxy/envoy-alpine 基于 alpine 的发行镜像
- envoyproxy/envoy 基于 ubuntu 的发行镜像
获取镜像:
docker pull envoyproxy/envoy:v1.11.0
启动 envoy 容器时,可以用本地的 envoy.yaml 覆盖镜像中的 envoy.yaml:
docker run -idt --network=host -v `pwd`/envoy.yaml:/etc/envoy/envoy.yaml envoyproxy/envoy:v1.11.0
envoy 镜像中包含的命令非常少,可以自己在里面安装一些常用的调试命令,例如:
apt-get update
apt-get install -y iputils-ping curl iproute
本手册使用的 envoy 镜像是 “lijiaocn/envoy:v1.11.0”,使用下面的 Dockerfile 生成:
FROM envoyproxy/envoy:v1.11.0
MAINTAINER lijiaocn <[email protected]>
RUN apt-get update && apt-get install -y iputils-ping curl iproute net-tools vim
这个镜像比原始的 envoy 镜像体积大,包含了一些调试工具,适用于开发调试,镜像已经提交到 docker hub,可以直接拉取使用:
docker pull lijiaocn/envoy:v1.11.0
本手册使用的运行方式
Envoy 容器的运行模式根据自己的需要选取,该手册是在 mac 上用非 host 模式运行 envoy 容器,映射了 9901 和 80-86 端口。
运行脚本在 go-code-example/envoydev/xds/envoy-docker-run 中,用 git 获取:
git clone https://github.com/introclass/go-code-example.git
go-code-example 中有多个目录,分别是不同项目的试验素材,本手册使用的代码和脚本位于 envoydev 中:
▾ envoydev/
▾ xds/
▾ envoy-docker-run/
▸ log/
envoy-0-default.yaml
envoy-0-example.yaml
envoy-1-ads-with-xds.yaml
envoy-1-ads.yaml
envoy-1-static.yaml
envoy-1-xds.yaml
envoy-to-grpc-svc.yaml
run.sh*
xds.go
go.mod
go.sum
README.md
通过 run.sh 可以很方便地选择一个配置启动,例如:
cd go-code-example/envoydev/xds/envoy-docker-run/
./run.sh envoy-0-example.yaml
运行脚本 run.sh 的内容如下:
IMAGE=lijiaocn/envoy:v1.11.0
NAME=envoy-1.11.0
if [ $# -ne 1 ];then
echo "must choose one config file"
exit 1
fi
config=$1
docker rm -f $NAME 2>&1 1>/dev/null
if [ `uname`="Darwin" ];then
docker run -idt --name $NAME -p 9901:9901 -p 80-86:80-86 -v `pwd`/$config:/etc/envoy/envoy.yaml -v `pwd`/log:/var/log/envoy $IMAGE
else
docker run -idt --name $NAME -e loglevel=debug --network=host -v `pwd`/$config:/etc/envoy/envoy.yaml -v `pwd`/log:/var/log/envoy $IMAGE
fi
参考
视频讲解:Envoy手把手入门视频讲解
用 echoserver 观察代理/转发效果
echoserver 是一个回显用户请求的 http 服务,用来观察 http 请求的代理/转发效果非常方便。
echoserver 1.10 不支持 HTTP 2.0。
启动 echoserver 容器
准备一个 echoserver 观察 envoy 转发来的请求,echoserver 用途见 HTTP 协议相关的工具。
$ docker run -idt --name echoserver -p 9090:8080 -p 9443:8443 googlecontainer/echoserver:1.10
获取 echoserver 容器的 IP
先获取 echoserver 容器的 IP 地址,确定 envoy 能够访问这个地址:
# echoserver 是容器的名字,替换成你自己的容器名
$ docker inspect echoserver -f "{{.NetworkSettings.Networks.bridge.IPAddress}}"
172.17.0.2
配置 cluster
该示例使用的配置文件是 envoy-0-example.yaml,在 static_resources: -> clusters: 中配置的是 echoserver 容器的地址,注意将 address 替换成你自己的 echoserver 容器的 IP:
- name: service_echo
connect_timeout: 0.25s
type: STATIC
lb_policy: ROUND_ROBIN
#http2_protocol_options: {} # 注意 echoserver 不支持http 2.0,不能有这项配置
load_assignment:
cluster_name: service_echo
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: 172.17.0.2
port_value: 8080
配置 listener
该示例使用的配置文件是 envoy-0-example.yaml,在 static_resources: -> listeners: 中配置的是 listener,这个 listener 监听 80 端口,将 host 匹配 "*" 和 prefix 匹配 "/" 的请求转发给上面配置的 cluster,并且在转发的时候将 host 修改为 www.google.com:
- name: listener_0
address:
socket_address:
protocol: TCP
address: 0.0.0.0
port_value: 80
filter_chains:
- filters:
- name: envoy.http_connection_manager
typed_config:
"@type": type.googleapis.com/envoy.config.filter.network.http_connection_manager.v2.HttpConnectionManager
stat_prefix: ingress_http
route_config:
name: local_route
virtual_hosts:
- name: local_service
domains: ["*"]
routes:
- match:
prefix: "/"
route:
host_rewrite: www.baidu.com
cluster: service_echo
http_filters:
- name: envoy.router
启动,观察效果
上面的配置已经添加到 envoy-0-example.yaml 中,直接用下面的命令启动:
$ ./run.sh envoy-0-example.yaml
访问 envoy 的 80 端口,效果如下,注意观察 echoserver 收到的请求的 host 是 www.baidu.com,这是因为上面的配置里有一项 “host_rewrite: www.baidu.com”:
$ curl 127.0.0.1:80
Hostname: 7759cabd7402
Pod Information:
-no pod information available-
Server values:
server_version=nginx: 1.13.3 - lua: 10008
Request Information:
client_address=172.17.0.3
method=GET
real path=/
query=
request_version=1.1
request_scheme=http
request_uri=http://www.baidu.com:8080/
Request Headers:
accept=*/*
content-length=0
host=www.baidu.com # echoserver 收到的请求的 host
user-agent=curl/7.54.0
x-envoy-expected-rq-timeout-ms=15000
x-forwarded-proto=http
x-request-id=957e0bd8-2fb1-4ff1-8131-f1fff1cb0e9a
Request Body:
-no body in request-
参考
视频讲解:Envoy手把手入门视频讲解
Envoy 的配置文件格式
Envoy 的 API 文档 中,分别给出了每个配置项的格式,《Envoy Proxy使用介绍教程(五):envoy的配置文件完全展开介绍》 将 envoy 1.8.0 的各个配置项格式组合了起来,呈现了 envoy 配置文件的完整轮廓,如下:
{
"node": {
"id": "...",
"cluster": "...",
"metadata": "{...}",
"locality": "{...}",
"build_version": "..."
},
"static_resources": {
"listeners": [],
"clusters": [],
"secrets": []
},
"dynamic_resources": {
"lds_config": "{...}",
"cds_config": "{...}",
"ads_config": "{...}"
},
"cluster_manager": {
"local_cluster_name": "...",
"outlier_detection": "{...}",
"upstream_bind_config": "{...}",
"load_stats_config": "{...}"
},
"hds_config": {
"api_type": "...",
"cluster_names": [],
"grpc_services": [],
"refresh_delay": "{...}",
"request_timeout": "{...}",
"rate_limit_settings": "{...}"
},
"flags_path": "...",
"stats_sinks": [
{
"name": "...",
"config": "{...}"
}
],
"stats_config": {
"stats_tags": [],
"use_all_default_tags": "{...}",
"stats_matcher": "{...}"
},
"stats_flush_interval": "{...}",
"watchdog": {
"miss_timeout": "{...}",
"megamiss_timeout": "{...}",
"kill_timeout": "{...}",
"multikill_timeout": "{...}"
},
"tracing": {
"http": "{...}"
},
"rate_limit_service": {
"grpc_service": "{...}"
},
"runtime": {
"symlink_root": "...",
"subdirectory": "...",
"override_subdirectory": "..."
},
"admin": {
"access_log_path": "...",
"profile_path": "...",
"address": "{...}"
},
"overload_manager": {
"refresh_interval": "{...}",
"resource_monitors": [],
"actions": []
}
}
本手册中用到的几个配置文件
│ ├── envoy-0-default.yaml # envoy 容器中的默认配置
│ ├── envoy-0-example.yaml # 初次体验使用的配置
│ ├── envoy-1-ads-with-xds.yaml # 演示配置下发时用的配置,同时配置了 ads、xds
│ ├── envoy-1-ads.yaml # 只使用 ads 发现配置的配置
│ ├── envoy-1-static.yaml # 完全静态的配置
│ ├── envoy-1-xds.yaml # 只使用 ads 发现配置的配置
│ ├── envoy-to-grpc-svc.yaml # grpc 代理配置
envoy-0-default.yaml 是 envoy 容器中的默认配置文件,内容如下:
admin:
access_log_path: /tmp/admin_access.log
address:
socket_address:
protocol: TCP
address: 127.0.0.1
port_value: 9901
static_resources:
listeners:
- name: listener_0
address:
socket_address:
protocol: TCP
address: 0.0.0.0
port_value: 10000
filter_chains:
- filters:
- name: envoy.http_connection_manager
typed_config:
"@type": type.googleapis.com/envoy.config.filter.network.http_connection_manager.v2.HttpConnectionManager
stat_prefix: ingress_http
route_config:
name: local_route
virtual_hosts:
- name: local_service
domains: ["*"]
routes:
- match:
prefix: "/"
route:
host_rewrite: www.google.com
cluster: service_google
http_filters:
- name: envoy.router
clusters:
- name: service_google
connect_timeout: 0.25s
type: LOGICAL_DNS
# Comment out the following line to test on v6 networks
dns_lookup_family: V4_ONLY
lb_policy: ROUND_ROBIN
load_assignment:
cluster_name: service_google
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: www.google.com
port_value: 443
tls_context:
sni: www.google.com
参考
视频讲解:Envoy手把手入门视频讲解
Envoy 的静态配置示例
监听转发配置(listener、cluster)可以静态配置也可以动态获取,静态配置在 static_resources 中。
这里使用的配置文件是:envoy-1-static.yaml,envoy 启动命令为:
./run.sh envoy-1-static.yaml
转发到 IP
在 clusters 中配置了一个名为 service_echo 的 cluster ,它指向 172.17.0.2:8080,这是 初次体验 中启动的 echoserver 容器的地址:
- name: service_echo
connect_timeout: 0.25s
type: static
lb_policy: ROUND_ROBIN
hosts:
- socket_address:
address: 172.17.0.2
port_value: 8080
也可以使用 load_assignment 的形式:
- name: service_echo
connect_timeout: 0.25s
type: STATIC
lb_policy: ROUND_ROBIN
#http2_protocol_options: {} #echoserver不支持http 2.0
load_assignment:
cluster_name: service_echo
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: 172.17.0.2
port_value: 8080
在 listeners 中配置一个名为 listener_0 的 listener,它监听 80 端口,将匹配 "Host: echo.com" 和 "/" 的请求转发给上面的 cluster:
- name: listener_0
address:
socket_address:
protocol: TCP
address: 0.0.0.0
port_value: 80
filter_chains:
- filters:
- name: envoy.http_connection_manager
config:
stat_prefix: ingress_http
generate_request_id: true
route_config:
name: local_route
virtual_hosts:
- name: local_service
domains: ["echo.com"]
routes:
- match:
prefix: "/"
route:
host_rewrite: echo.com
cluster: service_echo
http_filters:
- name: envoy.router
config:
dynamic_stats: false
直接访问 listener_0,不带 host 时,返回 404:
$ curl -v 127.0.0.1:80
* Rebuilt URL to: 127.0.0.1:80/
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to 127.0.0.1 (127.0.0.1) port 80 (#0)
> GET / HTTP/1.1
> Host: 127.0.0.1
> User-Agent: curl/7.54.0
> Accept: */*
>
< HTTP/1.1 404 Not Found
< date: Fri, 16 Aug 2019 11:50:13 GMT
< server: envoy
< content-length: 0
<
* Connection #0 to host 127.0.0.1 left intact
带上 host,返回 echoserver 的响应:
$ curl 127.0.0.1:80 -H "Host: echo.com"
Hostname: 7759cabd7402
Pod Information:
-no pod information available-
Server values:
server_version=nginx: 1.13.3 - lua: 10008
Request Information:
client_address=172.17.0.3
method=GET
real path=/
query=
request_version=1.1
request_scheme=http
request_uri=http://echo.com:8080/
Request Headers:
accept=*/*
content-length=0
host=echo.com
user-agent=curl/7.54.0
x-envoy-expected-rq-timeout-ms=15000
x-forwarded-proto=http
x-request-id=da973764-051b-409a-9a2b-5293158e83cd
Request Body:
-no body in request-
转发到域名
配置一个名为 service_baidu 的 cluster,endpoint 中填入域名 www.baidu.com:
- name: service_baidu
connect_timeout: 0.25s
type: LOGICAL_DNS
dns_lookup_family: V4_ONLY
lb_policy: ROUND_ROBIN
load_assignment:
cluster_name: service_baidu
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: www.baidu.com
port_value: 443
tls_context:
sni: www.baidu.com
上面使用的类型为 LOGICAL_DNS,会使用域名解析返回的第一个 IP,如果是 STRICT_DNS,则使用域名解析返回的所有 IP,更多类型见 Cluster 的类型。
配置一个 listener 监听 81 端口,将所有请求转发到 www.baidu.com,转发时将 host 改写为 "www.baidu.com":
- name: listener_1
address:
socket_address:
protocol: TCP
address: 0.0.0.0
port_value: 81
filter_chains:
- filters:
- name: envoy.http_connection_manager
typed_config:
"@type": type.googleapis.com/envoy.config.filter.network.http_connection_manager.v2.HttpConnectionManager
stat_prefix: ingress_http
route_config:
name: local_route
virtual_hosts:
- name: local_service
domains: ["*"]
routes:
- match:
prefix: "/"
route:
host_rewrite: www.baidu.com
cluster: service_baidu
http_filters:
- name: envoy.router
访问 127.0.0.1:81,无论 host 是多少,都转发到 www.baidu.com:
$ curl 127.0.0.1:81
...
<title>百度一下,你就知道</title>
...
注意:envoy 解析 www.baidu.com 域名需要一定时间,在 envoy 刚启动、www.baidu.com 域名解析未完成时,会返回 503。
参考
视频讲解:Envoy手把手入门视频讲解
Envoy 的动态配置
Listener、Cluster 等除了在配置文件中静态配置,还可以从控制平面动态获取。下发动态配置的服务叫做 控制平面 ,它的地址以 cluster 的形式在配置文件中静态配置,然后在 dynamic_resources 中引用这个 cluster。
可以动态下发的配置见 Dynamic configuration,主要有:
CDS:cluster 配置动态下发
LDS:listener 配置动态下发
EDS:cluster 中的 endpoint 的动态下发
RDS:listener 中的 route 的动态下发
SDS:证书的动态下发
其中只有 CDS 和 LDS 的发现地址是在 dynamic_resources 中指定的,后面有详细说明。
准备一个控制平面
xds/xds.go 是一个非常简陋的控制平面的实现,它的代码实现在 控制平面实现 章节详细介绍,在这里我们只需要知道它既可以作为 xds 也可以作为 ads。
这个简陋的控制平面的监听地址是 0.0.0.0:5678,它只下发了下面这个 envoy 的配置:
node := &core.Node{
Id: "envoy-64.58",
Cluster: "test",
}
配置文件中使用同样的 ID 和 Cluster 的 envoy 才会接受这个控制平面下发的配置,这里使用的 envoy 配置文件中都使用这个 Id 和 Cluster:
node:
id: "envoy-64.58"
cluster: "test"
编译运行:
git clone https://github.com/introclass/go-code-example.git
cd go-code-example/envoydev/xds/
$ ./xds
Enter to update version 1: Cluster_With_Static_Endpoint
<键入回车符,就开始下发所示的配置>
参考
视频讲解:Envoy手把手入门视频讲解
envoy 用 XDS 动态发现配置的方法
这里使用的配置文件是 envoy-docker-run/envoy-1-xds.yaml。
配置 XDS 的地址
首先在配置文件中静态配置控制平面的地址,地址为简陋控制平面的服务地址,注意将地址修改你自己的环境中的地址:
static_resources:
clusters:
- name: xds_cluster
connect_timeout: 0.25s
type: STATIC
lb_policy: ROUND_ROBIN
http2_protocol_options: {}
load_assignment:
cluster_name: xds_cluster
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
#address: 127.0.0.1
address: 192.168.99.1
port_value: 5678
配置 cds_config 和 lds_config
然后在 cds_config 和 lds_config 中引用前面的配置的 xds_cluster:
dynamic_resources:
cds_config:
api_config_source:
api_type: GRPC
grpc_services:
envoy_grpc:
cluster_name: xds_cluster
lds_config:
api_config_source:
api_type: GRPC
grpc_services:
envoy_grpc:
cluster_name: xds_cluster
运行效果
启动 envoy:
./run.sh envoy-1-xds.yaml
控制平面未启动的时候,envoy 报告连不上控制平面:
$ docker logs -f envoy-1.11.0
...
[2019-09-02 07:51:44.811][1][warning][config] [bazel-out/k8-opt/bin/source/common/config/_virtual_includes/grpc_stream_lib/common/config/grpc_stream.h:87] gRPC config stream closed: 14, upstream connect error or disconnect/reset before headers. reset reason: connection failure
...
启动控制平面,下发第一个配置:
$ ./xds
Enter to update version 1: Cluster_With_Static_Endpoint
ok
envoy 这时打印下面的日志:
$ docker logs -f envoy-1.11.0
...
[2019-09-02 08:00:33.216][1][info][upstream] [source/common/upstream/cluster_manager_impl.cc:495] add/update cluster Cluster_With_Static_Endpoint starting warming
[2019-09-02 08:00:33.216][1][info][upstream] [source/common/upstream/cluster_manager_impl.cc:507] warming cluster Cluster_With_Static_Endpoint complete
...
打开 envoy 的 admin 页面,可以看到动态下发的 cluster_With_Static_Endpoint:

参考
视频讲解:Envoy手把手入门视频讲解
envoy 用 ADS 动态发现配置的方法
这里使用的配置文件是 envoy-docker-run/envoy-1-ads.yaml。
为什么要使用 ADS ?
cds_config 和 lds_config 是分开的,这意味着 cluster 和 listener 配置可以从不同的控制平面获取,这样会遇到配置不同步的问题,即使它们用的是同一个控制平面也可能因为到达次序不同而不同步。
譬如 listenerA 中使用了 clusterA,但是 listenerA 的配置可能在 clusterA 之前下发到 envoy ,使 envoy 认为 listenerA 使用了一个不存在的 clusterA。
ADS 支持所有类型动态配置的下发,并且会处理配置间的依赖,保证配置的下发顺序,是优先选用的配置发现方法,实现原理见配置下发协议的说明 xDS REST and gRPC protocol。
配置 ADS 地址
首先配置 ADS 的地址,ADS 地址的配置方式与 XDS 相同,都是以 cluster 形式在配置文件中设置:
static_resources:
clusters:
- name: ads_cluster
connect_timeout: 0.25s
type: STATIC
lb_policy: ROUND_ROBIN
http2_protocol_options: {}
load_assignment:
cluster_name: ads_cluster
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: 127.0.0.1
port_value: 5678
配置 ads_config
然后配置 ads_config,在 ads_config 中引用上面配置的 ads_cluster,另外 cds_config 和 lds_config 设置成 ads 方式,如下:
dynamic_resources:
ads_config:
api_type: GRPC
grpc_services:
envoy_grpc:
cluster_name: ads_cluster
cds_config: {ads: {}}
lds_config: {ads: {}}
运行效果
除了启动 envoy 时用 envoy-1-ads.yaml 文件,过程与 用 XDS 下发配置 相同:
./run.sh envoy-1-ads.yaml
参考
视频讲解:Envoy手把手入门视频讲解
envoy 的 lds/cds/rds/sds/eds
dynamic_resources 配置中只有 lds_config、cds_config 和 ads_config,分别对应 listenter、cluster 和聚合发现:
"dynamic_resources": {
"lds_config": "{...}",
"cds_config": "{...}",
"ads_config": "{...}"
},
但可以动态下发的配置不只有 listener 和 cluster。
cluster 中的 endpoint、tls 用到的 secret、HttpConnectionManager 中用到 route 也可以动态下发,对应的发现服务分别是 eds、sds、rds。这些发现服务不在 dynamic_resources 中配置,而是独立配置或者在用到它们的 filter 中配置。
RDS 的配置
以 HttpConnectionManager 为例。
HttpConnectionManager 是一个处理 http 请求的 filter,它用到的 http 路由可以从 rds 中动态发现,rds 就在这个 filter 中指定。
下面是我们使用的简陋控制平面中一段代码,可以看到 Rds 字段配置的类型是 Ads,http 路由将从 ads_cluster 中获取:
listen_filter_http_conn_ := &http_conn_manager.HttpConnectionManager{
StatPrefix: "ingress_http",
RouteSpecifier: &http_conn_manager.HttpConnectionManager_Rds{
Rds: &http_conn_manager.Rds{
RouteConfigName: "ads_route",
ConfigSource: &core.ConfigSource{
ConfigSourceSpecifier: &core.ConfigSource_Ads{
Ads: &core.AggregatedConfigSource{}, //使用ADS
},
},
},
},
...
}
类似于 ADS 方式中的 cds_config 和 lds_config:
dynamic_resources:
ads_config:
api_type: GRPC
grpc_services:
envoy_grpc:
cluster_name: ads_cluster
cds_config: {ads: {}}
lds_config: {ads: {}}
参考
视频讲解:Envoy手把手入门视频讲解
Envoy 的控制平面的实现
可以动态下发的配置有:
- cluster
- cluster 中的 endpoint
- listener
- listener 的 Network filter 中的 HTTP connection manager 中的 Virtualhost 中的 RouteConfiguration 中的 route
- serect
示例代码:
git clone https://github.com/introclass/go-code-example.git
下发协议
envoyproxy/data-plane-api 定义了 envoy 的 REST API 和配置下发时使用的通信协议 xDS REST and gRPC protocol,同时 Envoy 开源了一个控制层面的开发框架 envoyproxy/go-control-plane,使用该框架可以快速开发一个控制平面(也就是 xDS 服务),框架已经实现了通信过程,不需要自行实现通信协议。
参考
视频讲解:Envoy手把手入门视频讲解
动态配置在 go-control-plane 中的定义
go-control-plane 中的配置定义与 API 文档 中给出的相同,以 listener 为例:
api 文档中的 listeners :
{
"name": "...",
"address": "{...}",
"filter_chains": [],
"use_original_dst": "{...}",
"per_connection_buffer_limit_bytes": "{...}",
"metadata": "{...}",
"drain_type": "...",
"listener_filters": [],
"listener_filters_timeout": "{...}",
"transparent": "{...}",
"freebind": "{...}",
"socket_options": [],
"tcp_fast_open_queue_length": "{...}",
"traffic_direction": "..."
}
对应 go-control-plane 在 envoy/api/v2/lds.pb.go 中实现的 Listener:
type Listener struct {
Name string
Address *core.Address
FilterChains []*listener.FilterChain
UseOriginalDst *types.BoolValue
PerConnectionBufferLimitBytes *types.UInt32Value
Metadata *core.Metadata
DeprecatedV1 *Listener_DeprecatedV1
DrainType Listener_DrainType
ListenerFilters []*listener.ListenerFilter
ListenerFiltersTimeout *time.Duration
Transparent *types.BoolValue
Freebind *types.BoolValue
SocketOptions []*core.SocketOption
TcpFastOpenQueueLength *types.UInt32Value
XXX_NoUnkeyedLiteral struct{}
XXX_unrecognized []byte
XXX_sizecache int32
}
参考
视频讲解:Envoy手把手入门视频讲解
go-control-plane 的基本用法
go-control-plane 是一个框架,提供了配置下发接口,在它的基础上根据自己的需要开发其它功能。
这里简单说明下用法,下一节有详细的例子,注意 动态配置与 envoy 的配对 的方法。
准备开发环境
用 go mod 引用 go-control-plane:
mkdir envoydev
cd envoydev
go mod init github.com/introclass/go-code-example/envoydev
go get github.com/envoyproxy/[email protected]
使用示例
go-control-plane 中给出了一个简单的例子,snapshotCache 中存放要下发配置,将通过它创建的 server 与 grpcServer 绑定。envoy 通过 grpc 服务获取配置:
import (
"net"
api "github.com/envoyproxy/go-control-plane/envoy/api/v2"
discovery "github.com/envoyproxy/go-control-plane/envoy/service/discovery/v2"
"github.com/envoyproxy/go-control-plane/pkg/cache"
xds "github.com/envoyproxy/go-control-plane/pkg/server"
)
func main() {
snapshotCache := cache.NewSnapshotCache(false, hash{}, nil)
server := xds.NewServer(snapshotCache, nil)
grpcServer := grpc.NewServer()
lis, _ := net.Listen("tcp", ":8080")
discovery.RegisterAggregatedDiscoveryServiceServer(grpcServer, server)
api.RegisterEndpointDiscoveryServiceServer(grpcServer, server)
api.RegisterClusterDiscoveryServiceServer(grpcServer, server)
api.RegisterRouteDiscoveryServiceServer(grpcServer, server)
api.RegisterListenerDiscoveryServiceServer(grpcServer, server)
go func() {
if err := grpcServer.Serve(lis); err != nil {
// error handling
}
}()
}
动态配置与 envoy 的配对
动态配置是关联到 envoy 的 ,每个 envoy 的动态配置都要单独维护。
在 envoy 的配置文件中有一段 node 配置,标注了当前 envoy 所属的 cluster 和 id,envoy 只接受使用同样的 cluster 和 id 的动态配置:
node:
id: "envoy-64.58"
cluster: "test"
...
使用 go-control-plane 实现的控制平面要为每个 envoy 实例维护一份配置:
node := &core.Node{
Id: "envoy-64.58",
Cluster: "test",
}
node_config := &NodeConfig{
node: node,
endpoints: []cache.Resource{}, //[]*api_v2.ClusterLoadAssignment
clusters: []cache.Resource{}, //[]*api_v2.Cluster
routes: []cache.Resource{}, //[]*api_v2.RouteConfiguration
listeners: []cache.Resource{}, //[]*api_v2.Listener
}
参考
视频讲解:Envoy手把手入门视频讲解
go-control-plane 下发配置示例—环境准备
这里演示一个用 go-control-plane 下发配置的例子。
演示用的代码和配置文件位于:github.com/introclass/go-code-example/envoydev/xds。xds.go 是用 go-controle-plane 实现的简陋控制平面,envoy-docker-run 目录中是启动 envoy 容器的文件:
├── envoy-docker-run
│ ├── envoy-0-default.yaml
│ ├── envoy-1-ads-with-xds.yaml
│ ├── envoy-1-ads.yaml
│ ├── envoy-1-static.yaml
│ ├── envoy-1-xds.yaml
│ ├── envoy-to-grpc-svc.yaml
│ ├── log
│ │ └── admin_access.log
│ └── run.sh
└── xds.go
启动 envoy
envoy 启动时使用用配置文件 envoy-1-ads-with-xds.yaml,这个配置文件中
./run.sh envoy-1-ads-with-xds.yaml
envoy-1-ads-with-xds.yaml 中配置了两个 cluster,一个是 ads_cluster 一个是 xds_cluster,后面的演示代码既会下发使用 xds ,也会使用 ads ,所以在配置了这两个 cluster。
│ ├── envoy-0-default.yaml # envoy 容器中的默认配置
│ ├── envoy-0-example.yaml # 初次体验使用的配置
│ ├── envoy-1-ads-with-xds.yaml # 演示配置下发时用的配置,同时配置了 ads、xds
│ ├── envoy-1-ads.yaml # 只使用 ads 发现配置的配置
│ ├── envoy-1-static.yaml # 完全静态的配置
│ ├── envoy-1-xds.yaml # 只使用 ads 发现配置的配置
│ ├── envoy-to-grpc-svc.yaml # grpc 代理配置
演示用的配置文件说明
envoy-1-ads-with-xds.yaml 的内容比较长,分成几段说明。
第一段是 envoy 的常规配置,配置 envoy 的 id、管理接口等:
node:
id: "envoy-64.58"
cluster: "test"
#runtime:
# symlink_root: /srv/runtime/current
# subdirectory: envoy
# override_subdirectory: envoy_override
watchdog:
miss_timeout: 0.2s
megamiss_timeout: 1s
kill_timeout: 0s
multikill_timeout: 0s
flags_path: /etc/envoy/flags/
stats_flush_interval: 5s
stats_config:
use_all_default_tags: true
stats_sinks:
name: envoy.stat_sinks.hystrix
config:
num_buckets: 10
admin:
access_log_path: /var/log/envoy/admin_access.log
profile_path: /var/log/envoy/envoy.prof
address:
socket_address:
protocol: TCP
address: 0.0.0.0
port_value: 9901
第二段是发现配置,这里采用的是 ads 的方式,cds 和 lds 都指向 ads:
dynamic_resources:
ads_config:
api_type: GRPC
grpc_services:
envoy_grpc:
cluster_name: ads_cluster
cds_config: {ads: {}}
lds_config: {ads: {}}
第三段是下发配置,两个 cluster,一个是 ads_cluster,在上一段配置中已经被引用,另一个 xds_cluster在配置文件中没有被用到,但是后面的演示代码下发的配置中会用到。
ads_cluster 和 xds_cluster 的地址都是 127.0.0.1:5678,演示环境中 xds.go 和 envoy 容器在一台机器上,所以这里配置的都是本地地址。
static_resources:
clusters:
- name: ads_cluster
connect_timeout: 0.25s
type: STATIC
lb_policy: ROUND_ROBIN
http2_protocol_options: {}
load_assignment:
cluster_name: ads_cluster
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: 127.0.0.1
port_value: 5678
- name: xds_cluster
connect_timeout: 0.25s
type: STATIC
lb_policy: ROUND_ROBIN
http2_protocol_options: {}
load_assignment:
cluster_name: xds_cluster
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: 127.0.0.1
port_value: 5678
最后 static_resources 中还有两个演示中没有用到的 cluster,一个是指向 8.8.8.8:53 ,一个指向 www.baidu.com,它们只是用来示范 cluster 的配置方法:
- name: dns_google
connect_timeout: 0.25s
type: STATIC
lb_policy: ROUND_ROBIN
http2_protocol_options: {}
load_assignment:
cluster_name: dns_google
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: 8.8.8.8
port_value: 53
- name: service_baidu
connect_timeout: 0.25s
type: LOGICAL_DNS
# Comment out the following line to test on v6 networks
dns_lookup_family: V4_ONLY
lb_policy: ROUND_ROBIN
load_assignment:
cluster_name: service_baidu
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: www.baidu.com
port_value: 443
tls_context:
sni: www.baidu.com
参考
视频讲解:Envoy手把手入门视频讲解
go-control-plane 下发配置示例—代码说明
示例代码是 xds.go,这是一段超级简单、简陋的代码,只用来演示如何下发配置,下面是 xds.go 代码的说明,完整代码见 xds.go。
NodeConfig
NodeConfig 中存放一个 envoy 的所有配置:
+NodeConfig : struct
[fields]
-clusters : []cache.Resource
-endpoints : []cache.Resource
-listeners : []cache.Resource
-node : *core.Node
-routes : []cache.Resource
[methods]
+ID(node *core.Node) : string
代码中创建了下面的 node_config,它的 Id 和 Cluster 与 envoy-0-example.yaml 中的配置是对应的:
node := &core.Node{
Id: "envoy-64.58",
Cluster: "test",
}
node_config := &NodeConfig{
node: node,
endpoints: []cache.Resource{}, //[]*api_v2.ClusterLoadAssignment
clusters: []cache.Resource{}, //[]*api_v2.Cluster
routes: []cache.Resource{}, //[]*api_v2.RouteConfiguration
listeners: []cache.Resource{}, //[]*api_v2.Listener
}
生成配置
下面这些函数用来生成要下发的配置,Cluster_ADS() 生成使用 ADS 发现 Endpoint 的 Cluster,对应的 endpoint 配置用 EDS() 生成,Listener 中动态发现的 Route,用 Route() 生成。
+Cluster_ADS(name string) : *api_v2.Cluster
+Cluster_EDS(name string, edsCluster []string, edsName string) : *api_v2.Cluster
+Cluster_STATIC(name string, addrs []ADDR) : *api_v2.Cluster
+EDS(cluster string, addrs []ADDR) : *api_v2.ClusterLoadAssignment
+Listener_ADS(name string, port uint32, routeName string) : *api_v2.Listener
+Listener_RDS(name string, port uint32, routeName string, rdsCluster []string) : *api_v2.Listener
+Listener_STATIC(name string, port uint32, host, prefix, toCluster string) : *api_v2.Listener
+Route(name, host, prefix, toCluster string) : *api_v2.RouteConfiguration
配置下发
用下面的方式启动 grpc 服务:
snapshotCache := cache.NewSnapshotCache(false, NodeConfig{}, nil)
server := xds.NewServer(snapshotCache, nil)
grpcServer := grpc.NewServer()
lis, _ := net.Listen("tcp", ":5678")
discovery.RegisterAggregatedDiscoveryServiceServer(grpcServer, server)
api_v2.RegisterEndpointDiscoveryServiceServer(grpcServer, server)
api_v2.RegisterClusterDiscoveryServiceServer(grpcServer, server)
api_v2.RegisterRouteDiscoveryServiceServer(grpcServer, server)
api_v2.RegisterListenerDiscoveryServiceServer(grpcServer, server)
go func() {
if err := grpcServer.Serve(lis); err != nil {
// error handling
}
}()
Update_SnapshotCache() 将 node_config 填充到 snapshotCache 中,填充时指定配置的版本号,只要配置号发生了变化就被认为是需要更新的配置,没有递增、回退的概念。
func Update_SnapshotCache(s cache.SnapshotCache, n *NodeConfig, version string) {
err := s.SetSnapshot(n.ID(n.node), cache.NewSnapshot(version, n.endpoints, n.clusters, n.routes, n.listeners))
if err != nil {
glog.Error(err)
}
}
配置下发举例
下发一个通过 xds_cluster 发现 endpoint 的 cluster,cluster 名为 Cluster_With_Dynamic_Endpoint。
{
clusterName := "Cluster_With_Dynamic_Endpoint"
fmt.Printf("\nEnter to update version 2: %s", clusterName)
_, _ = fmt.Scanf("\n", &input)
var addrs []ADDR
addrs = append(addrs, ADDR{
Address: "127.0.0.1",
Port: 8082,
})
point := EDS(clusterName, addrs)
node_config.endpoints = append(node_config.endpoints, point)
var edsCluster []string
edsCluster = append(edsCluster, "xds_cluster") //静态的配置的 cluster
edsName := clusterName
cluster := Cluster_EDS(clusterName, edsCluster, edsName)
node_config.clusters = append(node_config.clusters, cluster)
Update_SnapshotCache(snapshotCache, node_config, "2")
fmt.Printf("ok")
}
参考
视频讲解:Envoy手把手入门视频讲解
go-control-plane 下发配置示例—运行和效果
这里详细演示动态配置的几种组合,使用的 envoy 配置文件是 envoy-1-ads-with-xds.yaml。
启动 envoy:
./run.sh envoy-1-ads-with-xds.yaml
envoy 初始状态
envoy 启动之后,通过 admin 地址(浏览器打开 IP:9901 ) 查看 envoy 的当前配置以及内部情况:

envoy 的当前配置通过 IP:9901/config_dump 查看,通过该地址查询的配置文件是分为几段的:
- 第一段为 "@type": "type.googleapis.com/envoy.admin.v2alpha.BootstrapConfigDump",是 envoy 启动时的配置
- 第二段为 "@type": "type.googleapis.com/envoy.admin.v2alpha.ClustersConfigDump",是 cluster 配置,这里现在只有静态配置的 ads_cluster
- 第三段为 "@type": "type.googleapis.com/envoy.admin.v2alpha.ListenersConfigDump",第三段现在是空的

下发 listener 和 route 后会多出两段配置,里面是动态下发的 route:
- "@type": "type.googleapis.com/envoy.admin.v2alpha.ScopedRoutesConfigDump"
- "@type": "type.googleapis.com/envoy.admin.v2alpha.RoutesConfigDump"

endpoint 在配置页面中看不到,要到 IP:9901/clusters 中查看:

启动控制平面
演示实现的控制平面的功能如下,每按一次回车,下发一组配置:
$ ./xds
Enter to update version 1: Cluster_With_Static_Endpoint
ok
Enter to update version 2: Cluster_With_Dynamic_Endpoint
ok
Enter to update version 3: Cluster_With_ADS_Endpoint
ok
Enter to update version 4: Listener_With_Static_Route
ok
Enter to update version 5: Listener_With_Dynamic_Route
ok
Enter to update version 6: Listener_With_ADS_Route
ok
Enter to exit: ^C
使用静态 endpoint 的 cluster
{
clusterName := "Cluster_With_Static_Endpoint"
fmt.Printf("Enter to update version 1: %s", clusterName)
_, _ = fmt.Scanf("\n", &input)
var addrs []ADDR
addrs = append(addrs, ADDR{
Address: "127.0.0.1",
Port: 8081,
})
cluster := Cluster_STATIC(clusterName, addrs)
node_config.clusters = append(node_config.clusters, cluster)
Update_SnapshotCache(snapshotCache, node_config, "1")
fmt.Printf("ok")
}
下发后多出一个名为 Cluster_With_Static_Endpoint 的 cluster,地址为 127.0.0.1:8081。

使用 eds 发现 endpoint 的 cluster
{
clusterName := "Cluster_With_Dynamic_Endpoint"
fmt.Printf("\nEnter to update version 2: %s", clusterName)
_, _ = fmt.Scanf("\n", &input)
var addrs []ADDR
addrs = append(addrs, ADDR{
Address: "127.0.0.1",
Port: 8082,
})
point := EDS(clusterName, addrs)
node_config.endpoints = append(node_config.endpoints, point)
var edsCluster []string
edsCluster = append(edsCluster, "xds_cluster") //静态的配置的 cluster
edsName := clusterName
cluster := Cluster_EDS(clusterName, edsCluster, edsName)
node_config.clusters = append(node_config.clusters, cluster)
Update_SnapshotCache(snapshotCache, node_config, "2")
fmt.Printf("ok")
}
下发后多出一个名为 Cluster_With_Dynamic_Endpoint 的 cluster,地址为 127.0.0.1:8082。

cluster 中没有直接配置 endpoint,指定从 xds_cluster 中获取,在 IP:9901/clusters 中可以看到 endpoint:

使用 ads 发现 endpoint 的 cluster
{
clusterName := "Cluster_With_ADS_Endpoint"
fmt.Printf("\nEnter to update version 3: %s", clusterName)
_, _ = fmt.Scanf("\n", &input)
var addrs []ADDR
addrs = append(addrs, ADDR{
Address: "127.0.0.1",
Port: 8083,
})
edsName := clusterName
point := EDS(edsName, addrs)
node_config.endpoints = append(node_config.endpoints, point)
cluster := Cluster_ADS("Cluster_With_ADS_Endpoint")
node_config.clusters = append(node_config.clusters, cluster)
Update_SnapshotCache(snapshotCache, node_config, "3")
fmt.Printf("ok")
}
下发后多出一个名为 Cluster_With_ADS_Endpoint 的 cluster,地址为 127.0.0.1:8083。
ads 的配置和 xds 不同,不需要指定 cluster,声明使用 ADS 即可:

使用静态路由的 listener
前面的几个步骤下发了 cluster,没有下发 listener,无法访问 cluster,要访问 cluster 必须配置一个指向它的 listener。
{
listenerName := "Listener_With_Static_Route"
fmt.Printf("\nEnter to update version 4: %s", listenerName)
_, _ = fmt.Scanf("\n", &input)
clusterName := "Listener_With_Static_Route_Target_Cluster"
var addrs []ADDR
addrs = append(addrs, ADDR{
Address: "127.0.0.1",
Port: 8080,
})
cluster := Cluster_STATIC(clusterName, addrs)
node_config.clusters = append(node_config.clusters, cluster)
lis := Listener_STATIC(listenerName, 84, "echo.example", "/abc", clusterName)
node_config.listeners = append(node_config.listeners, lis)
Update_SnapshotCache(snapshotCache, node_config, "4")
fmt.Printf("ok")
}
上面的代码下发了一个监听 84 端口、将请求转发到 172.17.0.2:8080 的 listener,转发规则为 Host 是 echo.example,prefix 是 /abc: 这里的 172.17.0.2:8080,是 初次体验 中启动的 echoserver 容器的地址。
下发以后,在管理界面可以看到下面的配置:

这时候可以通过 84 端口访问 cluster:
$ curl -H "Host: echo.example" 127.0.0.1:84/abc
Hostname: 7759cabd7402
Pod Information:
-no pod information available-
Server values:
server_version=nginx: 1.13.3 - lua: 10008
Request Information:
client_address=172.17.0.3
method=GET
real path=/abc
query=
request_version=1.1
request_scheme=http
request_uri=http://echo.example:8080/abc
Request Headers:
accept=*/*
content-length=0
host=echo.example
user-agent=curl/7.54.0
x-envoy-expected-rq-timeout-ms=15000
x-forwarded-proto=http
x-request-id=8bda7006-87dd-4251-ad3a-431d610ef806
Request Body:
-no body in request-
使用 xds 发现路由的 listener
{
listenerName := "Listener_With_Dynamic_Route"
fmt.Printf("\nEnter to update version 5: %s", listenerName)
_, _ = fmt.Scanf("\n", &input)
clusterName := "Listener_With_Dynamic_Route_Target_Cluster"
var addrs []ADDR
addrs = append(addrs, ADDR{
Address: "172.17.0.2",
Port: 8080,
})
cluster := Cluster_STATIC(clusterName, addrs)
node_config.clusters = append(node_config.clusters, cluster)
routeName := "Listener_With_Dynamic_Route_Route"
r := Route(routeName, "echo.example", "/123", clusterName)
node_config.routes = append(node_config.routes, r)
var rdsCluster []string
rdsCluster = append(rdsCluster, "xds_cluster") //静态的配置的 cluster
lis := Listener_RDS(listenerName, 85, routeName, rdsCluster)
node_config.listeners = append(node_config.listeners, lis)
Update_SnapshotCache(snapshotCache, node_config, "5")
fmt.Printf("ok")
}
上面代码中 rds 配置的是 xds_cluster,xds_cluster 是配置文件中事先配置的静态 cluster:

使用 ads 发现路由的 listener
{
listenerName := "Listener_With_ADS_Route"
fmt.Printf("\nEnter to update version 6: %s", listenerName)
_, _ = fmt.Scanf("\n", &input)
clusterName := "Listener_With_ADS_Route_Target_Cluster"
var addrs []ADDR
addrs = append(addrs, ADDR{
Address: "172.17.0.2",
Port: 8080,
})
cluster := Cluster_STATIC(clusterName, addrs)
node_config.clusters = append(node_config.clusters, cluster)
routeName := "Listener_With_ADS_Route_Route"
r := Route(routeName, "echo.example", "/a1b", clusterName)
node_config.routes = append(node_config.routes, r)
lis := Listener_ADS(listenerName, 86, routeName)
node_config.listeners = append(node_config.listeners, lis)
Update_SnapshotCache(snapshotCache, node_config, "6")
fmt.Printf("ok")
}
上面代码中 rds 配置的是 ads,ads 指向配置文件中事先配置的 ads_cluster:

参考
视频讲解:Envoy手把手入门视频讲解
Envoy 的 Cluster 配置详解
Clusters 相当于 nginx 的 upstream,是一组 IP 或者域名的集合, 是 Envoy 收到的请求最终流向的地方。 Cluster 的配置项比较多,见 Clusters Config:
{
"name": "...",
"alt_stat_name": "...",
"type": "...",
"cluster_type": "{...}",
"eds_cluster_config": "{...}",
"connect_timeout": "{...}",
"per_connection_buffer_limit_bytes": "{...}",
"lb_policy": "...",
"hosts": [],
"load_assignment": "{...}",
"health_checks": [],
"max_requests_per_connection": "{...}",
"circuit_breakers": "{...}",
"tls_context": "{...}",
"common_http_protocol_options": "{...}",
"http_protocol_options": "{...}",
"http2_protocol_options": "{...}",
"extension_protocol_options": "{...}",
"typed_extension_protocol_options": "{...}",
"dns_refresh_rate": "{...}",
"respect_dns_ttl": "...",
"dns_lookup_family": "...",
"dns_resolvers": [],
"outlier_detection": "{...}",
"cleanup_interval": "{...}",
"upstream_bind_config": "{...}",
"lb_subset_config": "{...}",
"ring_hash_lb_config": "{...}",
"original_dst_lb_config": "{...}",
"least_request_lb_config": "{...}",
"common_lb_config": "{...}",
"transport_socket": "{...}",
"metadata": "{...}",
"protocol_selection": "...",
"upstream_connection_options": "{...}",
"close_connections_on_host_health_failure": "...",
"drain_connections_on_host_removal": "...",
"filters": []
}
Cluster 的类型
type 和 cluster_type 是 cluster 的类型,type 是 envoy 支持的标准类型,cluster_type 是自定义类型。
envoy 支持的标准类型按照 service discovery types 分类:
- Static,直接配置 IP 地址
- Strict DNS,通过解析域名获取目标 IP,使用查询出来的所有 IP
- Logical DNS,通过解析域名获取目标 IP,只使用第一个 IP
- Endpoint discovery service(EDS)
- Original destination,透明代理方式
在 go-controller-plane 中的定义分别是:
// envoy/api/v2/cds.pb.go: 43
const (
Cluster_STATIC Cluster_DiscoveryType = 0
Cluster_STRICT_DNS Cluster_DiscoveryType = 1
Cluster_LOGICAL_DNS Cluster_DiscoveryType = 2
Cluster_EDS Cluster_DiscoveryType = 3
Cluster_ORIGINAL_DST Cluster_DiscoveryType = 4
)
在配置文件中的写法分别是:
// envoy/api/v2/cds.pb.go: 72
var Cluster_DiscoveryType_value = map[string]int32{
"STATIC": 0,
"STRICT_DNS": 1,
"LOGICAL_DNS": 2,
"EDS": 3,
"ORIGINAL_DST": 4,
}
Cluster 的 filter
Cluster 的 filter 字段中是 network filter,处理从 cluster 流出(outgoing)的数据。
Cluster 的负载均衡算法
Cluster 支持下面的 负载均衡算法:
- ROUND_ROBIN
- LEAST_REQUEST
- RING_HASH
- RANDOM
- MAGLEV
- CLUSTER_PROVIDED
参考
视频讲解:Envoy手把手入门视频讲解
Envoy 的 Listener 配置详解
Listener 是 envoy 最重要的配置,也是最复杂的配置,它是 envoy 的监听配置,指定了 envoy 监听地址,以及请求如何处理、转发到哪里。Listener 中可以包含多个不同 filter,有一些 filter 本身又是比较复杂的,可以继续包含 filter,譬如 HTTP Connection Manager。
Listener 配置格式
Listener 的配置格式如下,可以在 api 文档 中找到:
{
"name": "...",
"address": "{...}",
"filter_chains": [],
"use_original_dst": "{...}",
"per_connection_buffer_limit_bytes": "{...}",
"metadata": "{...}",
"drain_type": "...",
"listener_filters": [],
"listener_filters_timeout": "{...}",
"transparent": "{...}",
"freebind": "{...}",
"socket_options": [],
"tcp_fast_open_queue_length": "{...}",
"traffic_direction": "..."
}
其中 address 是监听地址,filter_chains 和 listener_filters 是 listener 中最重要也最复杂的配置,剩余的都是一些细节配置,相对简单一些。
注意事项:
- listener 的监听地址是互斥的,两个 listener 不能监听同一个 socket 地址
- listener_filters 是 listener filter
- filter_chains 是 network filter,可以有多组
go-control-plane 中的 listener 在 envoy/api/ve/lds.pb.go 中定义,每个字段都有非常详细的注释,api文档 就是通过这些注释生成的。
参考
视频讲解:Envoy手把手入门视频讲解
Envoy 的 Listener 中的 Filter 详解
从 socket 中收取的请求先经过 listener_filters 处理,然后再由 filter_chains 处理,前者包含的 filter 称为 listener filter,后者包含的 filter 称为 network filter。因为 listener_filters 先起作用,因此它可以修改请求的信息,从而影响 filter_chains 的匹配。
Filter 的文档在 Extensions 中,当前(2019-08-05 20:35:10)有以下几个大类:
Listener filters
Network filters
HTTP filters
Thrift filters
Common access log types
Common fault injection types
Dubbo filters
Configuration reference 中一半的篇幅在介绍 filter,对每个 filter 的用途和用法作了简要介绍。
参考
视频讲解:Envoy手把手入门视频讲解
go-control-plane 中的 filter 定义与下发
Filter 是填充在 listener 中作为 listener 配置下发的,listener 在 go-control-plane/envoy/api/v2/lds.pb.go 中定义,filter 的接口在 envoy/api/v2/listener/listener.pb.go 中定义,filter 的实现在 go-control-plane/envoy/config/filter/ 中。
listener_filters 的定义
Listener 中的 listener_filters 的在 go-control-plane 中定义如下:
// go-control-plane/envoy/api/v2/lds.pb.go
ListenerFilters []*listener.ListenerFilter
// go-control-plane/envoy/api/v2/listener/listener.pb.go
type ListenerFilter struct {
Name string
ConfigType isListenerFilter_ConfigType
XXX_NoUnkeyedLiteral struct{}
XXX_unrecognized []byte
XXX_sizecache int32
}
filter_chains 的定义
Listener 中的 filter_chains 在 go-control-plane 中定义如下,其中FilterChain 继续包含 Filter 链:
FilterChains []*listener.FilterChain
type FilterChain struct {
FilterChainMatch *FilterChainMatch
TlsContext *auth.DownstreamTlsContext
Filters []*Filter
UseProxyProto *types.BoolValue
Metadata *core.Metadata
TransportSocket *core.TransportSocket
XXX_NoUnkeyedLiteral struct{}
XXX_unrecognized []byte
XXX_sizecache int32
}
type Filter struct {
Name string `protobuf:"bytes,1,opt,name=name,proto3" json:"name,omitempty"`
ConfigType isFilter_ConfigType `protobuf_oneof:"config_type"`
XXX_NoUnkeyedLiteral struct{} `json:"-"`
XXX_unrecognized []byte `json:"-"`
XXX_sizecache int32 `json:"-"`
}
filter 的定义
filter 的定义在 go-control-plane/envoy/config/filter 中,不同类型的 filter 都有各自的定义。用 go-control-plane 下发时,需要用 util.MessageToStruct() 转换成 *types.Struct 类型,或者用 ptypes.MarshalAny() 转换成 * any.Any 类型后,填充到 Listener 中。
以 listener_filters 的为例,ListenerFilter 中的 ConfigType 是一个接口变量:
// go-control-plane/envoy/api/v2/listener/listener.pb.go
type ListenerFilter struct {
Name string
ConfigType isListenerFilter_ConfigType
XXX_NoUnkeyedLiteral struct{}
XXX_unrecognized []byte
XXX_sizecache int32
}
// go-control-plane/envoy/api/v2/listener/listener.pb.go: 585
type isListenerFilter_ConfigType interface {
isListenerFilter_ConfigType()
Equal(interface{}) bool
MarshalTo([]byte) (int, error)
Size() int
}
isListenerFilter_ConfigType 是一个很简单的接口,实现该接口的 struct 是 ListenerFilter_Config 和 ListenerFilter_TypedConfig 。
// go-control-plane/envoy/api/v2/listener/listener.pb.go: 592
type ListenerFilter_Config struct {
Config *types.Struct
}
type ListenerFilter_TypedConfig struct {
TypedConfig *types.Any
}
func (*ListenerFilter_Config) isListenerFilter_ConfigType() {}
func (*ListenerFilter_TypedConfig) isListenerFilter_ConfigType() {}
上面的 Config 和 TypedConfig 就是 filter 转化而成的。
filter_chains 的情况类似,对应的 struct 是 Filter_Config 和 Filter_TypedConfig。
XX_Config 和 XX_TypedConfig 的区别
将 filter 填充到 listener 时,可以用 XX_Config 类型,也可以用 XX_TypedConfig 的类型,区别如下:
XX_Config:
- name: envoy.http_connection_manager
config:
stat_prefix: ingress_http
generate_request_id: true
route_config:
name: local_route
virtual_hosts:
- name: local_service
domains: ["webshell.com"]
routes:
- match:
prefix: "/"
route:
host_rewrite: webshell.com
cluster: service_webshell
http_filters:
- name: envoy.router
config:
dynamic_stats: false
XX_TypedConfig:
- name: envoy.http_connection_manager
typed_config:
"@type": type.googleapis.com/envoy.config.filter.network.http_connection_manager.v2.HttpConnectionManager
stat_prefix: ingress_http
route_config:
name: local_route
virtual_hosts:
- name: local_service
domains: ["*"]
routes:
- match:
prefix: "/"
route:
host_rewrite: www.baidu.com
cluster: service_baidu
http_filters:
- name: envoy.router
HTTP Connection Manager 的填充过程
以 HTTP Connection Manager 为例,填充操作如下:
// 创建一个 HttpConnectionManager
listen_filter_http_conn_ := &http_conn_manager.HttpConnectionManager{
StatPrefix: "ingress_http",
RouteSpecifier: &http_conn_manager.HttpConnectionManager_RouteConfig{
RouteConfig: &api_v2.RouteConfiguration{
Name: "None",
VirtualHosts: virtualHosts,
},
},
HttpFilters: httpFilters,
}
// 转换成 *types.Struct
listen_filter_http_conn, err := util.MessageToStruct(listen_filter_http_conn_)
if err != nil {
glog.Error(err)
return
}
// 用转换得到 *types.Struct 构造 listener.Filter_Config,继而构造 Filter
filter := &listener.Filter{
Name: "envoy.http_connection_manager",
ConfigType: &listener.Filter_Config{
Config: listen_filter_http_conn,
},
}
//然后把 filter 放入 filterChains 的一个成员的 filters 链中。
filters = append(filters, filter)
filterChain := &listener.FilterChain{
Filters: filters,
}
//最后将 filterChains 装入 listener
filterChains = append(filterChains, filterChain)
lis := &api_v2.Listener{
Name: "listener_with_static_route_port_9000",
Address: address,
FilterChains: filterChains,
}
参考
视频讲解:Envoy手把手入门视频讲解
Envoy 的 listener filter 列表
下面是可以在加入 listener 的 listener_filter 字段中的 listener filter。 这些 filter 的主要作用是检测协议、解析协议,通过它们解析出的信息被用于匹配 filter_chains 中的 filter。
Envoy 支持的 listener_filter: listener filter。
name: envoy.listener.http_inspector
HTTP Inspector 判断应用层的数据是否使用 HTTP 协议,如果是,续继判断 HTTP 协议的版本号(HTTP 1.0、HTTP 1.1、HTTP 2),:
listener_filters:
- name: "envoy.listener.http_inspector"
typed_config: {}
name: envoy.listener.original_src
Original Source 用于透明代理,让 uptream 看到的是请求端的 IP,双方均感知不到 envoy 的存在。
Original Source 有点类似于 lvs 的 DR 模式 ,假设 downstream 的 IP 是 10.1.2.3,envoy 的 IP 是 10.2.2.3。envoy 将报文转发给 upstream 时复用 downstream 的源 IP,upstream 看到的源 IP 是 downstream 的 IP 10.1.2.3,不是 envoy 的 IP 10.2.2.3。
与 lvs 的 DR 模式 区别是,在 lvs 中,upsteram 是直接将回应包发送给 downstream,而 envoy 的文档中强调,必须通过配置网络环境,让 uptream 的回应包发送到 envoy ,再由 envoy 转发。
下面是一个使用示例,用到了两个 filter:第一个 filter 是 envoy.listener.proxy_protocol,用途是从代理协议中解析出真实的源 IP,详情见下一节; 第二个 filter 是 envoy.listener.original_src ,作用是透传源 IP。
listeners:
- address:
socket_address:
address: 0.0.0.0
port_value: 8888
listener_filters:
- name: envoy.listener.proxy_protocol
- name: envoy.listener.original_src
config:
mark: 123
mark 123 设置了被透传的报文需要打上的标记,当 upstream 和 envoy 位于同一台机器上时,将打了标记的报文转发到本地:
iptables -t mangle -I PREROUTING -m mark --mark 123 -j CONNMARK --save-mark
iptables -t mangle -I OUTPUT -m connmark --mark 123 -j CONNMARK --restore-mark
ip6tables -t mangle -I PREROUTING -m mark --mark 123 -j CONNMARK --save-mark
ip6tables -t mangle -I OUTPUT -m connmark --mark 123 -j CONNMARK --restore-mark
ip rule add fwmark 123 lookup 100
ip route add local 0.0.0.0/0 dev lo table 100
ip -6 rule add fwmark 123 lookup 100
ip -6 route add local ::/0 dev lo table 100
echo 1 > /proc/sys/net/ipv4/conf/eth0/route_localnet
上面的设置规则用到一个 linux 知识: local 地址的认定。
如果 envoy 和 upstream 不在同一个 host,需要通过调整网络环境使回应包回到 envoy。
name: envoy.listener.original_dst
Original Destination 用来读取 socket 的配置项 SO_ORIGINAL_DST,在使用 透明代理模式 时用到,在 envoy 中,用该 filter 获取报文的原始目地地址:
listener_filters:
- name: "envoy.listener.original_dst"
name: envoy.listener.proxy_protocol
Proxy Protocol 解析代理协议,用该 filter 可以解析出真实的源 IP,已知支持 HAProxy Proxy Protocol(2019-08-09 18:08:01):
listener_filters:
- name: envoy.listener.proxy_protocol
name: envoy.listener.tls_inspector
TLS Inspector 用来判断是否使用 TLS 协议,如果是 TLS 协议,解析出 Server Name、Negotiation 信息,解析出来的信息用于 FilterChain 的匹配。
listener_filters:
- name: "envoy.listener.tls_inspector"
typed_config: {}
参考
视频讲解:Envoy手把手入门视频讲解
Envoy 的 network filter 列表
可以加入到 filter_chains 中的 network filter 数量众多,Network filters 中列出了以下几个:
Dubbo proxy
Client TLS authentication
Echo
External Authorization
Mongo proxy
MySQL proxy
Rate limit
Role Based Access Control (RBAC) Network Filter
Redis proxy
TCP proxy
Thrift proxy
Upstream Cluster from SNI
ZooKeeper proxy
另还有一个名为 HTTP connection manager 的 network filter,这个 filter 主要处理 http 协议,自身已经足够复杂,被单独列出 HTTP connection manager。
HTTP connection manager、Thrift proxy 和 Dubbo proxy 还有在自己内部使用的 filter,分别是: HTTP filters、Thrift filters、Dubbo filters。
envoy.tcp_proxy
TCP proxy 是四层 tcp 代理,管理 downstream client 与 upstream cluster 之间的 tcp 连接,保证连接数不超过 upstream cluster 的上限。
envoy.ratelimit
Rate limit 提供全局限速功能(需要连接外部的限速服务),可以限制 tcp 连接速率和 http 请求速率。为了避免每个连接、或者每个请求都查询限速服务,可以设置限速服务的查询占比:
ratelimit.tcp_filter_enabled # 对应比例的连接会查询限速服务,但不执行查询结果
ratelimit.tcp_filter_enforcing # 对应比例的连接会查询限速服务,并按照查询结果执行
envoy.filters.network.rbac
Role Based Access Control (RBAC) Network Filter 提供了访问控制的能力。
envoy.client_ssl_auth
Client TLS authentication 验证 client 端的证书,它会以配置的频率调用 GET /v1/certs/list/approved 获取最新的有效证书。
envoy.ext_authz
External Authorization 通过外部的认证服务判断当前请求是否获得授权,如果没有授权,关闭连接。
filters:
- name: envoy.ext_authz
config:
stat_prefix: ext_authz
grpc_service:
envoy_grpc:
cluster_name: ext-authz
clusters:
- name: ext-authz
type: static
http2_protocol_options: {}
load_assignment:
cluster_name: ext-authz
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: 127.0.0.1
port_value: 10003
envoy.echo
Echo 将收到的数据原样返回给客户端。
envoy.http_connection_manager
HTTP connection manager 是专门处理 http 协议的 network filter,因为 http 最经常使用的协议,对代理功能需求也非常多样, HTTP connection manager 本身是一个比较复杂的 network filter,在 envoy 文档中被单独列出:HTTP connection manager。
HTTP connection manager 有自己专用的 HTTP filters,在 http filters 中单独介绍。
envoy.filters.network.thrift_proxy
Thrift proxy 能够解析 thrift 协议。
Thrift proxy 有自己专用的 Thrift filters。
envoy.filters.network.dubbo_proxy
Dubbo proxy 解析 dubbo client 和 service 之间的 grpc 通信。
Dubbo proxy 有自己专用的 Dubbo filters。
filter_chains:
- filters:
- name: envoy.filters.network.dubbo_proxy
config:
stat_prefix: dubbo_incomming_stats
protocol_type: Dubbo
serialization_type: Hessian2
route_config:
name: local_route
interface: org.apache.dubbo.demo.DemoService
routes:
- match:
method:
name:
exact: sayHello
route:
cluster: user_service_dubbo_server
dubbo_filters:
- name: envoy.filters.dubbo.testFilter
config:
"@type": type.googleapis.com/google.protobuf.Struct
value:
name: test_service
- name: envoy.filters.dubbo.router
envoy.filters.network.zookeeper_proxy
ZooKeeper proxy 能够解析 zookeeper 协议。
envoy.mongo_proxy
Mongo proxy 能够解析 mongo 通信,记录 mongo 日志、统计、注入错误等。
envoy.filters.network.mysql_proxy
MySQL proxy 能够解析 mysql 的通信协议,需要和 [TCP proxy][] 一起使用:
filter_chains:
- filters:
- name: envoy.filters.network.mysql_proxy
typed_config:
"@type": type.googleapis.com/envoy.config.filter.network.mysql_proxy.v1alpha1.MySQLProxy
stat_prefix: mysql
- name: envoy.tcp_proxy
typed_config:
"@type": type.googleapis.com/envoy.config.filter.network.tcp_proxy.v2.TcpProxy
stat_prefix: tcp
cluster: ...
envoy.redis_proxy
Redis proxy 能够解析 redis 协议,使 envoy 成为 redis 代理,可以将不同的 redis command 代理到不同 redis cluster。
参考
视频讲解:Envoy手把手入门视频讲解
http_connection_manager 中的 http filter
http_connection_manager 是一个比较复杂的 network filter,它内部又实现了 http filter,支持的 filter 数量较多,这里不一一列举,可以到 HTTP filters 查看,官方文档比较详细。
envoy.router
envoy.router 的插件名称就是 envoy.router:
httpFilter := &http_conn_manager.HttpFilter{
Name: "envoy.router",
ConfigType: &http_conn_manager.HttpFilter_Config{
Config: http_filter_router,
},
}
或者:
"http_filters": [
{
"name": "envoy.router",
"config": {
"dynamic_stats": false
}
}
],
需要注意的是 envoy.router 只是设置重试次数之类的配置项,转发规则配置直接隶属于 http_connection_manager ,不是独立的 filter:

参考
视频讲解:Envoy手把手入门视频讲解
Envoy 4 层 TCP/UDP 协议转发
4 层协议现在只支持 tcp,udp 协议的支持还在设计开发中 UDP proxying support。
Envoy 的 4 层代理转发通过名为 envoy.tcp_proxy 的 network filter 完成,该 filter 的定义见 TCP Proxy configuration overview。
envoy tcp 转发示例
监听 81 端口,将到达该端口的 tcp 报文转发给 echo_cluster,示例配置文件为 envoy-to-tcp.yaml:
...省略...
static_resources:
listeners:
- name: listener_0
address:
socket_address:
protocol: TCP
address: 0.0.0.0
port_value: 81
filter_chains:
- filters:
- name: envoy.tcp_proxy
config:
stat_prefix: tcp_proxy_81
cluster: echo_tcp_80
clusters:
- name: echo_tcp_80
connect_timeout: 0.25s
type: STATIC
lb_policy: ROUND_ROBIN
#http2_protocol_options: {} #echoserver不支持http 2.0
load_assignment:
cluster_name: service_echo
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: 172.17.0.2
port_value: 8080
注意使用的 filter 名称为 “envoy.tcp_proxy”,运行效果如下:
$ ./run.sh envoy-to-tcp.yaml
$ curl 127.0.0.1:81
Hostname: 7759cabd7402
Pod Information:
-no pod information available-
... 省略...
tcp_proxy 还支持 weighted_clusters,可以设置 access_log,详情见 TCP Proxy configuration overview。
参考
视频讲解:Envoy手把手入门视频讲解
Envoy 使用过程中的常见问题
这里是 Envoy 使用过程中常遇到的问题。
Listener 的端口不可以重复
如果为两个 listener 配置了相同的监听端口,后一个 listener 会失败:
[2019-09-19 08:38:17.655][1][info][main] [source/server/server.cc:516] starting main dispatch loop
[2019-09-19 08:38:17.664][1][critical][config] [source/server/listener_manager_impl.cc:684] listener 'listener_1' failed to listen on address '0.0.0.0:81' on worker
listener 的监听端口不能重复。
Route 的域名不能重复
Http 路由中的域名不能重复,如果两个 Route 中配置了相同的域名,或者一个 Route 中配置了两个相同的域名,那么配置会下发失败,envoy 打印下面的日志:
[2019-09-10 08:41:35.917][1][warning][config] [source/common/config/grpc_mux_subscription_impl.cc:72] gRPC config for type.googleapis.com/envoy.api.v2.Listener rejected: Error adding/updating listener(s) TCP-80: Only unique values for domains are permitted. Duplicate entry of domain echo.example
[2019-09-10 08:41:35.919][1][warning][config] [source/common/config/grpc_mux_subscription_impl.cc:72] gRPC config for type.googleapis.com/envoy.api.v2.Listener rejected: Error adding/updating listener(s) TCP-80: Only unique values for domains are permitted. Duplicate entry of domain echo.example
[2019-09-10 08:41:35.921][1][warning][config] [source/common/config/grpc_mux_subscription_impl.cc:72] gRPC config for type.googleapis.com/envoy.api.v2.Listener rejected: Error adding/updating listener(s) TCP-80: Only unique values for domains are permitted. Duplicate entry of domain echo.example
[2019-09-10 08:41:35.922][1][warning][config] [source/common/config/grpc_mux_subscription_impl.cc:72] gRPC config for type.googleapis.com/envoy.api.v2.Listener rejected: Error adding/updating listener(s) TCP-80: Only unique values for domains are permitted. Duplicate entry of domain echo.example
Route 的 Prefix 可以重复
Route 的 Prefix 可以重复,试验结果表明排在前面的 Prefix 被采用,下面的例子前缀为 /abc 的请求被转发到 STD@kube-cluster-1@demo-webshell@webshell@80 :
"routes": [
{
"route": {
"cluster": "STD@kube-cluster-1@demo-webshell@webshell@80",
"host_rewrite": "envoy.echo.example"
},
"match": {
"case_sensitive": false,
"prefix": "/abc"
}
},
{
"route": {
"cluster": "STD@kube-cluster-1@demo-echo@echo@8080",
"host_rewrite": "envoy.echo.example"
},
"match": {
"prefix": "/abc",
"case_sensitive": false
}
}
],
参考
Nginx 学习资料
OpenResty 作者章宜春有一个 agentzh 的 Nginx 教程(版本 2016.07.21),不过这个教程没写完, 可以用来培养感性认识,中文阅读起来方便一些。OpenResty 最佳实践中有一章是关于 nginx 的,相对比较适合用来入门,并且指出了一些坑。
最权威最完整的是 nginx 官方的文档,可能不太适合入门,适合作为查询手册:
- 新手手册: Nginx beginner's guide
- 指令手册:Alphabetical index of directives,列出了nginx的所有指令,按照字母顺序排序。
- 变量手册:Alphabetical index of variables,列出了nginx的所有变量,按照字母顺序。
- 全局手册:Nginx documentation,nginx官方文档的首页,列出了nginx自带的所有module。
- 源代码: Nginx source code
参考
Nginx 学习使用的试验环境
在 mac 上安装 nginx :
$ brew install nginx
Docroot is: /usr/local/var/www
The default port has been set in /usr/local/etc/nginx/nginx.conf to 8080 so that
nginx can run without sudo.
nginx will load all files in /usr/local/etc/nginx/servers/.
To have launchd start nginx now and restart at login:
brew services start nginx
Or, if you do nott want/need a background service you can just run:
nginx
==> Summary
🍺 /usr/local/Cellar/nginx/1.17.3_1: 25 files, 2MB
mac 上的 nginx 的配置文件为:/usr/local/etc/nginx/nginx.conf
server 配置的放置目录:/usr/local/etc/nginx/servers/
验证 nginx
启动:
$ brew services start nginx
查看状态:
$ brew services list
Name Status User Plist
nginx started lijiao /Users/lijiao/Library/LaunchAgents/homebrew.mxcl.nginx.plist
访问:
$ curl 127.0.0.1:8080
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...
停止:
$ brew services stop nginx
验证代理功能
在本地启动一个 echoserver 服务:
docker run -idt --name echoserver -p 9090:8080 -p 9443:8443 googlecontainer/echoserver:1.10
执行:
./start_echoserver.sh
创建配置文件,echo.example.conf:
upstream echo_upstream{
server 127.0.0.1:9090;
keepalive 1;
}
server {
listen 9000;
listen [::]:9000;
server_name echo.example;
keepalive_requests 2000;
keepalive_timeout 60s;
location / {
proxy_pass http://echo_upstream;
proxy_http_version 1.1;
proxy_set_header Connection "";
}
}
连接到 /usr/local/etc/nginx/servers/ 目录中:
./link.sh echo.example.conf
验证配置:
/usr/local/bin/nginx -c /usr/local/etc/nginx/nginx.conf
重启 nginx 后,访问:
$ curl -H "Host: echo.example" 127.0.0.1:9000
Hostname: 12a852d64212
Pod Information:
-no pod information available-
Server values:
server_version=nginx: 1.13.3 - lua: 10008
参考
Nginx 配置文件格式
Nginx 的源代码中有个配置文件 nginx.conf 样例,CentOS 安装的 nginx 自带的默认配置文件结构更好。
CentOS 的 nginx 配置文件组织方式
mac 上的 nginx 的配置文件组织方式和 CentOS 类似,配置文件位于 /usr/local/etc/nginx/nginx.conf
用 yum 命令在 CentOS 中安装 nginx 的,默认使用的配置文件是 /etc/nginx/nginx.conf:
# For more information on configuration, see:
# * Official English Documentation: http://nginx.org/en/docs/
# * Official Russian Documentation: http://nginx.org/ru/docs/
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
# Load dynamic modules. See /usr/share/nginx/README.dynamic.
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 1024;
}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
include /etc/nginx/mime.types;
default_type application/octet-stream;
# Load modular configuration files from the /etc/nginx/conf.d directory.
# See http://nginx.org/en/docs/ngx_core_module.html#include
# for more information.
include /etc/nginx/conf.d/*.conf;
# 默认的server
server {
listen 80 default_server;
listen [::]:80 default_server;
server_name _;
root /usr/share/nginx/html;
# 默认server的配置也写到单独的配置文件中
# Load configuration files for the default server block.
include /etc/nginx/default.d/*.conf;
location / {
}
error_page 404 /404.html;
location = /40x.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}
# TLS 配置方法
# Settings for a TLS enabled server.
server {
listen 443 ssl http2 default_server;
listen [::]:443 ssl http2 default_server;
server_name _;
root /usr/share/nginx/html;
ssl_certificate "/etc/pki/nginx/server.crt";
ssl_certificate_key "/etc/pki/nginx/private/server.key";
ssl_session_cache shared:SSL:1m;
ssl_session_timeout 10m;
ssl_ciphers HIGH:!aNULL:!MD5;
ssl_prefer_server_ciphers on;
# Load configuration files for the default server block.
include /etc/nginx/default.d/*.conf;
location / {
}
error_page 404 /404.html;
location = /40x.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}
}
上面的配置文件中有两个 include 指令需要特别注意,这两个指令又引入了其它的配置文件,它们分别加载了 Nginx 模块和 Server 配置。
第一个 include:加载 nginx 模块
第一个 include 指令是导入 nginx 模块的加载指令:
# Load dynamic modules. See /usr/share/nginx/README.dynamic.
include /usr/share/nginx/modules/*.conf;
在 /usr/share/nginx/modules 目录中有多个配置文件,每个配置文件用来加载一个 nginx 模块:
$ ls /usr/share/nginx/modules/
mod-http-geoip.conf mod-http-image-filter.conf mod-http-perl.conf
mod-http-xslt-filter.conf mod-mail.conf mod-stream.conf
以 mod-http-geoip.conf 为例,模块的加载命令如下:
load_module "/usr/lib64/nginx/modules/ngx_http_geoip_module.so";
第一个 include:加载 server 配置
第二个 include 加载 server 配置:
include /etc/nginx/conf.d/*.conf;
Nginx 是一个代理服务器,它可以同时代理多个后端服务,将这些后端服务的配置写到各自的单独的配置文件中,可以简化配置文件并且方便管理。
比如说 /etc/nginx/conf.d/flarum.conf 中全都是 flarum.local 服务相关的配置:
server {
listen 80 ;
listen [::]:80 ;
server_name flarum.local; # 在本地 host 配置域名
root /vagrant/flarum/2_flarum/project; # 这里是 composer 安装的 flarum 项目目录
location / { try_files $uri $uri/ /index.php?$query_string; }
location /api { try_files $uri $uri/ /api.php?$query_string; }
location /admin { try_files $uri $uri/ /admin.php?$query_string; }
location /flarum {
deny all;
return 404;
}
location ~* \.php$ {
fastcgi_split_path_info ^(.+.php)(/.+)$;
fastcgi_pass 127.0.0.1:9000;
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_param HTTP_PROXY ""; # Fix for https://httpoxy.org/ vulnerability
fastcgi_index index.php;
}
#...省略部分内容...
gzip on;
gzip_http_version 1.1;
gzip_vary on;
}
API 网关 kong 的配置文件组织方式
Kong 是基于 OpenResty 实现的 API 网关,OpenResty 基于 nginx,kong 使用的 nginx.conf 如下:
worker_processes auto;
daemon off;
pid pids/nginx.pid;
error_log logs/error.log debug;
worker_rlimit_nofile 1024;
events {
worker_connections 1024;
multi_accept on;
}
http {
# kong的配置单独写入到另一个配置文件中
include 'nginx-kong.conf';
}
参考
Nginx 的常用配置
一些常用的 nginx 配置。
日志
设置错误日志文件和日志级别,一般在配置文件最开始处配置:
error_log /tmp/logs/error.log info;
日志格式 log_format 分为 http log_format 和 stream log_format,两者的格式中可以使用的变量不同。
紧跟在 log_format 后面的字符串是日志格式的名称,nginx 支持定义多个格式,以 http log_format 为例:
# 格式名称为 main
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
http 的日志格式中可以添加任意的 http 头,例如上面的 $http_user_agent。
日志格式只用于访问日志,用 access_log 引用引用,access_log 同样分为 http access_log 和 stream access_log。http 的 access_log 可以在 location 中单独设置。
使用效果,在 http 中定义 tranproxy:
http{
...省略...
log_format tranproxy '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
...省略...
}
在 location 中引用:
location / {
access_log /var/log/nginx/access.80.log tranproxy;
... 省略 ...
}
访问日志,不带 -H X-Forwarded-For 时:
172.17.0.5 - - [14/Nov/2019:03:12:15 +0000] "GET / HTTP/1.1" 200 467 "-" "curl/7.61.1" "-"
访问日志,带有 -H X-Forwarded-For 时:
172.17.0.5 - - [14/Nov/2019:03:12:15 +0000] "GET / HTTP/1.1" 200 467 "-" "curl/7.61.1" "127.0.0.1"
location 的匹配规则
location 是最常用的,支持四个修饰符: =、~、 ~*、^~。
=: 严格一致~: 区分大小写的正则匹配~*: 不区分大小写的正则匹配^~: 前缀匹配成功后,忽略正则匹配
正则表达式语法参考 man 7 regex,下面的表达式匹配以 /detail 开头且不含有 . 路径:
location ~ '^/detail/[^.]*$ {
...省略...
}
参考
Nginx 性能优化时需要考虑的配置
做压测时了解到一些配置,在这里记录一下。调整的参数如下:
# 这不是一个完整的配置文件
worker_processes 2;
worker_cpu_affinity 0010 1000;
worker_rlimit_nofile 10340;
worker_priority -20;
events {
worker_connections 10240;
worker_aio_requests 32;
}
http{
...
upstream webshell_upstream{
keepalive 16;
keepalive_timeout 60s; # nginx 1.15.3
}
...
server {
...
keepalive_requests 10000000;
location / {
...
proxy_socket_keepalive on;
proxy_connect_timeout 60s; # nginx 1.15.6
proxy_send_timeout 60s;
proxy_read_timeout 60s;
proxy_http_version 1.1;
proxy_set_header Connection "";
}
}
}
Core functionality
Core functionality 包含 nginx 的核心参数,与性能直接相关的有:
- worker_processes:nginx 工作进程的数量,默认是
auto - worker_cpu_affinity:nginx工作进程绑定到指定的CPU核
- worker_rlimit_nofile:单个nginx worker可以打开的文件数,影响 nginx worker 建立的连接数量
- worker_priority:nginx worker 进程在系统中的优先级,
-20~+20,-20是最高优先级 - worker_connections:单个 nginx worker 可以建立的连接数量,
不能高于worker_rlimit_nofile。
Module ngx_http_proxy_module
Module ngx_http_proxy_module 包含代理相关设置,与性能直接相关的有:
- proxy_http_version:nginx 到 upstream 中的 server 时使用的协议,默认是 http,不会建立长连接。设置成 http 1.1 ,用 proxy_set_header 将
Connection头去掉后,会启用长连接,性能显著提升。
Module ngx_http_upstream_module
Module ngx_http_upstream_module 包含 upstream 相关的参数,其中与性能直接相关的有:
-
keepalive :单个 worker 可以与 backend server 保持的空闲连接数。如果这个数值过小,nginx worker 会不停地与 backend server 新建连接、关闭连接。
-
keepalive_timeout:
1.15.3中开始有的参数,设置 nginx worker 与 backend server 的空闲的连接保持时间。早期版本中没有这个参数,长连接是一直保持(可以用 keepalive_requests 的参数避免)。 -
keepalive_requests:设置 nginx worker 与 backend server 建立的长连接中可以传输的请求数,超过后连接被 nginx 主动关闭。
关于长连接的设置可以参考:Enable Keepalive connections in Nginx Upstream proxy configurations和TCP keepalive overview。
参考
Nginx 使用注意事项
一些重要摘要
提前了解这些,可以避免踩坑:
Nginx 新手起步中给出的一个数据比较重要:
一般的情况下,10000 个非活跃的 HTTP Keep-Alive 连接在 Nginx 中仅消耗 2.5MB 的内存
if 是邪恶的,慎用if,如果非要用,最好只在if中使用下面的命令:
在 location 区块里 if 指令下唯一 100% 安全的指令应该只有:
return …; rewrite … last;
参考
Nginx 的状态数据
stub_status
Nginx 的 stub_status 指令用来显示 nginx 的工作状态,配置方式如下:
location = /nginx_status {
allow 127.0.0.1;
deny all;
stub_status on; # 开启状态
access_log off; # 不记录该 uri 的访问日志
}
效果:
$ curl 127.0.0.1:9000/nginx_status
Active connections: 1
server accepts handled requests
3 3 3
Reading: 0 Writing: 1 Waiting: 0
stub_status 给出了各个参数含义:
Active connections :活跃连接数
accepts :接收的连接总数
handled :已经处理的连接数
requests :客户端请求总数
Reading :nginx 正在从其中读取 header 的连接数
Writing :nginx 正在向客户端发送响应数据的连接数
Waiting :idle 状态的连接
同时提供了以下可用变量:
$connections_active
same as the Active connections value;
$connections_reading
same as the Reading value;
$connections_writing
same as the Writing value;
$connections_waiting
same as the Waiting value.
参考
Nginx 请求复制功能
Nginx 1.13.4 引入了 ngx_http_mirror_module,实现了 http 请求复制的功能。
准备接收复制请求的服务
启动两个容器一个正常处理请求,一个接收复制到请求:
docker rm -f echoserver
docker run -idt --name echoserver -p 9090:8080 googlecontainer/echoserver:1.10
docker rm -f http-record
docker run -idt --name http-record -p 9091:8080 lijiaocn/http-record:0.0.1
执行:
./start_backends.sh
配置请求复制
在 nginx 的配置文件中,配置镜像复制,参考 ngx_http_mirror_module。
upstream echo_upstream{
server 127.0.0.1:9090;
keepalive 1;
}
upstream http-record_upstream{
server 127.0.0.1:9091;
keepalive 1;
}
server {
listen 9000;
listen [::]:9000;
server_name echo.example;
keepalive_requests 2000;
keepalive_timeout 60s;
location / {
mirror /mirror;
proxy_pass http://echo_upstream;
proxy_http_version 1.1;
proxy_set_header Connection "";
}
location = /mirror {
internal;
proxy_pass http://http-record_upstream$request_uri;
}
}
所有发送到 echo.example 的请求将被复制一份到 http-record,请求端收到的是 echo_upstream 的回应,http-record_upstream 的回应将被忽略。
复制效果
发起请求,收到的是 echo 的回应:
$ curl -H "Host: echo.example" 127.0.0.1:9000/abcd/eft
Hostname: 57e34b409aa1
Pod Information:
-no pod information available-
Server values:
server_version=nginx: 1.13.3 - lua: 10008
Request Information:
client_address=172.17.0.1
method=GET
real path=/abcd/eft
query=
request_version=1.1
request_scheme=http
request_uri=http://echo_upstream:8080/abcd/eft
Request Headers:
accept=*/*
host=echo_upstream
user-agent=curl/7.54.0
Request Body:
-no body in request-
查看 http-record 容器的日志,会发现收到了完全相同的请求:
/go/src/Server/echo.go:46: {
"RemoteAddr": "172.17.0.1:46856",
"Method": "GET",
"Host": "http-record_upstream",
"RequestURI": "/abcd/eft",
"Header": {
"Accept": [
"*/*"
],
"Connection": [
"close"
],
"User-Agent": [
"curl/7.54.0"
]
},
"Body": ""
}
配置修正
仔细观察上面的配置 Host 是 http-record_upstream,不是原始的 host。将配置修正为:
location / {
access_log /tmp/logs/access.log mirror;
mirror /mirror;
# 添加这行配置
set $proxy_host $host;
proxy_http_version 1.1;
proxy_set_header Connection "";
proxy_pass http://echo_upstream;
}
结合 split_clients 实现请求的部分复制
用于 A/B 测试的 split_clients 指令和 mirror 指令配合,可以实现请求的按比例复制,split_clients 的用法见 Nginx的A/B测试功能。
将 50% 的流量复制到复制到 record_upstream:
split_clients "$date_gmt" $mirror_servers {
50% record_upstream;
* "";
}
server {
listen 9000;
server_name echo.example;
keepalive_requests 1000;
keepalive_timeout 60s;
location / {
access_log /tmp/nginx_access.log mirror;
mirror /mirror;
proxy_pass http://echo_upstream;
proxy_http_version 1.1;
proxy_set_header Connection "";
}
location = /mirror {
internal;
access_log /tmp/nginx_mirror_access.log mirror;
if ($mirror_servers) {
proxy_pass http://$mirror_servers$request_uri;
}
}
}
mirror_servers 也可以是域名,域名需要指定 dns nameserver:
...省略...
split_clients "$date_gmt" $mirror_servers {
# 50% record_upstream;
100% local.lijiaocn.com:9091;
* "";
}
...省略...
location = /mirror {
internal;
access_log off;
#access_log /tmp/nginx_mirror_access.log mirror;
resolver 114.114.114.114;
if ($mirror_servers) {
set $proxy_host $host;
proxy_pass http://$mirror_servers$request_uri;
}
}
...省略...
参考
Nginx 的 A/B 测试功能
Nginx 的有一个 ngx_http_split_clients_module 模块,可以用来实现 A/B 测试。
split_clients 使用方法
split_clients 指令的用途是根据设定条件设置变量的值,如下,定义了一个名为 selected_upstream 的变量:
split_clients "$date_gmt" $selected_upstream {
50% echo_upstream;
50% record_upstream;
}
第二个参数是 MurmurHash2 哈希算法的输入,可以使用 ngxin 变量,50% 是区间划分。上面的配置中,哈希输入是 date_gmt,变量 selected_upstream 的值 50% 的可能是 echo_upstream,50% 的可能是 record_upstream。
selected_upstream 的取值是按照指定配置变换的,可以用来实现一些特殊效果,例如下面的配置,请求会按照时间情况在两个 upstream(echo_upstream 和 record_upstream)之间分配。
upstream echo_upstream {
server 127.0.0.1:9090;
keepalive 1;
}
upstream record_upstream {
server 127.0.0.1:9091;
keepalive 1;
}
split_clients "$date_gmt" $selected_upstream {
50% echo_upstream;
50% record_upstream;
}
server {
listen 9000;
server_name echo.example;
keepalive_requests 1000;
keepalive_timeout 60s;
location / {
proxy_pass http://$selected_upstream;
proxy_http_version 1.1;
proxy_set_header Connection "";
}
}
参考
使用 nginx 实现本地透明代理
尝试用 nginx 作为透明代理,修改报文头。
准备目标服务
目标服务是 试验环境 中启动的 echoserver,监听地址为 127.0.0.1:9090。
为目标服务准备一个域名 echo.example,用本地的 dnsmasq 解析,设置方法见 dnsmasq。
配置 nginx
配置nginx:
server {
listen 9000;
listen [::]:9000;
keepalive_requests 2000;
keepalive_timeout 60s;
location / {
resolver 127.0.0.1:8053; # 必须配置域名服务器
# 这里因为 nginx 和 目标服务在同一台机器上,使用了不同端口,所以写成 $host:9090
# 如果位于不同机器上,写成:proxy_pass http://$host:9000$request_uri;
proxy_pass http://$host:9090$request_uri;
proxy_set_header tranproxy "true";
}
}
通过 127.0.0.1:9000 端口访问,可以看到返回的请求头中多了 tranproxy=true:
$ curl -H "Host: echo.example" 127.0.0.1:9000
Hostname: 57e34b409aa1
Pod Information:
-no pod information available-
Server values:
server_version=nginx: 1.13.3 - lua: 10008
Request Information:
client_address=172.17.0.1
method=GET
real path=/
query=
request_version=1
request_scheme=http
request_uri=http://echo.example:8080/
Request Headers:
accept=*/*
connection=close
host=echo.example:9090
tranproxy=true
user-agent=curl/7.54.0
Request Body:
-no body in request-
实现无感知的本地透明代理
上面的测试因为环境限制,只是验证了透传的功能,这里研究一下怎样实现完全无感知本地 http 透明代理。
目标服务端口为 8080,在请求端设置 nginx,使本地发出的对 8080 端口的访问都经过本地 nginx 代理。
本地 nginx 的配置如下:
server {
listen 8080;
location / {
resolver 114.114.114.114;
proxy_pass http://$host:8080$request_uri;
proxy_set_header tranproxy "true"; # 为了验证代理效果,添加了一个请求头
}
}
接下来的关键问题是:怎样将本地发出的到 8080 端口的请求经过 nginx 送出,并且是在客户端无感知的情况下。
借鉴 istio 的做法,用 iptables 实现,istio 中的 envoy 同时代理流入的请求和流出的请求,我们这里只实现本地的代理,因此只需要设置 outbound 规则。
在 nat 表中添加一条规则链,存放本地代理的规则:
# 新建一个规则链
iptables -t nat -N LOCAL_PROXY
# 不代理 nginx 生成的报文,防止出现 nginx 代理 nginx 的死循环
iptables -t nat -A LOCAL_PROXY -m owner --uid-owner nginx -j RETURN
# 将本地生成的目标端口为 8080 的 tcp 报文,重定向到本地的 :8080 监听地址
iptables -t nat -A LOCAL_PROXY -p tcp -m tcp --dport 8080 -j REDIRECT --to-ports 8080
启用 LOCAL_PROXY:
iptables -t nat -A OUTPUT -p tcp -j LOCAL_PROXY
然后在本地直接访问目标服务,会发现请求头中多了 tranproxy=true:
$ curl 172.17.0.21:8080
Hostname: echo-597d89dcd9-m84tq
Pod Information:
-no pod information available-
Server values:
server_version=nginx: 1.13.3 - lua: 10008
Request Information:
client_address=172.17.0.28
method=GET
real path=/
query=
request_version=1
request_uri=http://172.17.0.21:8080/
Request Headers:
accept=*/*
connection=close
host=172.17.0.21:8080
tranproxy=true
user-agent=curl/7.61.1
上面的操作过程已经打包成了镜像,可以直接使用:
docker run -itd --cap-add NET_ADMIN --name nginx-tranproxy lijiaocn/nginx-tranproxy:0.1 \
-P 80 \
-P 8080 \
-H tranproxy:true \
-H tranproxy2:true \
-N 114.114.114.114 \
-N 8.8.8.8 \
--Set-Forwarded-For default \
--Set-Client-Hostname default \
-- tail -f /dev/null
在 kubernetes 中使用:
kubectl -n "Your NameSpace" create -f https://raw.githubusercontent.com/introclass/kubernetes-yamls/master/all-in-one/nginx-tranproxy.yaml
参考
OpenResty 学习笔记
这里是对 OpenResty 相关笔记的重新整理,原笔记不再维护。
OpenResty 是什么?见 Nginx、OpenResty 和 Kong入门。
学习资料
OpenResty 最佳实践 是一份很好的学习资料。
OpenResty 在 nginx 的基础上改造加强,提供的开发语言是 lua,用 lua-nginx-module 解释 lua 脚本,从下面的文档中几乎可以找到所有用法:
- lua 语言用法:Lua编程速查手册(常用操作)
- nginx 指令汇总:nginx directives
- nginx 变量汇总:nginx variables
- openresty 提供的 lua 能力:openresty/lua-nginx-module
- openresty 集成的模块和 lua 库:openresty components
以前的笔记:
- 《Web开发平台OpenResty(一):学习资料、基本组成与使用方法》
- 《Web开发平台OpenResty(二):组成、工作过程与原理》
- 《Web开发平台OpenResty(三):火焰图性能分析》
- 《Web开发平台OpenResty(四):项目开发中常用的操作》
- 《Web开发平台OpenResty(五):OpenResty项目自身的编译》
参考
OpenResty 环境准备
mac 上的安装方法
brew untap homebrew/nginx
brew install openresty/brew/openresty
执行:
./install-on-mac.sh
环境验证
准备 openresty 的配置文件,01-hello-world/nginx.conf:
worker_processes 1; #nginx worker 数量
error_log logs/error.log; #指定错误日志文件路径
events {
worker_connections 1024;
}
http {
server {
#监听端口,若你的6699端口已经被占用,则需要修改
listen 6699;
location /a {
default_type text/html;
content_by_lua_block {
ngx.say("HelloWorld")
}
}
}
}
用该配置文件启动:
openresty -p `pwd` -c nginx.conf
访问:
$ curl 127.0.0.1:6699/a
HelloWorld
resty 验证
OpenResty 提供一个 resty 命令,可以直接解释执行 lua 脚本,准备一个 lua 脚本 hello.lua:
#! /usr/bin/env lua
--
-- hello.lua
-- Copyright (C) 2018 lijiaocn <[email protected]>
--
-- Distributed under terms of the GPL license.
--
mysql=require "resty.mysql"
ngx.say("hello world")
用 resty 执行 lua 脚本:
$ resty hello.lua
hello world
参考
OpenResty 中 lua 脚本的使用
OpenResty 用 lua-nginx-module 解释 lua 脚本,lua 语言自身的用法见 Lua编程速查手册(常用操作),openresty 提供的 lua 能力(譬如定义的变量、提供的函数等)见 openresty/lua-nginx-module 。
OpenResty 执行 Lua 脚本
OpenResty 支持的开发语言是 lua,lua 脚本可以用两种方式运行:
第一种方式,直接写在配置文件中,openresty 加载运行:
$ cd 01-hello-world
$ openresty -p `pwd` -c nginx.conf
这种方式启动了 openresty 服务,访问 openresty 时触发配置中的 lua 脚本的运行:
$ curl 127.0.0.1:6699/
HelloWorld
第二种方式,用 resty 命令直接执行 lua 脚本:
$ cd 02-hello-world
$ resty hello.lua
hello world
lua_module 的几个执行阶段
lua_module 定义了很多的指令,lua module directives,其中有一些指令是类似于 server、location 的块指令,它们的作用顺序如下:

用下面的配置观察这些指令的执行顺序,03-nginx-lua-module/nginx.conf:
worker_processes 1; #nginx worker 数量
error_log logs/error.log info; #指定错误日志文件路径
events {
worker_connections 256;
}
http {
server {
#监听端口,若你的6699端口已经被占用,则需要修改
listen 6699;
location / {
set_by_lua_block $a {
ngx.log(ngx.INFO, "set_by_lua*")
}
rewrite_by_lua_block {
ngx.log(ngx.INFO, "rewrite_by_lua*")
}
access_by_lua_block {
ngx.log(ngx.INFO, "access_by_lua*")
}
content_by_lua_block {
ngx.log(ngx.INFO, "content_by_lua*")
}
header_filter_by_lua_block {
ngx.log(ngx.INFO, "header_filter_by_lua*")
}
body_filter_by_lua_block {
ngx.log(ngx.INFO, "body_filter_by_lua*")
}
log_by_lua_block {
ngx.log(ngx.INFO, "log_by_lua*")
}
}
}
}
执行时打印的日志:
2019/10/23 15:40:34 [info] 65194#3586531: *1 [lua] set_by_lua:2: set_by_lua*, client: 127.0.0.1, server: , request: "GET / HTTP/1.1", host: "127.0.0.1:6699"
2019/10/23 15:40:34 [info] 65194#3586531: *1 [lua] rewrite_by_lua(nginx.conf:17):2: rewrite_by_lua*, client: 127.0.0.1, server: , request: "GET / HTTP/1.1", host: "127.0.0.1:6699"
2019/10/23 15:40:34 [info] 65194#3586531: *1 [lua] access_by_lua(nginx.conf:20):2: access_by_lua*, client: 127.0.0.1, server: , request: "GET / HTTP/1.1", host: "127.0.0.1:6699"
2019/10/23 15:40:34 [info] 65194#3586531: *1 [lua] content_by_lua(nginx.conf:23):2: content_by_lua*, client: 127.0.0.1, server: , request: "GET / HTTP/1.1", host: "127.0.0.1:6699"
2019/10/23 15:40:34 [info] 65194#3586531: *1 [lua] header_filter_by_lua:2: header_filter_by_lua*, client: 127.0.0.1, server: , request: "GET / HTTP/1.1", host: "127.0.0.1:6699"
2019/10/23 15:40:34 [info] 65194#3586531: *1 [lua] body_filter_by_lua:2: body_filter_by_lua*, client: 127.0.0.1, server: , request: "GET / HTTP/1.1", host: "127.0.0.1:6699"
2019/10/23 15:40:34 [info] 65194#3586531: *1 [lua] log_by_lua(nginx.conf:32):2: log_by_lua* while logging request, client: 127.0.0.1, server: , request: "GET / HTTP/1.1", host: "127.0.0.1:6699"
2019/10/23 15:40:34 [info] 65194#3586531: *1 kevent() reported that client 127.0.0.1 closed keepalive connection
与 nginx 内置变量的交互
nginx 有很多 内置变量,在 lua 脚本中通过 ngx.var.VARIABLE 获取这些变量。
有一些 nginx 的变量值可以用 lua 修改,大部分是不可以修改的。
修改不能修改的变量时会报错,例如:
lua entry thread aborted: runtime error: ... variable "request_uri" not changeable
与 nginx 共享内存的交互
ngx.shared.DICT 获取用 ua_shared_dict 创建的共享内存。
当前请求的上下文
ngx.ctx 中存放当前请求的上下文,贯穿所有处理阶段:
location /test {
rewrite_by_lua_block {
ngx.ctx.foo = 76
}
access_by_lua_block {
ngx.ctx.foo = ngx.ctx.foo + 3
}
content_by_lua_block {
ngx.say(ngx.ctx.foo)
}
}
常用 lua 数据结构
参考
OpenResty 的一些常规操作
内存字典
04-nginx-lua-module-shared-mem/nginx.conf:
worker_processes 1; #nginx worker 数量
error_log logs/error.log; #指定错误日志文件路径
events {
worker_connections 1024;
}
http {
lua_shared_dict dogs 10m;
server {
listen 6699;
location /set {
content_by_lua_block {
local dogs = ngx.shared.dogs
dogs:set("Jim", 8)
ngx.say("STORED")
}
}
location /get {
content_by_lua_block {
local dogs = ngx.shared.dogs
ngx.say(dogs:get("Jim"))
}
}
}
}
变量设置与读取
05-nginx-lua-module-readvar/nginx.conf:
worker_processes 1; #nginx worker 数量
error_log logs/error.log; #指定错误日志文件路径
events {
worker_connections 1024;
}
http {
server {
listen 6699;
location / {
set $my_var 'my_var';
content_by_lua_block {
local response = {}
response[1]= ngx.var.request_uri;
response[2]=";"
response[3] = ngx.var.my_var;
ngx.say(response);
}
}
}
}
日志打印
06-nginx-lua-module-log/nginx.conf:
worker_processes 1; #nginx worker 数量
error_log logs/error.log debug; #指定错误日志文件路径
events {
worker_connections 1024;
}
http {
server {
listen 6699;
location / {
content_by_lua_block {
ngx.log(ngx.DEBUG,"this is a DEBUG log ",ngx.var.request_uri, ngx.var.host);
ngx.log(ngx.INFO,"this is a INFO log");
ngx.log(ngx.NOTICE,"this is a NOTICE log");
ngx.log(ngx.WARN,"this is a WARN log");
ngx.log(ngx.ERR,"this is a ERR log");
ngx.log(ngx.CRIT,"this is a CRIT log");
ngx.log(ngx.ALERT,"this is a ALERT log");
ngx.log(ngx.EMERG,"this is a EMERG log");
ngx.log(ngx.STDERR,"this is a STDERR log");
}
}
}
}
重定向
07-nginx-lua-module-redirect/nginx.conf:
worker_processes 1; #nginx worker 数量
error_log logs/error.log debug; #指定错误日志文件路径
events {
worker_connections 1024;
}
http {
server {
listen 6699;
location / {
access_by_lua_block{
local host = ngx.var.host
-- 不匹配
local replace,n,err = ngx.re.sub(ngx.var.request_uri, "/abc", "123")
ngx.log(ngx.DEBUG, "uri is: ", ngx.var.request_uri, " ,replace is: ",replace, " ,n is: ",n , " ,err is: ",err)
ngx.redirect(replace,301)
}
}
}
}
4 层负载均衡
08-nginx-lua-module-balancer/nginx.conf:
worker_processes 1; #nginx worker 数量
error_log logs/error.log debug; #指定错误日志文件路径
events {
worker_connections 256;
}
stream{
upstream upstream_balancer{
server 0.0.0.1:6699; # placeholder
balancer_by_lua_block {
local ngx_balancer = require("ngx.balancer")
ngx_balancer.set_more_tries(1)
local ok, err = ngx_balancer.set_current_peer("127.0.0.1","9090")
if not ok then
ngx.log(ngx.ERR, string.format("error while setting current upstream : %s", err))
end
}
}
server {
proxy_timeout 600s;
listen 6699;
proxy_pass upstream_balancer;
}
}
参考
Prometheus 的使用方法
Prometheus 是一个比较流行的告警监控系统,以前写过几篇笔记,这里更系统的整理一下。
这本手册的内容会根据实际工作的需要进行扩展,比较贴近实际。
手册目录在页面左侧,如果是在手机端查看,点击左上角的 符号。
视频讲解:Prometheus普罗米修斯监控入门
参考
Prometheus 安装启动
从 prometheus download 下载已经编译好的 prometheus 程序,该页面上还有 prometheus 提供的 exporter。
命令行参数
Prometheus 的命令行参数不是特别多,比较重要的有:
- --config.file 指定配置文件
- --log.level 日志级别
- --web.listen-address 监听地址
- --web.read-timeout 访问超时时间
- --web.enable-admin-api 启用 admin api
- --web.external-url 访问地址
- --query.max-concurrency 远程调用并发上限
- --storage.tsdb.path 指定数据文件存放目录
- --storage.tsdb.retention.time 设置数据保留期限,例如 15d
- --storage.remote.read-concurrent-limit 读取并发连接数上限
配置文件 prometheus.yml 中主要包含告警规则文件、静态配置的采集地址或者动态发现采集地址的方法。
配置文件格式
配置文件是 yaml 格式的,分为 global、alerting、rule_files 和 scrape_configs 四部分。
global 是全局参数配置,alerting 是告警服务地址,rule_files 是告警和记录规则,scrape_configs 是数据采集地址。其中 rule_files 和 scrape_configs 是重点,后者支持多种动态发现方式,更复杂一些。
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
配置文件检查
可以用 promtool 检查配置文件是否正确:
$ ./promtool check config prometheus.yml
Checking prometheus.yml
SUCCESS: 0 rule files found
参考
Prometheus 的数据类型
Prometheus 存放的是每个指标的时间序列值,指标名由 Metric name 和 labels 组成 :
<metric name>{<label name>=<label value>, ...}
例如:
api_http_requests_total{method="POST", handler="/messages"}
指标类型
指标类型一共有 四种:
Counter:计数器,记录的是正向增长的累计值;
Gauge: 测量值,记录的是指标当前的状态数值;
Histogram: 直方图,就是统计学中的直方图,记录落在每个区间内的指标值的个数;
Summary: 分布图,就是统计学中的分布图,记录指标值的分位数。
生成代码
如果要生成 prometheus 样式的指标数据,可以用 prometheus 提供的 client sdk。go client 中的指标定义方法如下:
scheduleAttempts = prometheus.NewCounterVec(
prometheus.CounterOpts{
Subsystem: SchedulerSubsystem,
Name: "schedule_attempts_total",
Help: "Number of attempts to schedule pods, by the result. 'unschedulable' means a pod could not be scheduled, while 'error' means an internal scheduler problem.",
}, []string{"result"})
// PodScheduleSuccesses counts how many pods were scheduled.
PodScheduleSuccesses = scheduleAttempts.With(prometheus.Labels{"result": "scheduled"})
PreemptionVictims = prometheus.NewGauge(
prometheus.GaugeOpts{
Subsystem: SchedulerSubsystem,
Name: "pod_preemption_victims",
Help: "Number of selected preemption victims",
})
BindingLatency = prometheus.NewHistogram(
prometheus.HistogramOpts{
Subsystem: SchedulerSubsystem,
Name: "binding_duration_seconds",
Help: "Binding latency in seconds",
Buckets: prometheus.ExponentialBuckets(0.001, 2, 15),
},
)
SchedulingLatency = prometheus.NewSummaryVec(
prometheus.SummaryOpts{
Subsystem: SchedulerSubsystem,
Name: SchedulingLatencyName,
Help: "Scheduling latency in seconds split by sub-parts of the scheduling operation",
// Make the sliding window of 5h.
// TODO: The value for this should be based on some SLI definition (long term).
MaxAge: 5 * time.Hour,
},
[]string{OperationLabel},
)
参考
Prometheus 的查询语法
Prometheus 的数据查询语句叫做 Prometheus Query Language,提供了不少查询函数,表达能力比较丰富。 语句的执行结果有四种类型:
- Scalar: 浮点数值
- String: 字符串(预留类型,当前没有实现 2019-08-07 18:04:55)
- Instant vector:瞬时值数组,从不同采集地址采集到的同一指标的当前值组成的数组
- Range vector: 区间数组,从不同采集地址采集到的同一指标在一段时间的内数值组成的数组
前两种类型容易理解,Instant vector 和 Range vector 的有区别前者是一个一个当前值组成的数组,后者是一段区间里的数值组成的数组,继续组成的数组,一看便知:
Instant vector:

Range vector

指标查询
Prometheus 的指标查询语句基本格式为:
指标名称{ 标签名=<数值> }
以 http_server_requests_count 为例,指标上带有 label,通过 label 区分不同来源的数据。
查询 method 为 POST,status 为 200 的采集数据:
http_server_requests_count{method="POST",status="200"}
标签条件支持 =、!=、=~(正则匹配)。
默认查询的是当前时间的数据,如果要查询过去的数据,使用 offset,例如查询 5 分钟前的数据:
http_server_requests_count{method="POST",status="200"} offset 5m
要查询指标在某一区间的数值,使用 [],[] 中是从当前时间相对于相对于 offet向前推的时间段,例如查询 5 分钟前的 1 分钟区间里的数据:
http_server_requests_count{method="POST",status="200"}[1m] offset 5m
参考
Prometheus 指标查询结果运算
Prometheus 的查询语句支持运算,可以使用二元运算符(算术运算符、比较运算符、集合运算符)和聚合运算符直接操作查询出来的数据集,也可以使用 Prometheus 提供的查询函数进行更复杂的运算。
运算符操作的对象主要是 Instant vector、Scalar 类型。操作对象中存在 Instant vector 时,需要知道数组成员如何配对。
vector 的配对问题
操作数是两个 vector 时,vector 之间的配对关系可以是 1:1、1:N、N:1。
1:1,左边 vector 中数据 与 右边 vector 中拥有相同 label 的数据配对,可以用 ignoring 忽略部分 label,或者用 on 指定配对使用的 label,用法如下:
<vector expr> <bin-op> ignoring(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) <vector expr>
1:N,N:1,group_left 表示右边 vector 中的一个成员会匹配左边的 vector 中的多个成员,group_right 反过来,左边 vector 中的一个成员会匹配右边的 vector 中的多个成员,group 指定的是 N。ignoring 和 on 分别用于删减用于匹配的 label 、指定用于匹配的 label:
<vector expr> <bin-op> ignoring(<label list>) group_left(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) group_left(<label list>) <vector expr>
<vector expr> <bin-op> ignoring(<label list>) group_right(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) group_right(<label list>) <vector expr>
vector 配对示例
假设 Prometheus 中存放下面两个指标数据:
method_code:http_errors:rate5m{method="get", code="500"} 24
method_code:http_errors:rate5m{method="get", code="404"} 30
method_code:http_errors:rate5m{method="put", code="501"} 3
method_code:http_errors:rate5m{method="post", code="500"} 6
method_code:http_errors:rate5m{method="post", code="404"} 21
method:http_requests:rate5m{method="get"} 600
method:http_requests:rate5m{method="del"} 34
method:http_requests:rate5m{method="post"} 120
1:1 配对,计算每个方法中 500 错误的占比,因为 method:http_requests:rate5m 没有名为 code 的 label,所以用 ignoring 忽略 code,只剩下 method label 用于配对 :
method_code:http_errors:rate5m{code="500"} / ignoring(code) method:http_requests:rate5m
结果如下:
{method="get"} 0.04 // 24 / 600
{method="post"} 0.05 // 6 / 120
N:1 配对,计算每个方法中所有错误码的占比,多个错误代码对应一类请求:
method_code:http_errors:rate5m / ignoring(code) group_left method:http_requests:rate5m
结果如下:
{method="get", code="500"} 0.04 // 24 / 600
{method="get", code="404"} 0.05 // 30 / 600
{method="post", code="500"} 0.05 // 6 / 120
{method="post", code="404"} 0.175 // 21 / 120
二元运算
两组查询出来的数据集之间的运算。
算术运算符
算术运算符支持:
+、-、*、/(除法)、%(取模)、^(指数)。
比较运算符
比较运算符支持:
==、!=、>、<、>=、<=
集合运算符
集合运算符支持:
and(交集)、or(并集)、unless(差集)
集合运算符需要特别说明一下,vector1 and vector2 的意思从 vector1 中取出满足 vetctor2 筛选条件的指标,例如下面的表达式:
http_server_requests_count{status="200"} and http_server_requests_count{method="POST",instance="10.12.3.5:8866"}
等同于:
http_server_requests_count{status="200",method="POST",instance="10.12.3.5:8866"}
vector1 or vector2 是取出 vector1 的所有成员 和 vector2 中不满足 vector1 的筛选条件的成员。
## 结果中包含所有满足 method="POST" 的数据,如果重复选择 or 之前的数据。
http_server_requests_count{status="200",instance="10.12.3.5:8866"} or http_server_requests_count{method="POST"}
vector1 unless vector2 取出不满足 vector2 筛选条件的所有 vector1 的成员:
http_server_requests_count{status="200",instance="10.12.3.5:8866"} unless http_server_requests_count{method="POST"}
等同于:
http_server_requests_count{status="200",instance="10.12.3.5:8866",method!="POST"}
聚合运算
聚合运算符形态上与函数类似,用于分析查询得到的数据集。
<aggr-op>([parameter,] <vector expression>) [without|by (<label list>)]
部分聚合运算符需要输入参数(parameter),例如 count_values、bottomk、topk 、quantile。支持分组聚合,分组聚合时,可以用 without 忽略指定的 label,或者 by 指定分组使用的 label:
sum: 求和
min: 最小值
max: 最大值
avg: 平均值
stddev: 平方差(stdvar的平方根)
stdvar: 方差
count: 计数
count_values: 统计每个值出现的次数
bottomk: 取结果中最小的 k 位数
topk: 取结果中最大的 k 位数
quantile: 取分位数 (0 ≤ φ ≤ 1)
统计每个值出现的次数
统计每个值出现的次数,参数为结果中的字符串名称:
count_values("str",http_server_requests_count{status="200",instance="10.12.3.5:8866"})

取前 k 位/后 k 位
取结果中最小(bottomk)和最大(topk)的 k 位数,参数为 k:
bottomk(2,http_server_requests_count{status="200",instance="10.12.3.5:8866"})
topk(2,http_server_requests_count{status="200",instance="10.12.3.5:8866"})

取分位数
取第 0.3 分位数,输入参数为分位位置:
quantile(0.3,http_server_requests_count{status="200",instance="10.12.3.5:8866"})

参考
Prometheus 的查询函数
Prometheus 的查询函数数量比较多,这里不罗列了,见 Prometheus Functions。
以后逐渐把不是特别好理解的函数的用法整理到这里。
区间数组
区间数组(range-vector)是过去一段时间内的多个数值,数值(scalar)。
aggregation_over_time() -- 区间内聚合运算
这一组函数有多个,分别计算区间数组中的数据的平均值、最小值、最大值等:
形态:
avg_over_time(range-vector)
min_over_time(range-vector)
max_over_time(range-vector)
sum_over_time(range-vector)
count_over_time(range-vector)
quantile_over_time(scalar, range-vector)
stddev_over_time(range-vector)
stdvar_over_time(range-vector)
holt_winters() -- 平滑数值
形态:holt_winters(v range-vector, sf scalar, tf scalar)
根据区间数组中的数据计算下一个平滑值,sf 是历史数值的权重,tf 是最新数值的权重,sf 和 tf 的取值范围为 [0,1]。
increase()
形态:increase(v range-vector)
计算区间数组中的增加值。
idelta()
形态:idelta(v range-vector)
返回区间数组中最新的两个数值的差值。
irate()、rate()
形态:irate(v range-vector)
用区间数组中最新的两个数值计算每秒变化。
形态:rate(v range-vector)
用区间数组中的数值计算每秒变化。
resets()
形态:resets(v range-vector)
返回数组中被重置的计数器(counter)的数量。
changes() -- 指定时间段内变化次数
形态:changes(v range-vector)
计算 range-vector(区间数组)中的数值变化的次数。
delta()
形态:delta(v range-vector)
计算区间数组中第一个数值与最后一个数值的差值。
deriv() -- 线性回归
形态:deriv(v range-vector)
predict_linear()
形态:predict_linear(v range-vector, t scalar)
线性预测时长 t 之后的数值。
数组
数组(instant-vector)是同一时刻的多个数值,
abs() -- 算绝对值
形态:abs(v instant-vector)
将数组中的数值转换成各自的绝对值。
absent() -- 缺值判断
形态:absent(v instant-vector)
如果指标为空,结果为 1,否则结果为空。例如下图中指标查询结果为空,absent 的结果是 1:
{kind=link}
ceil() -- 归整
形态:ceil(v instant-vector)
将数组中的数值转换成各自最接近的整数。
floor() -- 向下归整
形态:floor(v instant-vector)
clamp_max() -- 上限转换
形态:clamp_max(v instant-vector, max scalar)
将数组中超过上限的数值转换成上限值 max。
clamp_min() -- 下限转换
形态:clamp_min(v instant-vector, min scalar)
将数组中低于下限的数值转换成下限值 min。
exp()
形态:exp(v instant-vector)
histogram_quantile() -- 分位数
形态:histogram_quantile(φ float, b instant-vector)
返回数组中的 φ 分位数 [0,1]。
round()
形态:round(v instant-vector, to_nearest=1 scalar)
将数组中的数据向上归整,to_nearest 是归整步长。
The optional to_nearest argument allows specifying the nearest multiple to which the sample values should be rounded. This multiple may also be a fraction.
scalar()
形态:scalar(v instant-vector)
将只有一个成员的数组转换成数值。
sort()、sort_desc()
形态:sort(v instant-vector)、sort_desc(v instant-vector)
分别为升序、降序排列。
sqrt()
形态:sqrt(v instant-vector)
计算平方根。
label_join()
形态:label_join(v instant-vector, dst_label string, separator string, src_label_1 string, src_label_2 string, ...)
将多个 src_label_XX 拼接成一个新的 dst_label,用分隔符 separator 连接。
label_replace()
形态:label_replace(v instant-vector, dst_label string, replacement string, src_label string, regex string)
用正则 regex 提取 src_label 中的字段,按照 replacement 形态拼接成 dst_label。
label_replace(up{job="api-server",service="a:c"}, "foo", "$1", "service", "(.*):.*")
ln()
形态:ln(v instant-vector)
计算数组中的数值的对数。
log2() 、log10()
形态:log2(v instant-vector)、log10(v instant-vector)
vector()
形态:vector(s scalar)
将数值转换成数组。
时间换算
day_of_month() -- 月中位置
形态:day_of_month(v=vector(time()) instant-vector)
返回宿主中的时间位于月中第几天。
day_of_week() -- 周中位置
形态:day_of_week(v=vector(time()) instant-vector)
返回宿主中的时间位于周中第几天。
days_in_month() -- 月份天数
形态:days_in_month(v=vector(time()) instant-vector)
返回宿主中时间所在月份的天数。
year()
形态:year(v=vector(time()) instant-vector)
month()
形态:month(v=vector(time()) instant-vector)
hour()
形态:hour(v=vector(time()) instant-vector)
返回数组中时间位于当天的第几个小时。
minute()
形态:minute(v=vector(time()) instant-vector)
time()
形态:time()
返回当前的 UTC 时间(秒)
timestamp()
形态:timestamp(v instant-vector)
返回数组中数值对应的时间戳。
参考
Prometheus 的 exporters
Prometheus 的负责收集指标数据、执行告警规则、提供指标数据查询功能,指标数据要么是目标系统实现了 Prometheus 样式的指标数据,要么通过各种 exporter 获取。Third-party exporters 中收录了很多 exporter,本手册逐渐收录工作中用到的一些 exporter。
- blackbox exporter:探测目标服务,支持 HTTP HTTPS DNS TCP ICMP
参考
Blackbox exporter:探测远程地址(HTTP HTTPS DNS TCP ICMP)
blackbox_exporter 用来探测目标地址,支持的协议有:HTTP、HTTPS、DNS、TCP、ICMP。
配置文件
blackbox 的配置文件由多个 modules 组成,每个 module 代表一个功能。
在当前目录中准备一个配置文件 blackbox.yml,里面有 http_2xx、http_post_2xx 等模块:
modules:
http_2xx:
prober: http
http:
headers:
Accept: "*/*"
http_post_2xx:
prober: http
http:
method: POST
tcp_connect:
prober: tcp
pop3s_banner:
prober: tcp
tcp:
query_response:
- expect: "^+OK"
tls: true
tls_config:
insecure_skip_verify: false
ssh_banner:
prober: tcp
tcp:
query_response:
- expect: "^SSH-2.0-"
irc_banner:
prober: tcp
tcp:
query_response:
- send: "NICK prober"
- send: "USER prober prober prober :prober"
- expect: "PING :([^ ]+)"
send: "PONG ${1}"
- expect: "^:[^ ]+ 001"
icmp:
prober: icmp
example.yml 中列出了支持的功能模块。
启动运行
使用 docker 运行,blackbox.yml 位于当前目录,docker 的安装方法见 docker 使用手册:
docker run --rm -d -p 9115:9115 --name blackbox_exporter -v `pwd`:/config prom/blackbox-exporter:v0.15.1 --config.file=/config/blackbox.yml
查看更多镜像 prom/blackbox-exporter。
参考
Prometheus 的 pushgateway 作用和用法
Prometheus 采集数据的方式是定时轮询,轮询的频率在配置文件中设置:
global:
scrape_interval: 30s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 30s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
对于短时运行、不支持轮询的任务,可以引入 pushgateway,将指标数值以 push 的方式推送到 pushgateway暂存,然后 prometheus 从 pushgateway 中轮询。

运行 pushgateway
Docker 的安装方式见 Docker 安装部署。
用 docker 启动 pushgateway 是最方面的方式:
docker pull prom/pushgateway:v0.9.1
docker run -d -p 9091:9091 prom/pushgateway:v0.9.1
可以使用的镜像 tag 见 prom/pushgateway/tags,这里使用的是 v0.9.1。
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9fe07d8f549e prom/pushgateway:v0.9.1 "/bin/pushgateway" 4 seconds ago Up 2 seconds 0.0.0.0:9091->9091/tcp sleepy_swanson
用浏览器打开 pushgateway 的页面,端口为 9901:

向 pushgateway 推送数据
推送数据的接口使用的是 http 协议,pushgateway api 中有说明。
用 curl 推送指标数值:
$ cat <<EOF | curl --data-binary @- http://127.0.0.1:9091/metrics/job/some_job/instance/some_instance
# TYPE some_metric counter
some_metric{label="val1"} 42
# TYPE another_metric gauge
# HELP another_metric Just an example.
another_metric 2398.283
EOF
推送数据后,在页面中可以看到对应的 metrics:

用 Prometheus 采集 pushgateway 中指标数据
推送到 pushgateway 中的指标数据,通过 pushgateway 的 /metrics 接口获取:
$ curl http://127.0.0.1:9091/metrics |grep "some_"
push_time_seconds{instance="some_instance",job="some_job"} 1.5692110390599859e+09
# TYPE some_metric counter
some_metric{instance="some_instance",job="some_job",label="val1"} 42
可以看到 /metrics 接口返回的数据格式是 prometheus 支持的格式,因此用 prometheus 直接采集该接口的数据即可。
在 prometheus 中配置一个静态的 job,轮询 pushgateway 中的 /metrics:
scrape_configs:
- job_name: "pushgateway"
static_configs:
- targets:
- "127.0.0.1:9091/metrics"
labels:
pushgateway: "true"
参考
Prometheus 进阶拓展
规模扩展
API 和 SDK
常用技巧
问题记录
视频讲义
参考
Docker 使用手册
这个系列的内容来自过去几年工作中积攒的笔记:Docker 笔记。
最好的 Docker 资料当然是:Docker官方文档。
👈 从左侧目录开始阅读。
Docker 安装部署
docker、docker-ce 和 docker-ee 的关系见 moby、docker-ce与docker-ee。
推荐使用 docker-ce。
CentOS - 安装 docker-ce
添加 docker-ce 的源,安装 docker-ce:
wget https://download.docker.com/linux/centos/docker-ce.repo
mv docker-ce.repo /etc/yum.repos.d
yum install -y docker-ce
启动:
systemctl start docker
配置阿里云镜像
docker 的镜像服务器在境外,从国内拉取镜像会特别慢。给 docker 配置一个国内的镜像源可以大大缩短镜像的获取时间。
在 /etc/docker/daemon.json 中添加下面的配置,如果该文件不存在则创建, 然后重启 docker:
{
"registry-mirrors" : [
"https://pee6w651.mirror.aliyuncs.com"
]
}
如果是有图形界面的 docker 更简单:

参考
Docker 容器操作
Docker 镜像的管理方法在后面章节,这里先直接用下面的命令获取后面的演示中用到的镜像:
docker pull alpine:3.9.5
docker command 中列出了所有命令的用法,下面只列举最常用的一些。
前台运行
$ docker run --rm -it alpine:3.9.5 /bin/sh
/ # ip addr |grep eth0
298: eth0@if299: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
docker help run 查看选项:
--rm :执行结束后删除容器
-t :创建tty
-i :交互运行
后台运行
$ docker run -d alpine:3.9.5 /bin/sh -c "while true;do echo hello world; sleep 1;done"
2eecc150eda7af8226b29856468a5428e59664977663779f591cae59c1a217b5
-d 表示放入后台运行, 下面显示字符串容器的 id。
查看容器
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d9c9aed4e644 alpine:3.9.5 "/bin/sh -c 'while t…" 57 seconds ago Up 55 seconds infallible_antonelli
第一栏是容器 ID 的简短形式, 最后一栏 docker 自动为容器分配的名字,可以通过这个名字和容器进行交互。
运行时指定容器名:
$ docker run -d --name="Hello" alpine:3.9.5 /bin/sh -c "while true;do echo hello world; sleep 1;done"
容器的输出
用 docker logs 查看后台运行的容器的输出, 目标容器可以通过 id 指定, 也可以通过 name 指定:
$ docker logs -f Hello
hello world
hello world
hello world
容器中进程
可以通过 docker top 查看容器内运行的进程:
$ docker top Hello
PID USER TIME COMMAND
51993 root 0:00 /bin/sh -c while true;do echo hello world; sleep 1;done
52096 root 0:00 sleep 1
容器详情
可以通过 docker inspect 查看容器的详情:
$ docker inspect Hello
[
{
"Id": "ef3983bcc0c13660d95d33dce1a4cd7626992a2f211022ac509bae891918918d",
"Created": "2020-03-01T10:44:06.5211288Z",
"Path": "/bin/sh",
"Args": [
"-c",
"while true;do echo hello world; sleep 1;done"
...省略...
进入运行中的容器
docker exec 在指定容器中执行命令,可以通过它进入容器内部:
$ docker exec -it Hello /bin/sh
/ # ip addr |grep eth0
328: eth0@if329: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP
inet 172.17.0.3/16 brd 172.17.255.255 scope global eth0
停止容器
docker stop停止正在运行的容器:
$ docker stop Hello
Hello
$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
cf591db9d6e9 alpine:3.9.5 "/bin/sh -c 'while t…" About a minute ago Exited (137) 55 seconds ago Hello
容器被停止之后,容器文件依然是存在的。
删除容器
删除运行中的容器:
$ docker rm -f Hello
删除已经退出的容器:
$ docker rm -Hello
端口映射
在run的-P/-p的选项, 这个选项将镜像的端口映射到宿主机的端口, 这样就可以从外部使用镜像内的服务。
$ docker run -idt -p 8080:80 nginx:stable
Unable to find image 'nginx:stable' locally
...省略...
查看端口映射情况:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
223c0e90f378 nginx:stable "nginx -g 'daemon of…" 10 seconds ago Up 9 seconds 0.0.0.0:8080->80/tcp friendly_leavitt
访问端口:
$ curl 127.0.0.1:8080
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
本地目录挂载
把本地的目录挂载到容器中:
$ mkdir config
$ echo aaaa >config/a.conf
$ docker run -it --rm -v `pwd`/config:/tmp/ alpine:3.9.5 /bin/sh
参考
Docker 镜像的管理
搜索镜像
docker search 默认搜索 docker hub 中的镜像:
$ docker search nginx
如果搜索其它 registry 中的镜像,可用下面的 方法:
docker search 192.168.1.104:5000/redis
docker search 192.168.1.104:5000/*
到 Docker Hub 上找镜像、查看镜像详情:https://hub.docker.com 。
镜像的 tag
每个镜像都有 tag,tag 是镜像的版本,我们可以根据自己需要为镜像重新命名,生成新的 tag:
docker tag alpine:3.9.5 myalpine:1.0
下载镜像
$ docker pull alpine:3.9.5
查看镜像
$ docker images
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
alpine 3.9.5 82f67be598eb 5 weeks ago 5.53MB
myalpine 1.0 82f67be598eb 5 weeks ago 5.53MB
查看镜像详情:
$ docker inspect alpine:3.9.5
镜像的导入导出
用 save 命令把镜像导出到文件中:
$ docker save alpine:3.9.5 -o alpine.tar
用 load 命令加载:
$ docker load -i alpine.tar
制作新镜像
方法一:编写 Dockerfile,使用 docker build 直接建立一个镜像。
docker-containers 中提供不少实用镜像 Dockerfile,可以参考:
git clone https://github.com/introclass/docker-containers.git
方法二:把现有的容器做成镜像。
$ docker commit
Usage: docker commit [OPTIONS] CONTAINER [REPOSITORY[:TAG]]
Create a new image from a containers changes
-a, --author="" Author (e.g., "John Hannibal Smith <[email protected]>")
-m, --message="" Commit message
-p, --pause=true Pause container during commit
例如:
$ docker commit Hello myhello:latest
sha256:72c60d1495909cada678ee468171828c8fccf4b41712a96bc43017139e35568e
方法三:制作 BASE 镜像。
前面两种做法都需要先有一个镜像,在已有镜像的基础上制作新镜像,那么怎样凭空创建一个镜像呢?
Create a base image 介绍了两种方法:
#!/usr/bin/env bash
#
# Create a base CentOS Docker image.
#
# This script is useful on systems with yum installed (e.g., building
# a CentOS image on CentOS). See contrib/mkimage-rinse.sh for a way
# to build CentOS images on other systems.
usage() {
cat <<EOOPTS
$(basename $0) [OPTIONS] <name>
OPTIONS:
-y <yumconf> The path to the yum config to install packages from. The
default is /etc/yum.conf.
EOOPTS
exit 1
}
# option defaults
yum_config=/etc/yum.conf
while getopts ":y:h" opt; do
case $opt in
y)
yum_config=$OPTARG
;;
h)
usage
;;
\?)
echo "Invalid option: -$OPTARG"
usage
;;
esac
done
shift $((OPTIND - 1))
name=$1
if [[ -z $name ]]; then
usage
fi
#--------------------
target=$(mktemp -d --tmpdir $(basename $0).XXXXXX)
set -x
# 创建系统的必须的设备文件
mkdir -m 755 "$target"/dev
mknod -m 600 "$target"/dev/console c 5 1
mknod -m 600 "$target"/dev/initctl p
mknod -m 666 "$target"/dev/full c 1 7
mknod -m 666 "$target"/dev/null c 1 3
mknod -m 666 "$target"/dev/ptmx c 5 2
mknod -m 666 "$target"/dev/random c 1 8
mknod -m 666 "$target"/dev/tty c 5 0
mknod -m 666 "$target"/dev/tty0 c 4 0
mknod -m 666 "$target"/dev/urandom c 1 9
mknod -m 666 "$target"/dev/zero c 1 5
# 安装root文件系统
yum -c "$yum_config" --installroot="$target" --releasever=/ --setopt=tsflags=nodocs \
--setopt=group_package_types=mandatory -y groupinstall Core
yum -c "$yum_config" --installroot="$target" -y clean all
# 网络配置
cat > "$target"/etc/sysconfig/network <<EOF
NETWORKING=yes
HOSTNAME=localhost.localdomain
EOF
# 删除不必要的文件
# effectively: febootstrap-minimize --keep-zoneinfo --keep-rpmdb
# --keep-services "$target". Stolen from mkimage-rinse.sh
# locales
rm -rf "$target"/usr/{lib,share}/locale,{lib,lib64}/gconv,bin/localedef,sbin/build-locale-archive}
# docs
rm -rf "$target"/usr/share/{man,doc,info,gnome/help}
# cracklib
rm -rf "$target"/usr/share/cracklib
# i18n
rm -rf "$target"/usr/share/i18n
# sln
rm -rf "$target"/sbin/sln
# ldconfig
rm -rf "$target"/etc/ld.so.cache
rm -rf "$target"/var/cache/ldconfig/*
version=
if [ -r "$target"/etc/redhat-release ]; then
version="$(sed 's/^[^0-9\]*\([0-9.]\+\).*$/\1/' "$target"/etc/redhat-release)"
fi
if [ -z "$version" ]; then
echo >&2 "warning: cannot autodetect OS version, using '$name' as tag"
version=$name
fi
# 打包成镜像, 镜像名是$name, tag是$version
tar --numeric-owner -c -C "$target" . | docker import - $name:$version
# 运行新建立的镜像
docker run -i -t $name:$version echo success
rm -rf "$target"
发布镜像
将镜像提交到镜像中心
$ docker push 本地的镜像名:镜像标签
镜像的本地存放
Docker 镜像管理(一):本地镜像、本地容器的文件存放目录
参考
Docker 原理与容器文件讲解
Docker 的基本原理
Docker 镜像文件的本地管理
更多笔记
参考
用 docker-compose 提高 docker 使用效率
doker-compose-files 中会持续收集一些常用的 compose 文件:
git clone https://github.com/introclass/docker-compose-files.git
参考
MySQL 的常规使用
MySQL 被 Oracle 收购后,分叉成了隶属 Oracle 的 MySQL 分支,和社区维护的 MariaDB 分支。在 CentOS 等开源系统上,现在通常默认提供的是 MariaDB。
MariaDB Docker 镜像的使用
Docker 社区维护了一个 mariadb 镜像:
$ docker search mariadb
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
mariadb MariaDB is a community-developed fork of MyS… 3263 [OK]
镜像的使用方法见 mariadb image usage,镜像构建文件见 docker-library/mariadb。
下面以 mariadb:10.4.1 为例:
$ docker push mariadb:10.4.1
镜像的环境变量
MYSQL_ROOT_PASSWORD # root 密码
MYSQL_DATABASE # 启动时创建一个 database
MYSQL_USER, MYSQL_PASSWORD # 启动时增加一个特权用户
MYSQL_ALLOW_EMPTY_PASSWORD # 允许空密码
MYSQL_RANDOM_ROOT_PASSWORD # 随机生成 root 密码
镜像的关键目录
/docker-entrypoint-initdb.d :镜像启动时会根据上面的环境变量,完成数据库、用户和密码后,然后执行该目录中 .sh、.sql、.sql.gz 文件,可以把初始化脚步挂载到这个目录中,按照文件名称排序执行。
特别注意,只有第一次启动,/var/lib/mysql 目录为空的时候才会加载执行。
/var/lib/mysql:数据库文件的目录。
/etc/mysql/my.cnf:数据库的配置文件。
/etc/mysql/conf.d:默认的 my.cnf 文件的配置加载目录。
镜像的命令行参数
$ docker run -it --rm mariadb:10.4.1 --verbose --help
镜像的使用示范
Docker Compose 启动:
version: "3"
services:
mysql:
image: mariadb:10.4.1
environment:
- TZ=CST-8
- MYSQL_ROOT_PASSWORD=root
- MYSQL_DATABASE=testdb
- MYSQL_USER=testdb
- MYSQL_PASSWORD=testdb
volumes:
#本地文件目录
- ./data/mysql:/var/lib/mysql
- ./conf/sql:/docker-entrypoint-initdb.d
ports:
- "13306:3306"
执行 sql:
$ mysql -u testdb -ptestdb -h 127.0.0.1 -P 3306 -D testdb< ./sql/insert.sql
或者:
$ docker exec -i mysql sh -c 'exec mysql -utestdb -ptestdb -D testdb' < ./sql/insert.sql
导出数据(只导出表结构 -d,只导表数据 -t):
$ docker exec mysql sh -c 'exec mysqldump -utestdb -ptestdb testdb' >backup.sql
数据重新加载方法和执行 sql 相同。
参考
HyperLedger 超级账本项目学习
第一次接触超级账本差不多是两年前了,当时记录了大量的 hyperledger 学习笔记,还做了两套视频教程:
在过去两年多的时间里,陆续有人来咨询 HyperLedger 相关的问题,感觉以在校学生居多。不少人按照网上的其它教程操作,遇到问题后无法解决,到处求救。感觉有必要重新整理出一份更简单清晰的入门教程。
现在工作重点发生了转移,对 HyperLedger 关注很少,一些非常细节的问题,我很可能也无法解答,但做一份入门教程,让「小白」照着敲命令能跑通,还在我的能力范围内。
回想起当年在学校折腾 linux 等各种系统时的情景,饱经蹂躏,一个分号查一下午的事情经常有。找到一个教程,然后这个跑不通、那个跑不通,一脸懵逼,两眼抓瞎,那种痛苦啊。并且常常为了解决一个问题,被迫去了解了 N 种知识。
我会尽量让这份入门教程简洁、流畅,如果用到了其它方面的知识,也会告知方向。
参考
HyperLedger Fabric:单机极简部署
这是 Fabric 文档 Building Your First Network 中提供的做法。Fabric 的示例文件中提供了 一个名为 “byfn.sh” 的脚本 ,这个脚本用 Docker 在本地搭建了一套 Fabric。
用 byfn 搭建的 Fabric 非常不实用,只适合用来学习,但是我发现很多人起步时都采用的这种方式。并且当我们只需要一个简单的 Fabric 环境进行简单验证时,用 byfn 创建比较方便。
实际应用必须采用多节点的方式部署,多节点部署可以参考历史文章:
准备依赖的软件
第一,安装 docker。要掌握用 byfn 搭建 fabric 的方法,必须要对 docker 有基本的了解,到 Docker使用手册 中学习。
第二,安装 git。git 是现在最常用的代码管理工具,我们要用 git 从 github 中拉取 fabric-sample 文件,可以参考 Git使用手册,这里只用 git 获取代码,不需要掌握代码提交、合并等用法,虽然在以后的工作中一定会遇到。
$ yum install -y git # CentOS 系统上
$ apt-get install -y git # Ubuntu 系统上
$ brew install -y git # Mac 系统上
下载 Fabric 文件
先创建一个工作目录,文件都存放在这个目录中:
$ mkdir ~/hyperledger-fabric-1.4.4
$ cd ~/hyperledger-fabric-1.4.4
下载 fabric 文件。fabric 每个版本的 release 文件都发布在 fabric releases 上:

我使用的是 Mac 系统,下载的是 hyperledger-fabric-darwin-amd64-1.4.4.tar.gz:
$ wget https://github.com/hyperledger/fabric/releases/download/v1.4.4/hyperledger-fabric-darwin-amd64-1.4.4.tar.gz
这个下载过程可能很慢,可能需要翻qiang。
下载 byfn 系列脚本:
$ git clone https://github.com/hyperledger/fabric-samples.git
$ cd fabric-samples
$ git checkout -b v1.4.4 # 根据需要切换到对应版本
下载解压后得到 bin 和 config 两个目录,bin 目录中是 fabric 的命令文件,config 中 fabric 的配置示例:
$ tar -xvf hyperledger-fabric-darwin-amd64-1.4.4.tar.gz
$ ls
bin config
把 bin 目录添加到环境变量 PATH:
export PATH=$PATH:~/hyperledger-fabric-1.4.4/bin
准备 first-network 需要的证书和文件
first-network 就是一个最简单 fabric,它的部署文件位于 fabric-samples/first-network:
$ cd fabric-samples/first-network
进入该目录后,用 byfn.sh 创建 first-network 需要的证书文件:
$ ./byfn.sh generate
如果提示错误,"cryptogen tool not found. exiting",那是因为没有把 bin 目录添加到环境变量 PATH 中:
$ ./byfn.sh generate
Generating certs and genesis block for channel 'mychannel' with CLI timeout of '10' seconds and CLI delay of '3' seconds
Continue? [Y/n] y
proceeding ...
cryptogen tool not found. exiting # 如果没有把 bin 目录添加到环境变量 PATH 就会遇到这个问题!
执行成功的结果如下。
注意 ## 中的文字,“Generate certificates ...”,这就是为相应组织或者模块生成了证书。
first-network 是由 Org1 和 Org2 两个成员组成的区块链网络,网络中有一个 Orderer,Org1 有两个 Peer,Org2 有两个 Peer:
➜ first-network git:(v1.4.4) ./byfn.sh generate
Generating certs and genesis block for channel 'mychannel' with CLI timeout of '10' seconds and CLI delay of '3' seconds
Continue? [Y/n] y
proceeding ...
/Users/lijiao/hyperledger-fabric-1.4.4/bin/cryptogen
##########################################################
##### Generate certificates using cryptogen tool #########
##########################################################
+ cryptogen generate --config=./crypto-config.yaml
org1.example.com
org2.example.com
+ res=0
+ set +x
Generate CCP files for Org1 and Org2
/Users/lijiao/hyperledger-fabric-1.4.4/bin/configtxgen
##########################################################
######### Generating Orderer Genesis block ##############
##########################################################
CONSENSUS_TYPE=solo
+ '[' solo == solo ']'
+ configtxgen -profile TwoOrgsOrdererGenesis -channelID byfn-sys-channel -outputBlock ./channel-artifacts/genesis.block
2019-11-26 22:23:26.404 CST [common.tools.configtxgen] main -> INFO 001 Loading configuration
2019-11-26 22:23:26.527 CST [common.tools.configtxgen.localconfig] completeInitialization -> INFO 002 orderer type: solo
2019-11-26 22:23:26.527 CST [common.tools.configtxgen.localconfig] Load -> INFO 003 Loaded configuration: /Users/lijiao/hyperledger-fabric-1.4.4/fabric-samples/first-network/configtx.yaml
2019-11-26 22:23:26.638 CST [common.tools.configtxgen.localconfig] completeInitialization -> INFO 004 orderer type: solo
2019-11-26 22:23:26.638 CST [common.tools.configtxgen.localconfig] LoadTopLevel -> INFO 005 Loaded configuration: /Users/lijiao/hyperledger-fabric-1.4.4/fabric-samples/first-network/configtx.yaml
2019-11-26 22:23:26.643 CST [common.tools.configtxgen] doOutputBlock -> INFO 006 Generating genesis block
2019-11-26 22:23:26.644 CST [common.tools.configtxgen] doOutputBlock -> INFO 007 Writing genesis block
+ res=0
+ set +x
#################################################################
### Generating channel configuration transaction 'channel.tx' ###
#################################################################
+ configtxgen -profile TwoOrgsChannel -outputCreateChannelTx ./channel-artifacts/channel.tx -channelID mychannel
2019-11-26 22:23:26.686 CST [common.tools.configtxgen] main -> INFO 001 Loading configuration
2019-11-26 22:23:26.794 CST [common.tools.configtxgen.localconfig] Load -> INFO 002 Loaded configuration: /Users/lijiao/hyperledger-fabric-1.4.4/fabric-samples/first-network/configtx.yaml
2019-11-26 22:23:26.899 CST [common.tools.configtxgen.localconfig] completeInitialization -> INFO 003 orderer type: solo
2019-11-26 22:23:26.899 CST [common.tools.configtxgen.localconfig] LoadTopLevel -> INFO 004 Loaded configuration: /Users/lijiao/hyperledger-fabric-1.4.4/fabric-samples/first-network/configtx.yaml
2019-11-26 22:23:26.899 CST [common.tools.configtxgen] doOutputChannelCreateTx -> INFO 005 Generating new channel configtx
2019-11-26 22:23:26.905 CST [common.tools.configtxgen] doOutputChannelCreateTx -> INFO 006 Writing new channel tx
+ res=0
+ set +x
#################################################################
####### Generating anchor peer update for Org1MSP ##########
#################################################################
+ configtxgen -profile TwoOrgsChannel -outputAnchorPeersUpdate ./channel-artifacts/Org1MSPanchors.tx -channelID mychannel -asOrg Org1MSP
2019-11-26 22:23:26.943 CST [common.tools.configtxgen] main -> INFO 001 Loading configuration
2019-11-26 22:23:27.049 CST [common.tools.configtxgen.localconfig] Load -> INFO 002 Loaded configuration: /Users/lijiao/hyperledger-fabric-1.4.4/fabric-samples/first-network/configtx.yaml
2019-11-26 22:23:27.165 CST [common.tools.configtxgen.localconfig] completeInitialization -> INFO 003 orderer type: solo
2019-11-26 22:23:27.165 CST [common.tools.configtxgen.localconfig] LoadTopLevel -> INFO 004 Loaded configuration: /Users/lijiao/hyperledger-fabric-1.4.4/fabric-samples/first-network/configtx.yaml
2019-11-26 22:23:27.165 CST [common.tools.configtxgen] doOutputAnchorPeersUpdate -> INFO 005 Generating anchor peer update
2019-11-26 22:23:27.166 CST [common.tools.configtxgen] doOutputAnchorPeersUpdate -> INFO 006 Writing anchor peer update
+ res=0
+ set +x
#################################################################
####### Generating anchor peer update for Org2MSP ##########
#################################################################
+ configtxgen -profile TwoOrgsChannel -outputAnchorPeersUpdate ./channel-artifacts/Org2MSPanchors.tx -channelID mychannel -asOrg Org2MSP
2019-11-26 22:23:27.206 CST [common.tools.configtxgen] main -> INFO 001 Loading configuration
2019-11-26 22:23:27.347 CST [common.tools.configtxgen.localconfig] Load -> INFO 002 Loaded configuration: /Users/lijiao/hyperledger-fabric-1.4.4/fabric-samples/first-network/configtx.yaml
2019-11-26 22:23:27.473 CST [common.tools.configtxgen.localconfig] completeInitialization -> INFO 003 orderer type: solo
2019-11-26 22:23:27.473 CST [common.tools.configtxgen.localconfig] LoadTopLevel -> INFO 004 Loaded configuration: /Users/lijiao/hyperledger-fabric-1.4.4/fabric-samples/first-network/configtx.yaml
2019-11-26 22:23:27.473 CST [common.tools.configtxgen] doOutputAnchorPeersUpdate -> INFO 005 Generating anchor peer update
2019-11-26 22:23:27.474 CST [common.tools.configtxgen] doOutputAnchorPeersUpdate -> INFO 006 Writing anchor peer update
+ res=0
+ set +x
启动 first-network
启动过程中要拉取 fabric 的 docker 镜像,在国内可能特别慢,建议先给 docker 配置镜像源 :
first-network 启动命令:
$ ./byfn.sh up
Starting for channel 'mychannel' with CLI timeout of '10' seconds and CLI delay of '3' seconds
Continue? [Y/n] y
proceeding ...
Unable to find image 'hyperledger/fabric-tools:latest' locally
latest: Pulling from hyperledger/fabric-tools
7ddbc47eeb70: Pulling fs layer
c1bbdc448b72: Pulling fs layer
...省略...
90
===================== Query successful on peer1.org2 on channel 'mychannel' =====================
========= All GOOD, BYFN execution completed ===========
_____ _ _ ____
| ____| | \ | | | _ \
| _| | \| | | | | |
| |___ | |\ | | |_| |
|_____| |_| \_| |____/
出现 All GOOD 后,启动成功。
first-network 的组成
用 docker ps 可以正在运行的容器,最后一列是容器的名称:
➜ first-network git:(v1.4.4) ✗ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b2d7c1e32b74 dev-peer1.org2.example.com-mycc-1.0-26c2ef3283 "chaincode -peer.add…" 5 minutes ago Up 5 minutes dev-peer1.org2.example.com-mycc-1.0
4e3b06b72953 dev-peer0.org1.example.com-mycc-1.0-384f11f484 "chaincode -peer.add…" 5 minutes ago Up 5 minutes dev-peer0.org1.example.com-mycc-1.0
6aebf7da1213 dev-peer0.org2.example.com-mycc-1.0-15b571b3ce "chaincode -peer.add…" 6 minutes ago Up 6 minutes dev-peer0.org2.example.com-mycc-1.0
bb5b01488fe5 hyperledger/fabric-tools:latest "/bin/bash" 7 minutes ago Up 7 minutes cli
7781e5181954 hyperledger/fabric-peer:latest "peer node start" 7 minutes ago Up 7 minutes 0.0.0.0:7051->7051/tcp peer0.org1.example.com
d5ae822f095a hyperledger/fabric-orderer:latest "orderer" 7 minutes ago Up 7 minutes 0.0.0.0:7050->7050/tcp orderer.example.com
844929c28283 hyperledger/fabric-peer:latest "peer node start" 7 minutes ago Up 7 minutes 0.0.0.0:10051->10051/tcp peer1.org2.example.com
5ff858ab54cc hyperledger/fabric-peer:latest "peer node start" 7 minutes ago Up 7 minutes 0.0.0.0:9051->9051/tcp peer0.org2.example.com
7ab6831f4530 hyperledger/fabric-peer:latest "peer node start" 7 minutes ago Up 7 minutes 0.0.0.0:8051->8051/tcp peer1.org1.example.com
组成 first-network 的容器:
orderer.example.com 形成维护共识的 orderer
peer0.org1.example.com org1 的第一个 peer
peer1.org1.example.com org1 的第二个 peer
peer0.org2.example.com org2 的第一个 peer
peer1.org2.example.com org2 的第二个 peer
下面三个容器是 byfn.sh 脚本创建的一个名为 mycc 的智能合约,fabric 的智能合约是用 docker 运行的:
dev-peer1.org2.example.com-mycc-1.0
dev-peer0.org1.example.com-mycc-1.0
dev-peer0.org2.example.com-mycc-1.0
cli 容器用来查看、管理 first-network,用下面的方法进入:
$ docker exec -it cli /bin/bash
root@bb5b01488fe5:/opt/gopath/src/github.com/hyperledger/fabric/peer#
在容器内执行 ls,可以看到创建 first-network 时用到文件:
$ ls -lh
total 28K
drwxr-xr-x 7 root root 224 Nov 26 14:23 channel-artifacts
drwxr-xr-x 4 root root 128 Nov 26 14:23 crypto
-rw-r--r-- 1 root root 3 Nov 26 14:34 log.txt
-rw-r--r-- 1 root root 21K Nov 26 14:31 mychannel.block
drwxr-xr-x 10 root root 320 Nov 25 14:52 scripts
first-network 是怎么回事?
这个问题三言两语还真是说不清楚。别看创建 first-network 特别简单,但是 byfn.sh 背后的工作有很多!用 docker-compose 和 一堆脚本。强烈建议通过下面教程学习 fabric 的组成。这个教程使用的是 fabric 1.1 (两年前的版本),但基本原理不变,把每个组件的用途和配置方法都讲清楚了:
参考
HyperLedger Fabric 区块链浏览器的部署方法
blockchain-explorer 是一个独立项目,可以用来查看 fabric 内的成员和区块。
安装依赖的软件
explorer 依赖 nodejs 8.11(高版本的不支持)、PostgreSQL 9.5 和以上版本、jq 命令。
下面的操作是在 Mac 上进行的,除了依赖软件的安装方式,大部分操作和在 linux 上操作相同:
以前的笔记,可参考其中的部分内容:超级账本HyperLedger:Explorer安装使用。
PostgreSQL 安装设置
如果对 PostgreSQL 完全不了解,可以先学习:
这里为了屏蔽不同操作系统上的差异,用 docker 启动 PostgreSQL 数据库,这个过程会拉取 Docker 镜像,单机极简部署 中提到过 docker 的使用方法和拉取镜像慢的问题:
$ docker run -idt \
-e POSTGRES_USER="postgres" \
-e POSTGRES_PASSWORD="password" \
-p 5432:5432 \
postgres:latest
本地还需要安装 psql,一个用于连接 postgres 数据库的命令:
$ brew cask install postgresql # Mac 上安装方法
$ yum install -y epel-release postgresql # CentOS 上安装方法
$ apt-get install postgresql # Ubuntu 上安装方法
确定能用下面的命令进入数据库,密码是 password:
$ psql -h 127.0.0.1 -U postgres
Password for user postgres:
psql (11.2, server 12.1 (Debian 12.1-1.pgdg100+1))
WARNING: psql major version 11, server major version 12.
Some psql features might not work.
Type "help" for help.
postgres=#
安装 nodejs
explorer 要求 nodejs 的版本不能太高,必须是 8.x 版本。
在 CentOS 上直接下载安装:
$ yum erase nodejs
$ wget https://nodejs.org/dist/v8.11.3/node-v8.11.3-linux-x64.tar.xz
$ tar -xvf node-v8.11.3-linux-x64.tar.xz
$ cd node-v8.11.3-linux-x64
$ cp -rf * /usr/
在 Mac 上用下面的方法安装 node 8.x:
$ brew install node@8
确保 node 的版本是 8.x,版本太高和太低都会出现奇葩问题!
$ node --version
v8.16.3 # 在 Mac 用 8.16.3 通过
特别注意:node 版本过高或过低,都会出现各种奇葩问题!
下载 blockchain-explorer 文件
把 blockchain-explorer 下载到 ~/hyperledger-fabric-1.4.4 目录中:
$ cd ~/hyperledger-fabric-1.4.4
$ git clone https://github.com/hyperledger/blockchain-explorer.git
这里使用的是 v0.3.9.5 版本,explorer 和 fabric 的版本适配情况见 blockchain-explorer release:
$ cd blockchain-explorer
$ git checkout -b v0.3.9.5 # v0.3.9.5 适配 fabric 1.4
核实配置文件 app/explorerconfig.json
核实配置文件 app/explorerconfig.json,确定里面的数据库用户名和密码是正确的:
{
"persistence": "postgreSQL",
"platforms": ["fabric"],
"postgreSQL": {
"host": "127.0.0.1",
"port": "5432",
"database": "fabricexplorer",
"username": "hppoc",
"passwd": "password"
},
"sync": {
"type": "local",
"platform": "fabric",
"blocksSyncTime": "3"
}
}
初始化 blockchain-explorer 使用的数据库
创建数据库:
$ cd app/persistence/fabric/postgreSQL/db
$ ./createdb.sh
我在 Mac 上运行时遇到下面错误:
$ ./createdb.sh
Copying ENV variables into temp file...
USER="hppoc"
DATABASE="fabricexplorer"
PASSWD='password'
Executing SQL scripts...
psql: could not connect to server: No such file or directory
Is the server running locally and accepting
connections on Unix domain socket "/tmp/.s.PGSQL.5432"?
psql: could not connect to server: No such file or directory
Is the server running locally and accepting
connections on Unix domain socket "/tmp/.s.PGSQL.5432"?
这是因为我的 postgre 是用 docker 启动的,访问时需要指定 IP 地址和用户,需要修改 createdb.sh。
在 Mac 上,把这两行:
darwin*) psql postgres -v dbname=$DATABASE -v user=$USER -v passwd=$PASSWD -f ./explorerpg.sql ;
psql postgres -v dbname=$DATABASE -v user=$USER -v passwd=$PASSWD -f ./updatepg.sql ;;
修改为:
darwin*) psql postgres -h 127.0.0.1 -U postgres -v dbname=$DATABASE -v user=$USER -v passwd=$PASSWD -f ./explorerpg.sql ;
psql postgres -h 127.0.0.1 -U postgres -v dbname=$DATABASE -v user=$USER -v passwd=$PASSWD -f ./updatepg.sql ;;
在 Linux 上修改方法类似,就是加上 -h 127.0.0.1 -U postgres,我没试验,使用 linux 系统的同学可以自己试一下:
linux*) psql postgres -h 127.0.0.1 -U postgres -v dbname=$DATABASE -v user=$USER -v passwd=$PASSWD -f ./explorerpg.sql ;
psql postgres -h 127.0.0.1 -U postgres -v dbname=$DATABASE -v user=$USER -v passwd=$PASSWD -f ./updatepg.sql ;;
修改后重新执行 ./createdb.sh, 这时候会提示输入的密码,密码就是前面用 docker 启动数据库时设置的 password。 输出的最后一行为下面的内容时,数据库初始化成功:
You are now connected to database "fabricexplorer" as user "postgres".
设置 fabric 对接文件
blockchain-explorer 中的 app/platform/fabric/config.json 是用来连接 fabric 的配置文件:
$ ls app/platform/fabric/config.json
app/platform/fabric/config.json
查看 config.json 文件的内容,你会发现这个文件中的配置针对的正好是 上一节 中创建的 first-network:
$ cat app/platform/fabric/config.json |grep peer
"peers": {
"peer0.org1.example.com": {}
"peer": {
"path": "/fabric-path/fabric-samples/first-network/crypto-config/peerOrganizations/org1.example.com/users/[email protected]/msp/keystore"
"path": "/fabric-path/fabric-samples/first-network/crypto-config/peerOrganizations/org1.example.com/users/[email protected]/msp/signcerts"
"path": "/fabric-path/fabric-samples/first-network/crypto-config/peerOrganizations/org2.example.com/users/[email protected]/msp/keystore"
"peers": {
"peer0.org1.example.com": {
"path": "/fabric-path/fabric-samples/first-network/crypto-config/peerOrganizations/org1.example.com/peers/peer0.org1.example.com/tls/ca.crt"
"ssl-target-name-override": "peer0.org1.example.com"
"peer1.org1.example.com": {
"peer0.org2.example.com": {
"peer1.org2.example.com": {
但是 config.json 中的文件路径为 “/fabric-path/fabric....",和这里的文件路径不同,需要全部修改为:
"path": "/Users/lijiao/hyperledger-fabric-1.4.4/fabric-samples/first-network/crypto-config/peerOrganizations/org1.example.com/users/[email protected]/msp/keystore"
必须使用绝对路径,路径不能是 ~,我这里是 /Users/lijiao,记得换成你自己的路径,下面的命令一次修改全部:
# Mac 上执行:
$ sed -i "" -e "s#/fabric-path#/Users/lijiao/hyperledger-fabric-1.4.4#" app/platform/fabric/config.json
# Linux 上执行:
$ sed -i -e "s#/fabric-path#/Users/lijiao/hyperledger-fabric-1.4.4#" app/platform/fabric/config.json
编译启动 blockchain-explorer
安装依赖包,构建 blockchain-explorer:
$ npm config set registry https://registry.npm.taobao.org # 添加淘宝镜像源,加快速度
$ cd blockchain-explorer
$ npm install
$ cd client # 进入 client 目录
$ npm install
$ npm run build
构建成功输出:

启动:
$ cd blockchain-explorer
$ node ./main.js
....显示信息...
write_set size >>>>>>>>> : 0.5014553070068359 MB
Insert sql is INSERT INTO transactions ( "blockid","txhash","createdt","chaincodename","chaincode_id","status","creator_msp_id","endorser_msp_id","type","read_set","write_set","channel_genesis_hash","validation_code","envelope_signature","payload_extension","creator_nonce","chaincode_proposal_input","endorser_signature","creator_id_bytes","payload_proposal_hash","endorser_id_bytes" ) VALUES( $1,$2,$3,$4,$5,$6,$7,$8,$9,$10,$11,$12,$13,$14,$15,$16,$17,$18,$19,$20,$21 ) RETURNING *;
... 省略 ...
监听地址在 appconfig.json 中配置,默认是 127.0.0.1:8080,在浏览器中打开:

遇到的一些错误
数据库密码不对
如果配置文件 app/explorerconfig.json 中数据库账号密码不对,node ./main.js 会报下面的错误:
postgres://hppoc:[email protected]:5432/fabricexplorer
error when connecting to db: { error: password authentication failed for user "hppoc"
at Connection.parseE (/Users/lijiao/hyperledger-fabric-1.4.4/blockchain-explorer/node_modules/pg/lib/connection.js:554:11)
at Connection.parseMessage (/Users/lijiao/hyperledger-fabric-1.4.4/blockchain-explorer/node_modules/pg/lib/connection.js:379:19)
at Socket.<anonymous> (/Users/lijiao/hyperledger-fabric-1.4.4/blockchain-explorer/node_modules/pg/lib/connection.js:119:22)
at emitOne (events.js:116:13)
at Socket.emit (events.js:211:7)
at addChunk (_stream_readable.js:263:12)
at readableAddChunk (_stream_readable.js:250:11)
at Socket.Readable.push (_stream_readable.js:208:10)
at TCP.onread (net.js:601:20)
exploer 优先从环境变量中获取数据库的账号密码,如果文件中的账号密码是正确的,但是环境变量中的不正确,也会报错,用下面命令清空环境变量:
unset DATABASE_HOST
unset DATABASE_PORT
unset DATABASE_DATABASE
unset DATABASE_USERNAME
unset DATABASE_PASSWD
Fabric 的对接文件配置错误
如果 app/platform/fabric/config.json 中的 path 路径配置错了,node ./main.js 打印下面的字符,然后自动退出:
**************************************************************************************
Error : Failed to connect client peer, please check the configuration and peer status
Info : Explorer will continue working with only DB data
**************************************************************************************
path 必须使用完整的绝对路径,不能用 ~/xxxxx,如下:
$ cat app/platform/fabric/config.json |grep path
"path": "./tmp/credentialStore_Org1/credential",
"path": "./tmp/credentialStore_Org1/crypto"
"fullpath": false,
"path": "/Users/lijiao/hyperledger-fabric-1.4.4/fabric-samples/first-network/crypto-config/peerOrganizations/org1.example.com/users/[email protected]/msp/keystore"
"path": "/Users/lijiao/hyperledger-fabric-1.4.4/fabric-samples/first-network/crypto-config/peerOrganizations/org1.example.com/users/[email protected]/msp/signcerts"
"path": "/Users/lijiao/hyperledger-fabric-1.4.4/fabric-samples/first-network/crypto-config/peerOrganizations/org2.example.com/users/[email protected]/msp/keystore"
"path": "/Users/lijiao/hyperledger-fabric-1.4.4/fabric-samples/first-network/crypto-config/ordererOrganizations/example.com/users/[email protected]/msp/keystore"
"path": "/Users/lijiao/hyperledger-fabric-1.4.4/fabric-samples/first-network/crypto-config/peerOrganizations/org1.example.com/peers/peer0.org1.example.com/tls/ca.crt"
参考
HyperLedger Fabric 的后续安排
接下来要详细说明 Fabric 每一个组件的用法,Fabric 系统的用法,如何创建、执行合约之类的,以及 HyperLedger 旗下其它项目的使用,譬如 Cello...... 工作量有点大,近期的主要精力要放到工作上正在用的 Kubernetes 和准备用的 Istio,HyperLedger 的后续跟进比较窘迫......
检视了一下之前的教程和笔记,核心逻辑还是对,虽然使用的是 Fabric 1.1 和 Fabric 1.2,但不妨碍对 Fabric 组件和运作方式的理解。笔记已经很详细,网易云课堂上的视频可用可不用。
掌握一个系统,最好的方法就是自己折腾,下面这些笔记和视频都是辅助,我会尽力把最新的内容更新到这本「小鸟笔记」中(2019-11-27 08:57:51)。
视频演示:
- 【视频】Fabric的全手动、多服务器部署教程
- 【视频】使用Ansible进行Fabric多节点分布式部署(实战)
- 【视频】Fabric从1.1.0升级到1.2.0
- 【视频】Fabric使用kafka进行区块排序(共识)
- 【视频】为Fabric的Peer节点配置CouchDB
- 【视频】Fabric-CA的使用演示(两个组织一个Orderer三个Peer)
- 【视频】Fabric的Chaincode(智能合约、链码)开发、使用演示
- 【视频】Fabric Go SDK的使用
- 【视频】Fabric nodejs SDK的使用
- 【视频】Fabric进阶,在已有的Channel中添加新的组织
- 【视频】超级账本HyperLedger:Fabric源码走读(零):源代码阅读环境准备
文字介绍:
- 超级账本工作组旗下项目介绍
- Fabric掰开揉碎,一文解惑
- Fabric的基本概念与基础用法
- FabricCA的基本概念与用法讲解
- FabricCA的级联使用(InterMediateCA)
- Fabric Chaincode(智能合约、链码)开发方法
- Fabric Channel配置的读取转换
- Explorer安装使用
- Cello部署和使用
问题汇总:
- Fabric部署过程时遇到的问题汇总
- Fabric的Chaincode开发过程中遇到的问题
- Fabric Node.js SDK使用时遇到的问题
- Fabric Golang SDK使用时遇到的问题
- Fabric 1.2.0使用时遇到的问题
更多文章: